 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEMOTION: Expressive Motion Sequence Generation for Humanoid Robots with In-Context Learning
Oct 30, 2024



This paper introduces a framework, called EMOTION, for generating expressive motion sequences in humanoid robots, enhancing their ability to engage in humanlike non-verbal communication. Non-verbal cues such as facial expressions, gestures, and body movements play a crucial role in effective interpersonal interactions. Despite the advancements in robotic behaviors, existing methods often fall short in mimicking the diversity and subtlety of human non-verbal communication. To address this gap, our approach leverages the in-context learning capability of large language models (LLMs) to dynamically generate socially appropriate gesture motion sequences for human-robot interaction. We use this framework to generate 10 different expressive gestures and conduct online user studies comparing the naturalness and understandability of the motions generated by EMOTION and its human-feedback version, EMOTION++, against those by human operators. The results demonstrate that our approach either matches or surpasses human performance in generating understandable and natural robot motions under certain scenarios. We also provide design implications for future research to consider a set of variables when generating expressive robotic gestures.
Local Policies Enable Zero-shot Long-horizon Manipulation
Oct 29, 2024Sim2real for robotic manipulation is difficult due to the challenges of simulating complex contacts and generating realistic task distributions. To tackle the latter problem, we introduce ManipGen, which leverages a new class of policies for sim2real transfer: local policies. Locality enables a variety of appealing properties including invariances to absolute robot and object pose, skill ordering, and global scene configuration. We combine these policies with foundation models for vision, language and motion planning and demonstrate SOTA zero-shot performance of our method to Robosuite benchmark tasks in simulation (97%). We transfer our local policies from simulation to reality and observe they can solve unseen long-horizon manipulation tasks with up to 8 stages with significant pose, object and scene configuration variation. ManipGen outperforms SOTA approaches such as SayCan, OpenVLA, LLMTrajGen and VoxPoser across 50 real-world manipulation tasks by 36%, 76%, 62% and 60% respectively. Video results at https://mihdalal.github.io/manipgen/
On the benefits of pixel-based hierarchical policies for task generalization
Jul 27, 2024



Reinforcement learning practitioners often avoid hierarchical policies, especially in image-based observation spaces. Typically, the single-task performance improvement over flat-policy counterparts does not justify the additional complexity associated with implementing a hierarchy. However, by introducing multiple decision-making levels, hierarchical policies can compose lower-level policies to more effectively generalize between tasks, highlighting the need for multi-task evaluations. We analyze the benefits of hierarchy through simulated multi-task robotic control experiments from pixels. Our results show that hierarchical policies trained with task conditioning can (1) increase performance on training tasks, (2) lead to improved reward and state-space generalizations in similar tasks, and (3) decrease the complexity of fine tuning required to solve novel tasks. Thus, we believe that hierarchical policies should be considered when building reinforcement learning architectures capable of generalizing between tasks.
Efficient Non-Parametric Uncertainty Quantification for Black-Box Large Language Models and Decision Planning
Feb 01, 2024Step-by-step decision planning with large language models (LLMs) is gaining attention in AI agent development. This paper focuses on decision planning with uncertainty estimation to address the hallucination problem in language models. Existing approaches are either white-box or computationally demanding, limiting use of black-box proprietary LLMs within budgets. The paper's first contribution is a non-parametric uncertainty quantification method for LLMs, efficiently estimating point-wise dependencies between input-decision on the fly with a single inference, without access to token logits. This estimator informs the statistical interpretation of decision trustworthiness. The second contribution outlines a systematic design for a decision-making agent, generating actions like ``turn on the bathroom light'' based on user prompts such as ``take a bath''. Users will be asked to provide preferences when more than one action has high estimated point-wise dependencies. In conclusion, our uncertainty estimation and decision-making agent design offer a cost-efficient approach for AI agent development.
Large Language Models as Generalizable Policies for Embodied Tasks
Oct 26, 2023
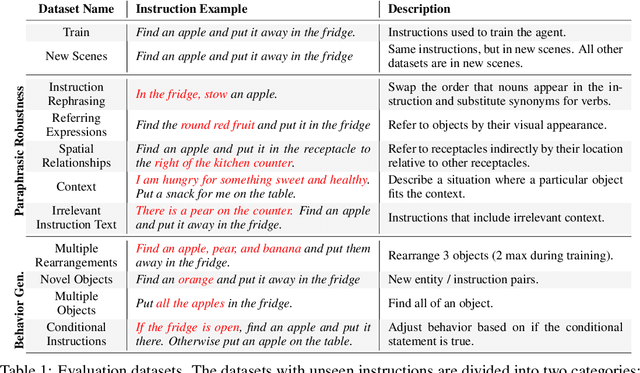
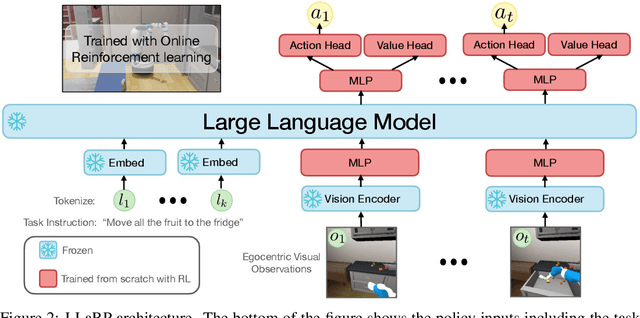
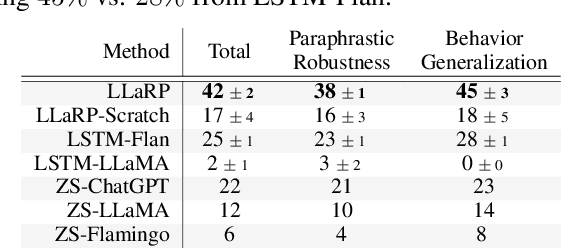
We show that large language models (LLMs) can be adapted to be generalizable policies for embodied visual tasks. Our approach, called Large LAnguage model Reinforcement Learning Policy (LLaRP), adapts a pre-trained frozen LLM to take as input text instructions and visual egocentric observations and output actions directly in the environment. Using reinforcement learning, we train LLaRP to see and act solely through environmental interactions. We show that LLaRP is robust to complex paraphrasings of task instructions and can generalize to new tasks that require novel optimal behavior. In particular, on 1,000 unseen tasks it achieves 42% success rate, 1.7x the success rate of other common learned baselines or zero-shot applications of LLMs. Finally, to aid the community in studying language conditioned, massively multi-task, embodied AI problems we release a novel benchmark, Language Rearrangement, consisting of 150,000 training and 1,000 testing tasks for language-conditioned rearrangement. Video examples of LLaRP in unseen Language Rearrangement instructions are at https://llm-rl.github.io.
Value function estimation using conditional diffusion models for control
Jun 09, 2023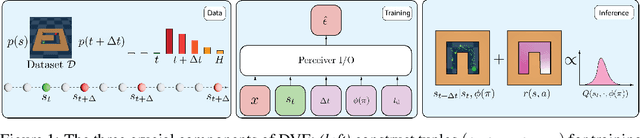

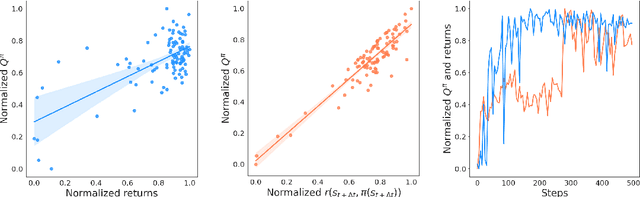
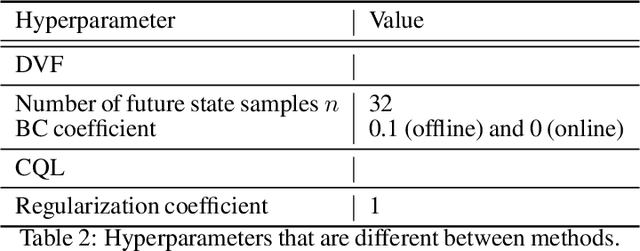
A fairly reliable trend in deep reinforcement learning is that the performance scales with the number of parameters, provided a complimentary scaling in amount of training data. As the appetite for large models increases, it is imperative to address, sooner than later, the potential problem of running out of high-quality demonstrations. In this case, instead of collecting only new data via costly human demonstrations or risking a simulation-to-real transfer with uncertain effects, it would be beneficial to leverage vast amounts of readily-available low-quality data. Since classical control algorithms such as behavior cloning or temporal difference learning cannot be used on reward-free or action-free data out-of-the-box, this solution warrants novel training paradigms for continuous control. We propose a simple algorithm called Diffused Value Function (DVF), which learns a joint multi-step model of the environment-robot interaction dynamics using a diffusion model. This model can be efficiently learned from state sequences (i.e., without access to reward functions nor actions), and subsequently used to estimate the value of each action out-of-the-box. We show how DVF can be used to efficiently capture the state visitation measure for multiple controllers, and show promising qualitative and quantitative results on challenging robotics benchmarks.
TRACT: Denoising Diffusion Models with Transitive Closure Time-Distillation
Mar 07, 2023



Denoising Diffusion models have demonstrated their proficiency for generative sampling. However, generating good samples often requires many iterations. Consequently, techniques such as binary time-distillation (BTD) have been proposed to reduce the number of network calls for a fixed architecture. In this paper, we introduce TRAnsitive Closure Time-distillation (TRACT), a new method that extends BTD. For single step diffusion,TRACT improves FID by up to 2.4x on the same architecture, and achieves new single-step Denoising Diffusion Implicit Models (DDIM) state-of-the-art FID (7.4 for ImageNet64, 3.8 for CIFAR10). Finally we tease apart the method through extended ablations. The PyTorch implementation will be released soon.
GAUDI: A Neural Architect for Immersive 3D Scene Generation
Jul 27, 2022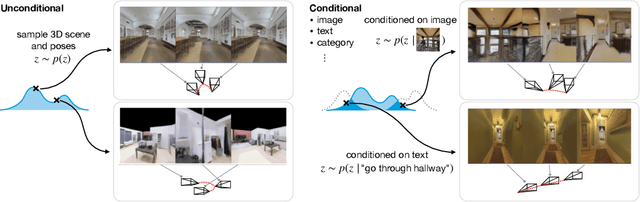
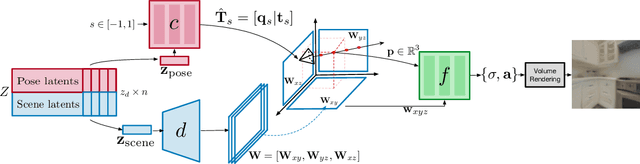

We introduce GAUDI, a generative model capable of capturing the distribution of complex and realistic 3D scenes that can be rendered immersively from a moving camera. We tackle this challenging problem with a scalable yet powerful approach, where we first optimize a latent representation that disentangles radiance fields and camera poses. This latent representation is then used to learn a generative model that enables both unconditional and conditional generation of 3D scenes. Our model generalizes previous works that focus on single objects by removing the assumption that the camera pose distribution can be shared across samples. We show that GAUDI obtains state-of-the-art performance in the unconditional generative setting across multiple datasets and allows for conditional generation of 3D scenes given conditioning variables like sparse image observations or text that describes the scene.
Position Prediction as an Effective Pretraining Strategy
Jul 15, 2022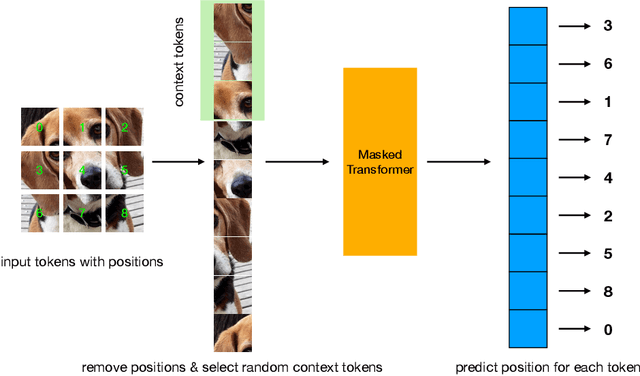


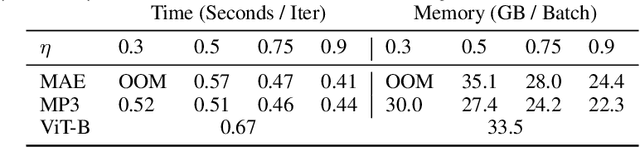
Transformers have gained increasing popularity in a wide range of applications, including Natural Language Processing (NLP), Computer Vision and Speech Recognition, because of their powerful representational capacity. However, harnessing this representational capacity effectively requires a large amount of data, strong regularization, or both, to mitigate overfitting. Recently, the power of the Transformer has been unlocked by self-supervised pretraining strategies based on masked autoencoders which rely on reconstructing masked inputs, directly, or contrastively from unmasked content. This pretraining strategy which has been used in BERT models in NLP, Wav2Vec models in Speech and, recently, in MAE models in Vision, forces the model to learn about relationships between the content in different parts of the input using autoencoding related objectives. In this paper, we propose a novel, but surprisingly simple alternative to content reconstruction~-- that of predicting locations from content, without providing positional information for it. Doing so requires the Transformer to understand the positional relationships between different parts of the input, from their content alone. This amounts to an efficient implementation where the pretext task is a classification problem among all possible positions for each input token. We experiment on both Vision and Speech benchmarks, where our approach brings improvements over strong supervised training baselines and is comparable to modern unsupervised/self-supervised pretraining methods. Our method also enables Transformers trained without position embeddings to outperform ones trained with full position information.
Efficient Representation Learning via Adaptive Context Pooling
Jul 05, 2022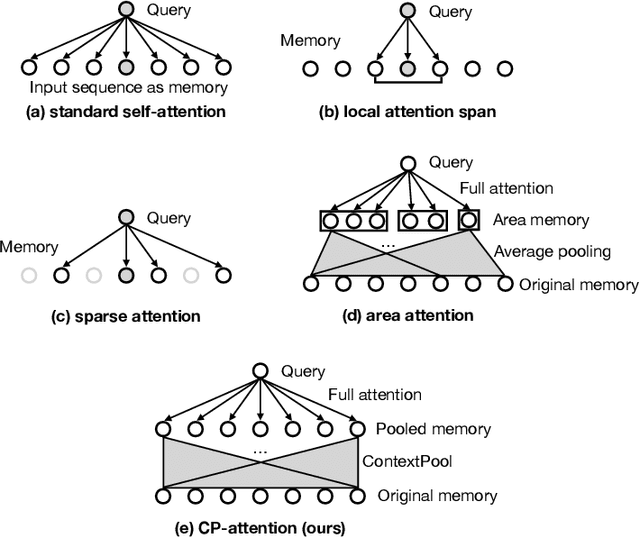
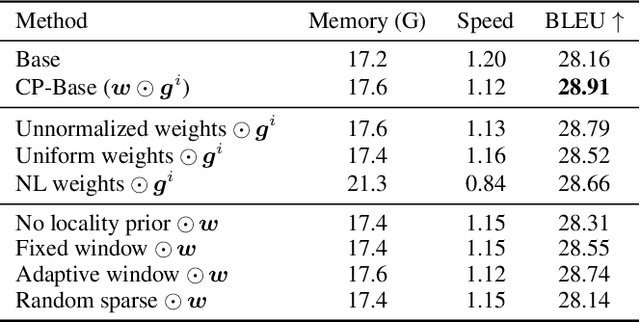
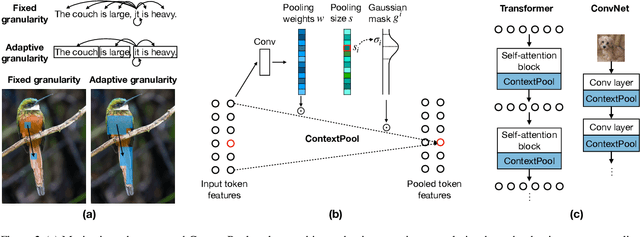
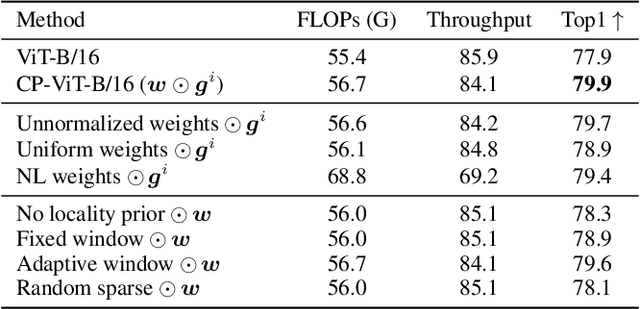
Self-attention mechanisms model long-range context by using pairwise attention between all input tokens. In doing so, they assume a fixed attention granularity defined by the individual tokens (e.g., text characters or image pixels), which may not be optimal for modeling complex dependencies at higher levels. In this paper, we propose ContextPool to address this problem by adapting the attention granularity for each token. Inspired by the success of ConvNets that are combined with pooling to capture long-range dependencies, we learn to pool neighboring features for each token before computing attention in a given attention layer. The pooling weights and support size are adaptively determined, allowing the pooled features to encode meaningful context with varying scale. We show that ContextPool makes attention models more expressive, achieving strong performance often with fewer layers and thus significantly reduced cost. Experiments validate that our ContextPool module, when plugged into transformer models, matches or surpasses state-of-the-art performance using less compute on several language and image benchmarks, outperforms recent works with learned context sizes or sparse attention patterns, and is also applicable to ConvNets for efficient feature learning.