 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
CoT-VLA: Visual Chain-of-Thought Reasoning for Vision-Language-Action Models
Mar 27, 2025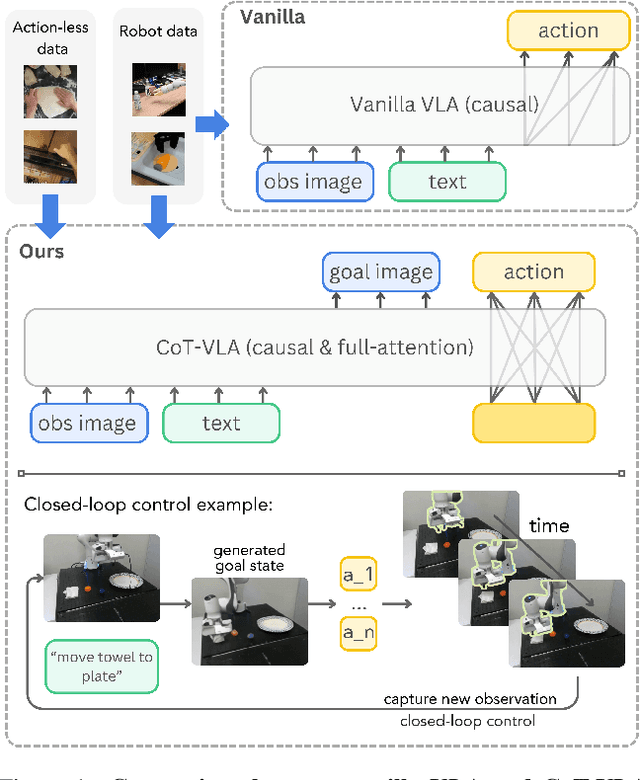

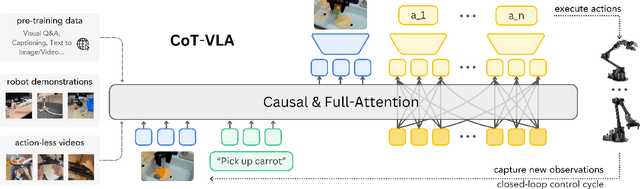
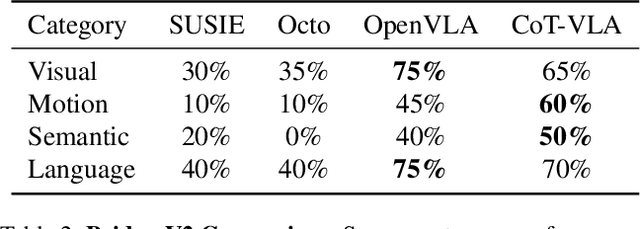
Vision-language-action models (VLAs) have shown potential in leveraging pretrained vision-language models and diverse robot demonstrations for learning generalizable sensorimotor control. While this paradigm effectively utilizes large-scale data from both robotic and non-robotic sources, current VLAs primarily focus on direct input--output mappings, lacking the intermediate reasoning steps crucial for complex manipulation tasks. As a result, existing VLAs lack temporal planning or reasoning capabilities. In this paper, we introduce a method that incorporates explicit visual chain-of-thought (CoT) reasoning into vision-language-action models (VLAs) by predicting future image frames autoregressively as visual goals before generating a short action sequence to achieve these goals. We introduce CoT-VLA, a state-of-the-art 7B VLA that can understand and generate visual and action tokens. Our experimental results demonstrate that CoT-VLA achieves strong performance, outperforming the state-of-the-art VLA model by 17% in real-world manipulation tasks and 6% in simulation benchmarks. Project website: https://cot-vla.github.io/
* Project website: https://cot-vla.github.io/
DextrAH-RGB: Visuomotor Policies to Grasp Anything with Dexterous Hands
Nov 27, 2024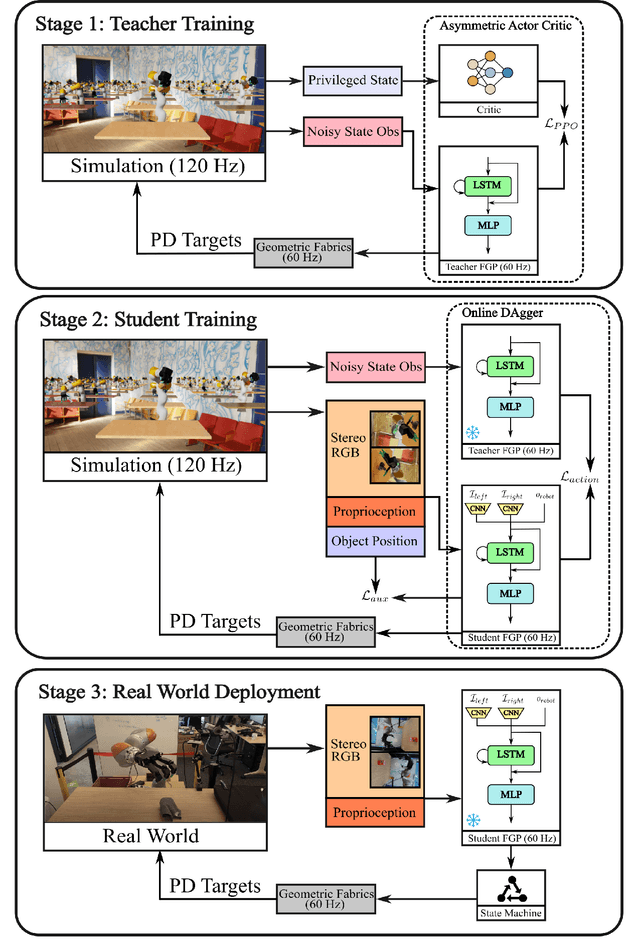



One of the most important yet challenging skills for a robot is the task of dexterous grasping of a diverse range of objects. Much of the prior work is limited by the speed, dexterity, or reliance on depth maps. In this paper, we introduce DextrAH-RGB, a system that can perform dexterous arm-hand grasping end2end from stereo RGB input. We train a teacher fabric-guided policy (FGP) in simulation through reinforcement learning that acts on a geometric fabric action space to ensure reactivity and safety. We then distill this teacher FGP into a stereo RGB-based student FGP in simulation. To our knowledge, this is the first work that is able to demonstrate robust sim2real transfer of an end2end RGB-based policy for complex, dynamic, contact-rich tasks such as dexterous grasping. Our policies are able to generalize grasping to novel objects with unseen geometry, texture, or lighting conditions during training. Videos of our system grasping a diverse range of unseen objects are available at \url{https://dextrah-rgb.github.io/}
Synthetica: Large Scale Synthetic Data for Robot Perception
Oct 28, 2024



Vision-based object detectors are a crucial basis for robotics applications as they provide valuable information about object localisation in the environment. These need to ensure high reliability in different lighting conditions, occlusions, and visual artifacts, all while running in real-time. Collecting and annotating real-world data for these networks is prohibitively time consuming and costly, especially for custom assets, such as industrial objects, making it untenable for generalization to in-the-wild scenarios. To this end, we present Synthetica, a method for large-scale synthetic data generation for training robust state estimators. This paper focuses on the task of object detection, an important problem which can serve as the front-end for most state estimation problems, such as pose estimation. Leveraging data from a photorealistic ray-tracing renderer, we scale up data generation, generating 2.7 million images, to train highly accurate real-time detection transformers. We present a collection of rendering randomization and training-time data augmentation techniques conducive to robust sim-to-real performance for vision tasks. We demonstrate state-of-the-art performance on the task of object detection while having detectors that run at 50-100Hz which is 9 times faster than the prior SOTA. We further demonstrate the usefulness of our training methodology for robotics applications by showcasing a pipeline for use in the real world with custom objects for which there do not exist prior datasets. Our work highlights the importance of scaling synthetic data generation for robust sim-to-real transfer while achieving the fastest real-time inference speeds. Videos and supplementary information can be found at this URL: https://sites.google.com/view/synthetica-vision.
FORGE: Force-Guided Exploration for Robust Contact-Rich Manipulation under Uncertainty
Aug 08, 2024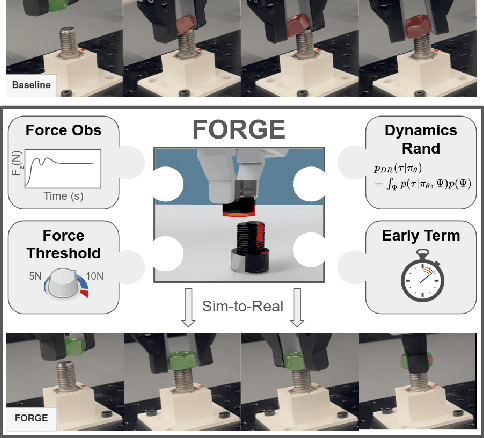

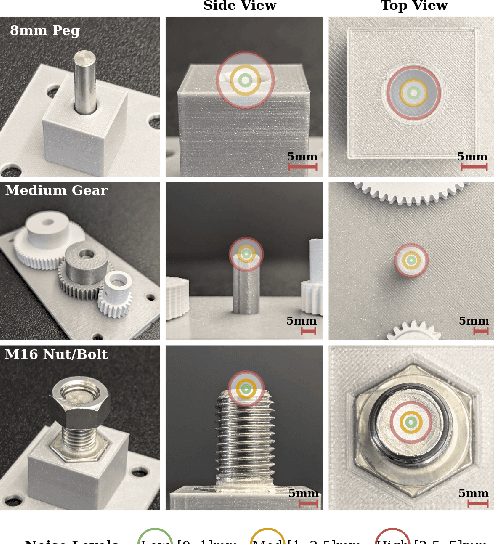
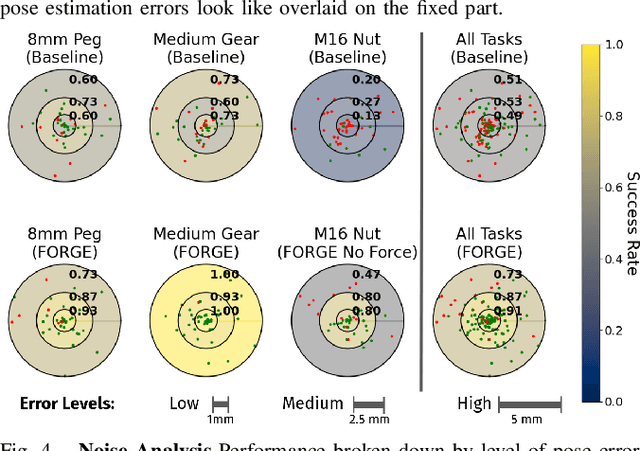
We present FORGE, a method that enables sim-to-real transfer of contact-rich manipulation policies in the presence of significant pose uncertainty. FORGE combines a force threshold mechanism with a dynamics randomization scheme during policy learning in simulation, to enable the robust transfer of the learned policies to the real robot. At deployment, FORGE policies, conditioned on a maximum allowable force, adaptively perform contact-rich tasks while respecting the specified force threshold, regardless of the controller gains. Additionally, FORGE autonomously predicts a termination action once the task has succeeded. We demonstrate that FORGE can be used to learn a variety of robust contact-rich policies, enabling multi-stage assembly of a planetary gear system, which requires success across three assembly tasks: nut-threading, insertion, and gear meshing. Project website can be accessed at https://noseworm.github.io/forge/.
AutoMate: Specialist and Generalist Assembly Policies over Diverse Geometries
Jul 10, 2024

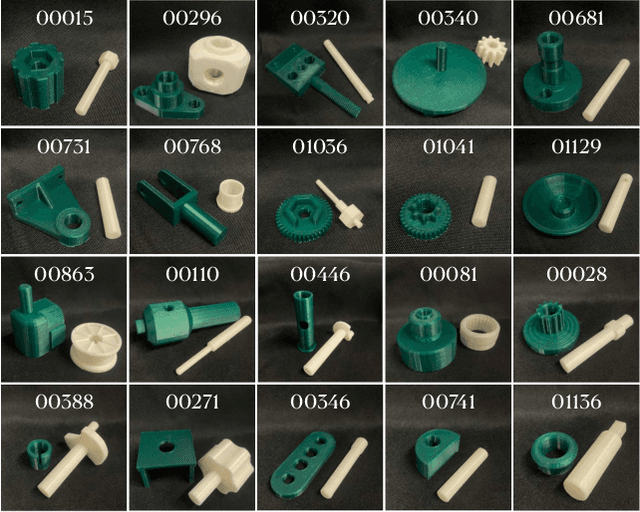

Robotic assembly for high-mixture settings requires adaptivity to diverse parts and poses, which is an open challenge. Meanwhile, in other areas of robotics, large models and sim-to-real have led to tremendous progress. Inspired by such work, we present AutoMate, a learning framework and system that consists of 4 parts: 1) a dataset of 100 assemblies compatible with simulation and the real world, along with parallelized simulation environments for policy learning, 2) a novel simulation-based approach for learning specialist (i.e., part-specific) policies and generalist (i.e., unified) assembly policies, 3) demonstrations of specialist policies that individually solve 80 assemblies with 80% or higher success rates in simulation, as well as a generalist policy that jointly solves 20 assemblies with an 80%+ success rate, and 4) zero-shot sim-to-real transfer that achieves similar (or better) performance than simulation, including on perception-initialized assembly. The key methodological takeaway is that a union of diverse algorithms from manufacturing engineering, character animation, and time-series analysis provides a generic and robust solution for a diverse range of robotic assembly problems.To our knowledge, AutoMate provides the first simulation-based framework for learning specialist and generalist policies over a wide range of assemblies, as well as the first system demonstrating zero-shot sim-to-real transfer over such a range.
DextrAH-G: Pixels-to-Action Dexterous Arm-Hand Grasping with Geometric Fabrics
Jul 02, 2024

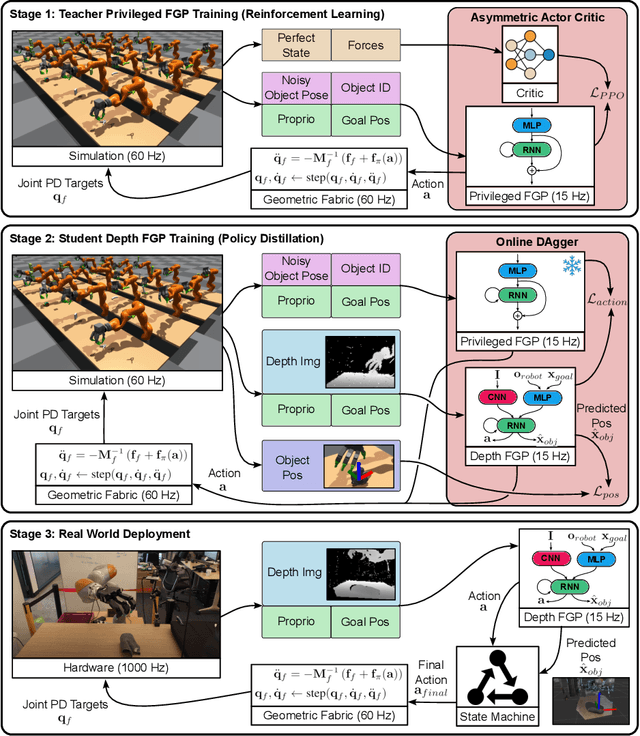
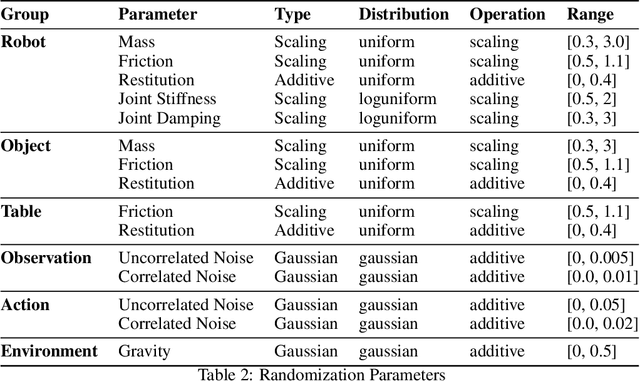
A pivotal challenge in robotics is achieving fast, safe, and robust dexterous grasping across a diverse range of objects, an important goal within industrial applications. However, existing methods often have very limited speed, dexterity, and generality, along with limited or no hardware safety guarantees. In this work, we introduce DextrAH-G, a depth-based dexterous grasping policy trained entirely in simulation that combines reinforcement learning, geometric fabrics, and teacher-student distillation. We address key challenges in joint arm-hand policy learning, such as high-dimensional observation and action spaces, the sim2real gap, collision avoidance, and hardware constraints. DextrAH-G enables a 23 motor arm-hand robot to safely and continuously grasp and transport a large variety of objects at high speed using multi-modal inputs including depth images, allowing generalization across object geometry. Videos at https://sites.google.com/view/dextrah-g.
Geometric Fabrics: a Safe Guiding Medium for Policy Learning
May 03, 2024


Robotics policies are always subjected to complex, second order dynamics that entangle their actions with resulting states. In reinforcement learning (RL) contexts, policies have the burden of deciphering these complicated interactions over massive amounts of experience and complex reward functions to learn how to accomplish tasks. Moreover, policies typically issue actions directly to controllers like Operational Space Control (OSC) or joint PD control, which induces straightline motion towards these action targets in task or joint space. However, straightline motion in these spaces for the most part do not capture the rich, nonlinear behavior our robots need to exhibit, shifting the burden of discovering these behaviors more completely to the agent. Unlike these simpler controllers, geometric fabrics capture a much richer and desirable set of behaviors via artificial, second order dynamics grounded in nonlinear geometry. These artificial dynamics shift the uncontrolled dynamics of a robot via an appropriate control law to form behavioral dynamics. Behavioral dynamics unlock a new action space and safe, guiding behavior over which RL policies are trained. Behavioral dynamics enable bang-bang-like RL policy actions that are still safe for real robots, simplify reward engineering, and help sequence real-world, high-performance policies. We describe the framework more generally and create a specific instantiation for the problem of dexterous, in-hand reorientation of a cube by a highly actuated robot hand.
Scaling Population-Based Reinforcement Learning with GPU Accelerated Simulation
Apr 08, 2024
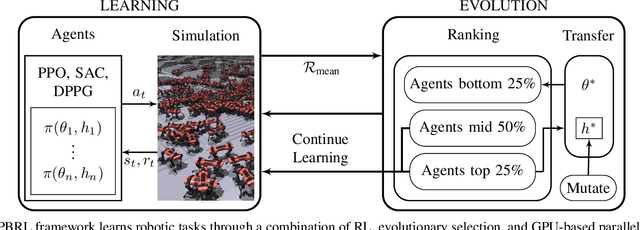
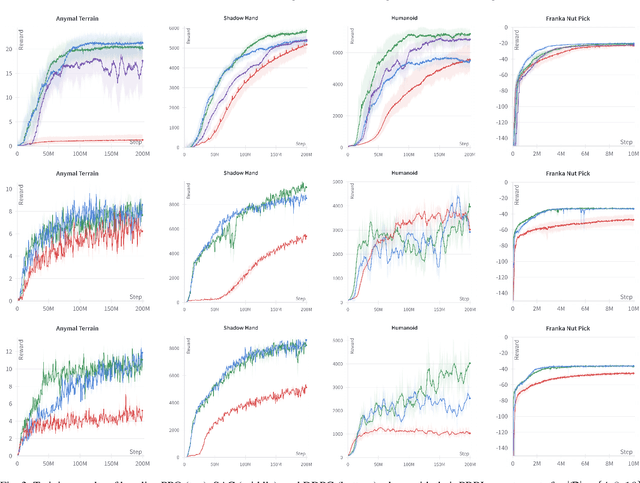
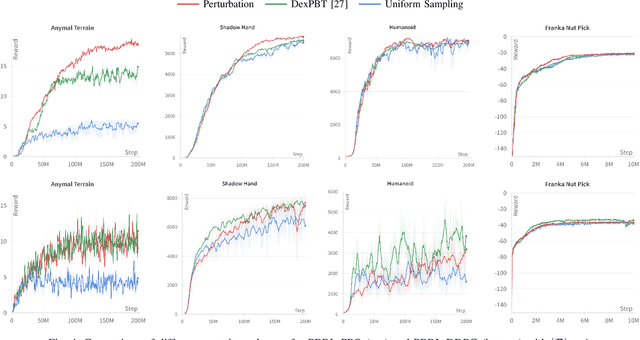
In recent years, deep reinforcement learning (RL) has shown its effectiveness in solving complex continuous control tasks like locomotion and dexterous manipulation. However, this comes at the cost of an enormous amount of experience required for training, exacerbated by the sensitivity of learning efficiency and the policy performance to hyperparameter selection, which often requires numerous trials of time-consuming experiments. This work introduces a Population-Based Reinforcement Learning (PBRL) approach that exploits a GPU-accelerated physics simulator to enhance the exploration capabilities of RL by concurrently training multiple policies in parallel. The PBRL framework is applied to three state-of-the-art RL algorithms -- PPO, SAC, and DDPG -- dynamically adjusting hyperparameters based on the performance of learning agents. The experiments are performed on four challenging tasks in Isaac Gym -- Anymal Terrain, Shadow Hand, Humanoid, Franka Nut Pick -- by analyzing the effect of population size and mutation mechanisms for hyperparameters. The results show that PBRL agents achieve superior performance, in terms of cumulative reward, compared to non-evolutionary baseline agents. The trained agents are finally deployed in the real world for a Franka Nut Pick task, demonstrating successful sim-to-real transfer. Code and videos of the learned policies are available on our project website.
cuRobo: Parallelized Collision-Free Minimum-Jerk Robot Motion Generation
Nov 03, 2023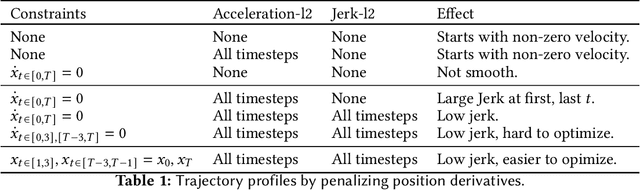
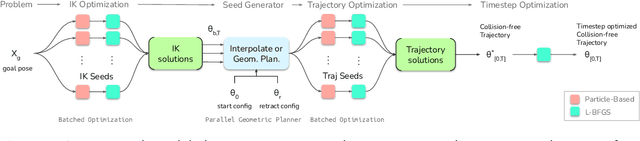
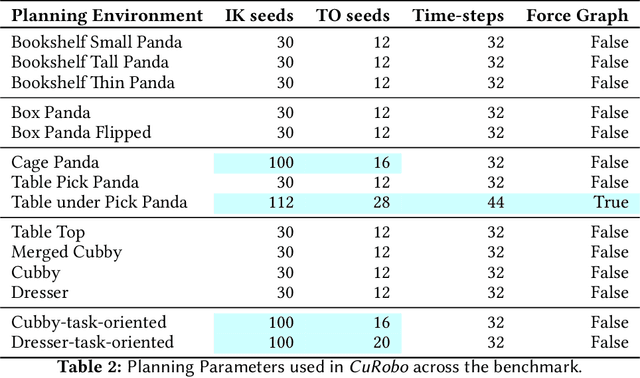
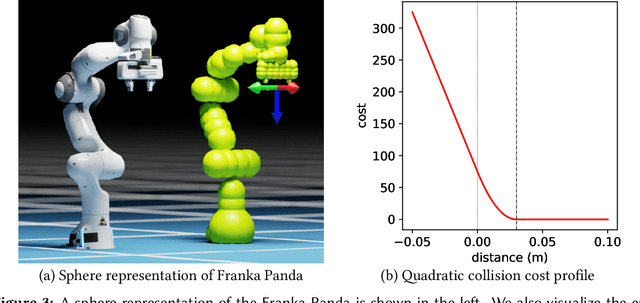
This paper explores the problem of collision-free motion generation for manipulators by formulating it as a global motion optimization problem. We develop a parallel optimization technique to solve this problem and demonstrate its effectiveness on massively parallel GPUs. We show that combining simple optimization techniques with many parallel seeds leads to solving difficult motion generation problems within 50ms on average, 60x faster than state-of-the-art (SOTA) trajectory optimization methods. We achieve SOTA performance by combining L-BFGS step direction estimation with a novel parallel noisy line search scheme and a particle-based optimization solver. To further aid trajectory optimization, we develop a parallel geometric planner that plans within 20ms and also introduce a collision-free IK solver that can solve over 7000 queries/s. We package our contributions into a state of the art GPU accelerated motion generation library, cuRobo and release it to enrich the robotics community. Additional details are available at https://curobo.org