 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeValue function estimation using conditional diffusion models for control
Paper and Code
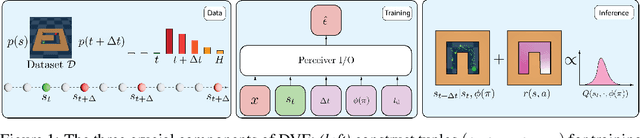

A fairly reliable trend in deep reinforcement learning is that the performance scales with the number of parameters, provided a complimentary scaling in amount of training data. As the appetite for large models increases, it is imperative to address, sooner than later, the potential problem of running out of high-quality demonstrations. In this case, instead of collecting only new data via costly human demonstrations or risking a simulation-to-real transfer with uncertain effects, it would be beneficial to leverage vast amounts of readily-available low-quality data. Since classical control algorithms such as behavior cloning or temporal difference learning cannot be used on reward-free or action-free data out-of-the-box, this solution warrants novel training paradigms for continuous control. We propose a simple algorithm called Diffused Value Function (DVF), which learns a joint multi-step model of the environment-robot interaction dynamics using a diffusion model. This model can be efficiently learned from state sequences (i.e., without access to reward functions nor actions), and subsequently used to estimate the value of each action out-of-the-box. We show how DVF can be used to efficiently capture the state visitation measure for multiple controllers, and show promising qualitative and quantitative results on challenging robotics benchmarks.