 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUnlocking Generalization for Robotics via Modularity and Scale
Mar 10, 2025How can we build generalist robot systems? Scale may not be enough due to the significant multimodality of robotics tasks, lack of easily accessible data and the challenges of deploying on physical hardware. Meanwhile, most deployed robotic systems today are inherently modular and can leverage the independent generalization capabilities of each module to perform well. Therefore, this thesis seeks to tackle the task of building generalist robot agents by integrating these components into one: combining modularity with large-scale learning for general purpose robot control. The first question we consider is: how can we build modularity and hierarchy into learning systems? Our key insight is that rather than having the agent learn hierarchy and low-level control end-to-end, we can enforce modularity via planning to enable more efficient and capable robot learners. Next, we come to the role of scale in building generalist robot systems. To scale, neural networks require vast amounts of diverse data, expressive architectures to fit the data and a source of supervision to generate the data. We leverage a powerful supervision source: classical planning, which can generalize, but is expensive to run and requires access to privileged information to perform well in practice. We use these planners to supervise large-scale policy learning in simulation to produce generalist agents. Finally, we consider how to unify modularity with large-scale policy learning to build real-world robot systems capable of performing zero-shot manipulation. We do so by tightly integrating key ingredients of modular high and mid-level planning, learned local control, procedural scene generation and large-scale policy learning for sim2real transfer. We demonstrate that this recipe can produce a single, generalist agent that can solve challenging long-horizon manipulation tasks in the real world.
Local Policies Enable Zero-shot Long-horizon Manipulation
Oct 29, 2024Sim2real for robotic manipulation is difficult due to the challenges of simulating complex contacts and generating realistic task distributions. To tackle the latter problem, we introduce ManipGen, which leverages a new class of policies for sim2real transfer: local policies. Locality enables a variety of appealing properties including invariances to absolute robot and object pose, skill ordering, and global scene configuration. We combine these policies with foundation models for vision, language and motion planning and demonstrate SOTA zero-shot performance of our method to Robosuite benchmark tasks in simulation (97%). We transfer our local policies from simulation to reality and observe they can solve unseen long-horizon manipulation tasks with up to 8 stages with significant pose, object and scene configuration variation. ManipGen outperforms SOTA approaches such as SayCan, OpenVLA, LLMTrajGen and VoxPoser across 50 real-world manipulation tasks by 36%, 76%, 62% and 60% respectively. Video results at https://mihdalal.github.io/manipgen/
Neural MP: A Generalist Neural Motion Planner
Sep 09, 2024The current paradigm for motion planning generates solutions from scratch for every new problem, which consumes significant amounts of time and computational resources. For complex, cluttered scenes, motion planning approaches can often take minutes to produce a solution, while humans are able to accurately and safely reach any goal in seconds by leveraging their prior experience. We seek to do the same by applying data-driven learning at scale to the problem of motion planning. Our approach builds a large number of complex scenes in simulation, collects expert data from a motion planner, then distills it into a reactive generalist policy. We then combine this with lightweight optimization to obtain a safe path for real world deployment. We perform a thorough evaluation of our method on 64 motion planning tasks across four diverse environments with randomized poses, scenes and obstacles, in the real world, demonstrating an improvement of 23%, 17% and 79% motion planning success rate over state of the art sampling, optimization and learning based planning methods. Video results available at mihdalal.github.io/neuralmotionplanner
Plan-Seq-Learn: Language Model Guided RL for Solving Long Horizon Robotics Tasks
May 02, 2024Large Language Models (LLMs) have been shown to be capable of performing high-level planning for long-horizon robotics tasks, yet existing methods require access to a pre-defined skill library (e.g. picking, placing, pulling, pushing, navigating). However, LLM planning does not address how to design or learn those behaviors, which remains challenging particularly in long-horizon settings. Furthermore, for many tasks of interest, the robot needs to be able to adjust its behavior in a fine-grained manner, requiring the agent to be capable of modifying low-level control actions. Can we instead use the internet-scale knowledge from LLMs for high-level policies, guiding reinforcement learning (RL) policies to efficiently solve robotic control tasks online without requiring a pre-determined set of skills? In this paper, we propose Plan-Seq-Learn (PSL): a modular approach that uses motion planning to bridge the gap between abstract language and learned low-level control for solving long-horizon robotics tasks from scratch. We demonstrate that PSL achieves state-of-the-art results on over 25 challenging robotics tasks with up to 10 stages. PSL solves long-horizon tasks from raw visual input spanning four benchmarks at success rates of over 85%, out-performing language-based, classical, and end-to-end approaches. Video results and code at https://mihdalal.github.io/planseqlearn/
Imitating Task and Motion Planning with Visuomotor Transformers
May 25, 2023Imitation learning is a powerful tool for training robot manipulation policies, allowing them to learn from expert demonstrations without manual programming or trial-and-error. However, common methods of data collection, such as human supervision, scale poorly, as they are time-consuming and labor-intensive. In contrast, Task and Motion Planning (TAMP) can autonomously generate large-scale datasets of diverse demonstrations. In this work, we show that the combination of large-scale datasets generated by TAMP supervisors and flexible Transformer models to fit them is a powerful paradigm for robot manipulation. To that end, we present a novel imitation learning system called OPTIMUS that trains large-scale visuomotor Transformer policies by imitating a TAMP agent. OPTIMUS introduces a pipeline for generating TAMP data that is specifically curated for imitation learning and can be used to train performant transformer-based policies. In this paper, we present a thorough study of the design decisions required to imitate TAMP and demonstrate that OPTIMUS can solve a wide variety of challenging vision-based manipulation tasks with over 70 different objects, ranging from long-horizon pick-and-place tasks, to shelf and articulated object manipulation, achieving 70 to 80% success rates. Video results at https://mihdalal.github.io/optimus/
SEAL: Self-supervised Embodied Active Learning using Exploration and 3D Consistency
Dec 02, 2021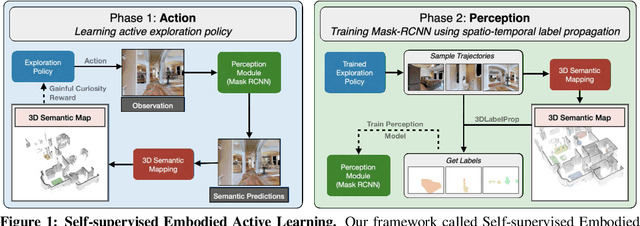
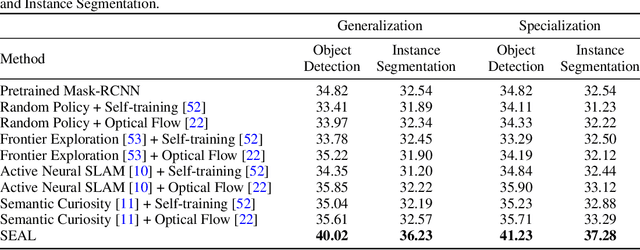
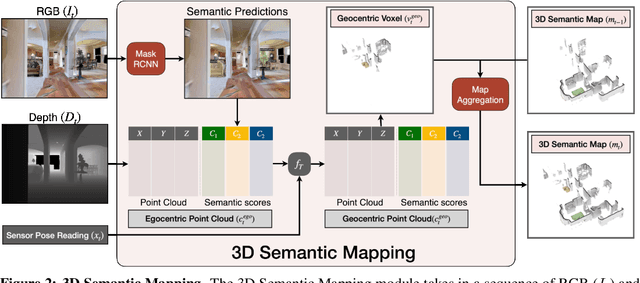

In this paper, we explore how we can build upon the data and models of Internet images and use them to adapt to robot vision without requiring any extra labels. We present a framework called Self-supervised Embodied Active Learning (SEAL). It utilizes perception models trained on internet images to learn an active exploration policy. The observations gathered by this exploration policy are labelled using 3D consistency and used to improve the perception model. We build and utilize 3D semantic maps to learn both action and perception in a completely self-supervised manner. The semantic map is used to compute an intrinsic motivation reward for training the exploration policy and for labelling the agent observations using spatio-temporal 3D consistency and label propagation. We demonstrate that the SEAL framework can be used to close the action-perception loop: it improves object detection and instance segmentation performance of a pretrained perception model by just moving around in training environments and the improved perception model can be used to improve Object Goal Navigation.
Accelerating Robotic Reinforcement Learning via Parameterized Action Primitives
Oct 28, 2021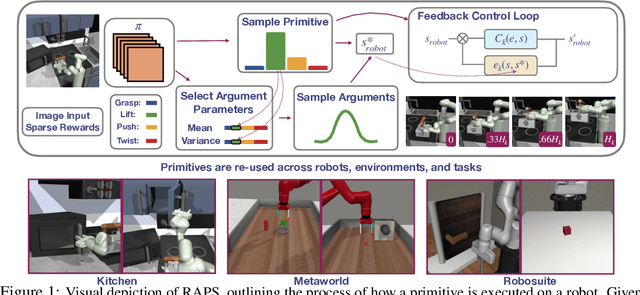


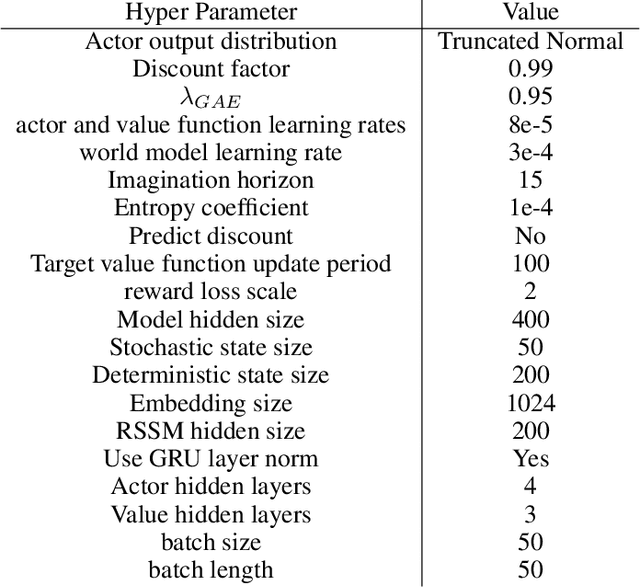
Despite the potential of reinforcement learning (RL) for building general-purpose robotic systems, training RL agents to solve robotics tasks still remains challenging due to the difficulty of exploration in purely continuous action spaces. Addressing this problem is an active area of research with the majority of focus on improving RL methods via better optimization or more efficient exploration. An alternate but important component to consider improving is the interface of the RL algorithm with the robot. In this work, we manually specify a library of robot action primitives (RAPS), parameterized with arguments that are learned by an RL policy. These parameterized primitives are expressive, simple to implement, enable efficient exploration and can be transferred across robots, tasks and environments. We perform a thorough empirical study across challenging tasks in three distinct domains with image input and a sparse terminal reward. We find that our simple change to the action interface substantially improves both the learning efficiency and task performance irrespective of the underlying RL algorithm, significantly outperforming prior methods which learn skills from offline expert data. Code and videos at https://mihdalal.github.io/raps/
Accelerating Online Reinforcement Learning with Offline Datasets
Jun 16, 2020
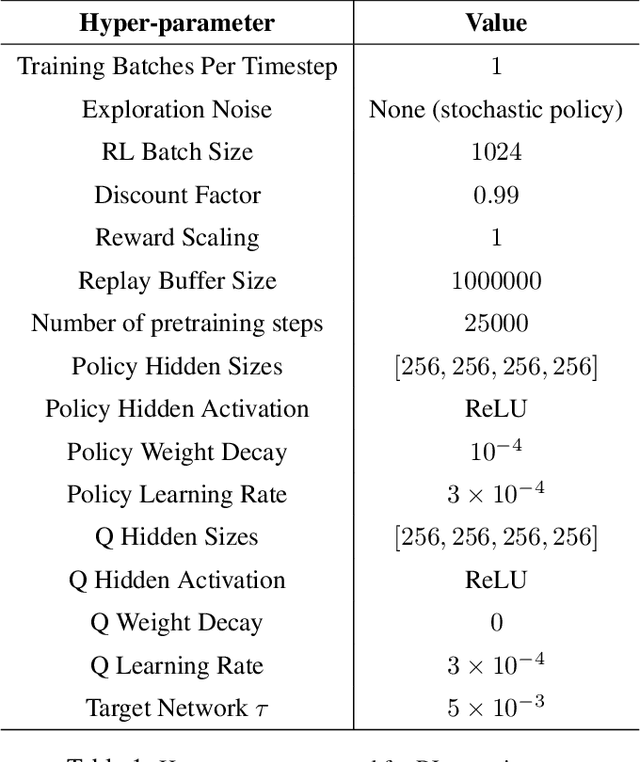

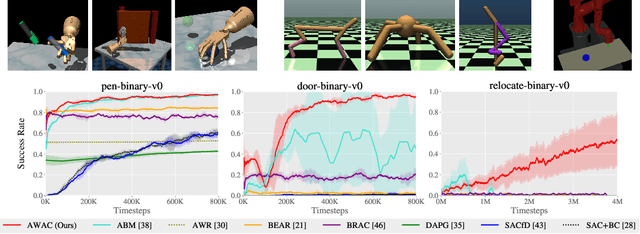
Reinforcement learning provides an appealing formalism for learning control policies from experience. However, the classic active formulation of reinforcement learning necessitates a lengthy active exploration process for each behavior, making it difficult to apply in real-world settings. If we can instead allow reinforcement learning to effectively use previously collected data to aid the online learning process, where the data could be expert demonstrations or more generally any prior experience, we could make reinforcement learning a substantially more practical tool. While a number of recent methods have sought to learn offline from previously collected data, it remains exceptionally difficult to train a policy with offline data and improve it further with online reinforcement learning. In this paper we systematically analyze why this problem is so challenging, and propose a novel algorithm that combines sample-efficient dynamic programming with maximum likelihood policy updates, providing a simple and effective framework that is able to leverage large amounts of offline data and then quickly perform online fine-tuning of reinforcement learning policies. We show that our method enables rapid learning of skills with a combination of prior demonstration data and online experience across a suite of difficult dexterous manipulation and benchmark tasks.
Scalable Multi-Task Imitation Learning with Autonomous Improvement
Feb 25, 2020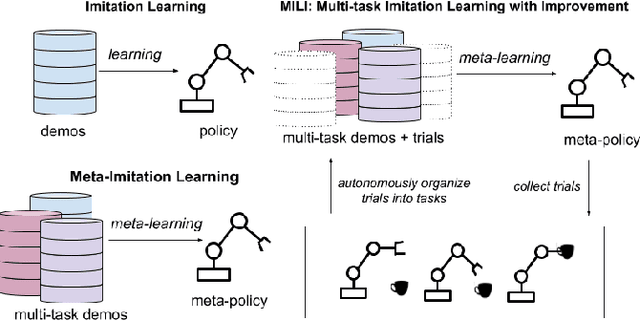

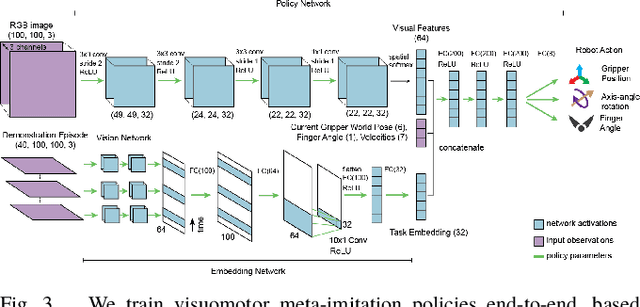

While robot learning has demonstrated promising results for enabling robots to automatically acquire new skills, a critical challenge in deploying learning-based systems is scale: acquiring enough data for the robot to effectively generalize broadly. Imitation learning, in particular, has remained a stable and powerful approach for robot learning, but critically relies on expert operators for data collection. In this work, we target this challenge, aiming to build an imitation learning system that can continuously improve through autonomous data collection, while simultaneously avoiding the explicit use of reinforcement learning, to maintain the stability, simplicity, and scalability of supervised imitation. To accomplish this, we cast the problem of imitation with autonomous improvement into a multi-task setting. We utilize the insight that, in a multi-task setting, a failed attempt at one task might represent a successful attempt at another task. This allows us to leverage the robot's own trials as demonstrations for tasks other than the one that the robot actually attempted. Using an initial dataset of multi-task demonstration data, the robot autonomously collects trials which are only sparsely labeled with a binary indication of whether the trial accomplished any useful task or not. We then embed the trials into a learned latent space of tasks, trained using only the initial demonstration dataset, to draw similarities between various trials, enabling the robot to achieve one-shot generalization to new tasks. In contrast to prior imitation learning approaches, our method can autonomously collect data with sparse supervision for continuous improvement, and in contrast to reinforcement learning algorithms, our method can effectively improve from sparse, task-agnostic reward signals.
Autoregressive Models: What Are They Good For?
Oct 17, 2019
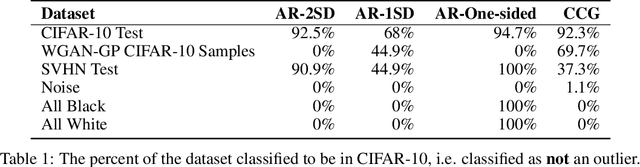


Autoregressive (AR) models have become a popular tool for unsupervised learning, achieving state-of-the-art log likelihood estimates. We investigate the use of AR models as density estimators in two settings -- as a learning signal for image translation, and as an outlier detector -- and find that these density estimates are much less reliable than previously thought. We examine the underlying optimization issues from both an empirical and theoretical perspective, and provide a toy example that illustrates the problem. Overwhelmingly, we find that density estimates do not correlate with perceptual quality and are unhelpful for downstream tasks.