 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIsaac Lab: A GPU-Accelerated Simulation Framework for Multi-Modal Robot Learning
Nov 06, 2025



We present Isaac Lab, the natural successor to Isaac Gym, which extends the paradigm of GPU-native robotics simulation into the era of large-scale multi-modal learning. Isaac Lab combines high-fidelity GPU parallel physics, photorealistic rendering, and a modular, composable architecture for designing environments and training robot policies. Beyond physics and rendering, the framework integrates actuator models, multi-frequency sensor simulation, data collection pipelines, and domain randomization tools, unifying best practices for reinforcement and imitation learning at scale within a single extensible platform. We highlight its application to a diverse set of challenges, including whole-body control, cross-embodiment mobility, contact-rich and dexterous manipulation, and the integration of human demonstrations for skill acquisition. Finally, we discuss upcoming integration with the differentiable, GPU-accelerated Newton physics engine, which promises new opportunities for scalable, data-efficient, and gradient-based approaches to robot learning. We believe Isaac Lab's combination of advanced simulation capabilities, rich sensing, and data-center scale execution will help unlock the next generation of breakthroughs in robotics research.
DextrAH-RGB: Visuomotor Policies to Grasp Anything with Dexterous Hands
Nov 27, 2024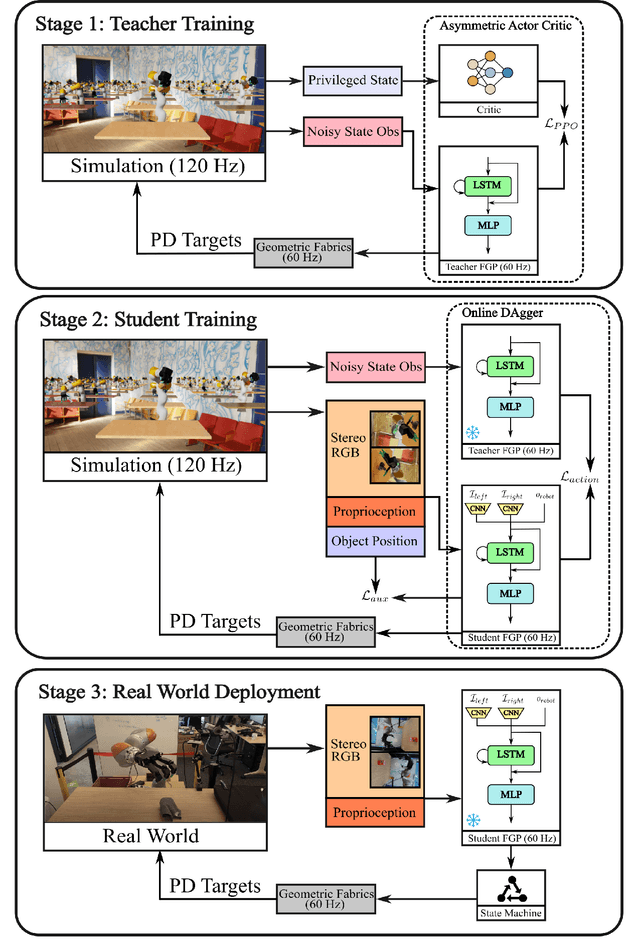



One of the most important yet challenging skills for a robot is the task of dexterous grasping of a diverse range of objects. Much of the prior work is limited by the speed, dexterity, or reliance on depth maps. In this paper, we introduce DextrAH-RGB, a system that can perform dexterous arm-hand grasping end2end from stereo RGB input. We train a teacher fabric-guided policy (FGP) in simulation through reinforcement learning that acts on a geometric fabric action space to ensure reactivity and safety. We then distill this teacher FGP into a stereo RGB-based student FGP in simulation. To our knowledge, this is the first work that is able to demonstrate robust sim2real transfer of an end2end RGB-based policy for complex, dynamic, contact-rich tasks such as dexterous grasping. Our policies are able to generalize grasping to novel objects with unseen geometry, texture, or lighting conditions during training. Videos of our system grasping a diverse range of unseen objects are available at \url{https://dextrah-rgb.github.io/}
Synthetica: Large Scale Synthetic Data for Robot Perception
Oct 28, 2024



Vision-based object detectors are a crucial basis for robotics applications as they provide valuable information about object localisation in the environment. These need to ensure high reliability in different lighting conditions, occlusions, and visual artifacts, all while running in real-time. Collecting and annotating real-world data for these networks is prohibitively time consuming and costly, especially for custom assets, such as industrial objects, making it untenable for generalization to in-the-wild scenarios. To this end, we present Synthetica, a method for large-scale synthetic data generation for training robust state estimators. This paper focuses on the task of object detection, an important problem which can serve as the front-end for most state estimation problems, such as pose estimation. Leveraging data from a photorealistic ray-tracing renderer, we scale up data generation, generating 2.7 million images, to train highly accurate real-time detection transformers. We present a collection of rendering randomization and training-time data augmentation techniques conducive to robust sim-to-real performance for vision tasks. We demonstrate state-of-the-art performance on the task of object detection while having detectors that run at 50-100Hz which is 9 times faster than the prior SOTA. We further demonstrate the usefulness of our training methodology for robotics applications by showcasing a pipeline for use in the real world with custom objects for which there do not exist prior datasets. Our work highlights the importance of scaling synthetic data generation for robust sim-to-real transfer while achieving the fastest real-time inference speeds. Videos and supplementary information can be found at this URL: https://sites.google.com/view/synthetica-vision.
cuRobo: Parallelized Collision-Free Minimum-Jerk Robot Motion Generation
Nov 03, 2023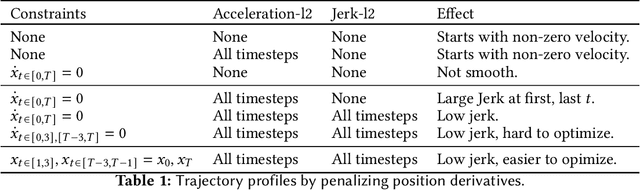
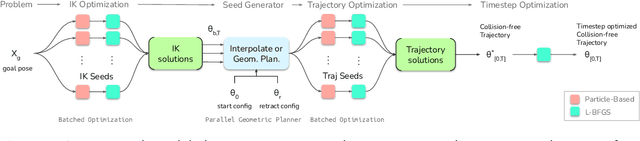
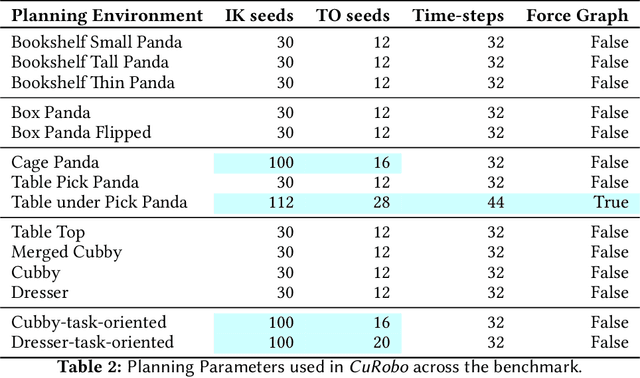
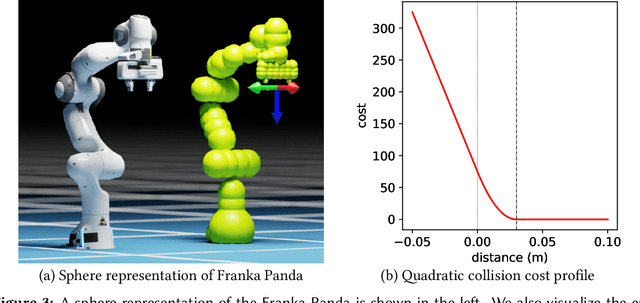
This paper explores the problem of collision-free motion generation for manipulators by formulating it as a global motion optimization problem. We develop a parallel optimization technique to solve this problem and demonstrate its effectiveness on massively parallel GPUs. We show that combining simple optimization techniques with many parallel seeds leads to solving difficult motion generation problems within 50ms on average, 60x faster than state-of-the-art (SOTA) trajectory optimization methods. We achieve SOTA performance by combining L-BFGS step direction estimation with a novel parallel noisy line search scheme and a particle-based optimization solver. To further aid trajectory optimization, we develop a parallel geometric planner that plans within 20ms and also introduce a collision-free IK solver that can solve over 7000 queries/s. We package our contributions into a state of the art GPU accelerated motion generation library, cuRobo and release it to enrich the robotics community. Additional details are available at https://curobo.org
Fabrics: A Foundationally Stable Medium for Encoding Prior Experience
Sep 14, 2023Most dynamics functions are not well-aligned to task requirements. Controllers, therefore, often invert the dynamics and reshape it into something more useful. The learning community has found that these controllers, such as Operational Space Control (OSC), can offer important inductive biases for training. However, OSC only captures straight line end-effector motion. There's a lot more behavior we could and should be packing into these systems. Earlier work [15][16][19] developed a theory that generalized these ideas and constructed a broad and flexible class of second-order dynamical systems which was simultaneously expressive enough to capture substantial behavior (such as that listed above), and maintained the types of stability properties that make OSC and controllers like it a good foundation for policy design and learning. This paper, motivated by the empirical success of the types of fabrics used in [20], reformulates the theory of fabrics into a form that's more general and easier to apply to policy learning problems. We focus on the stability properties that make fabrics a good foundation for policy synthesis. Fabrics create a fundamentally stable medium within which a policy can operate; they influence the system's behavior without preventing it from achieving tasks within its constraints. When a fabrics is geometric (path consistent) we can interpret the fabric as forming a road network of paths that the system wants to follow at constant speed absent a forcing policy, giving geometric intuition to its role as a prior. The policy operating over the geometric fabric acts to modulate speed and steers the system from one road to the next as it accomplishes its task. We reformulate the theory of fabrics here rigorously and develop theoretical results characterizing system behavior and illuminating how to design these systems, while also emphasizing intuition throughout.
CoDE: Collocation for Demonstration Encoding
May 07, 2021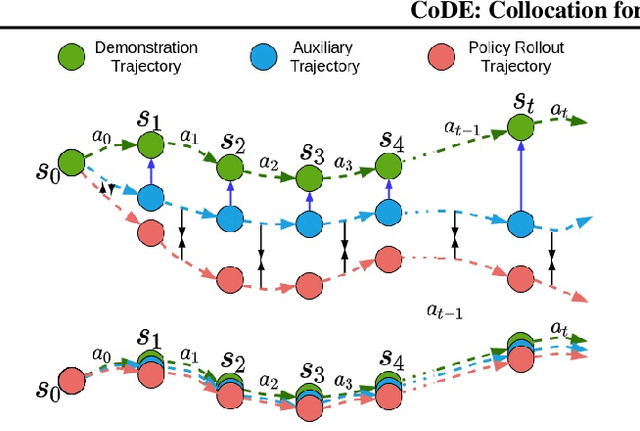
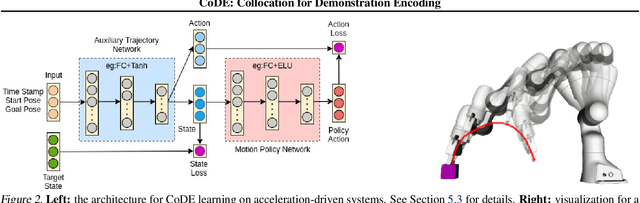
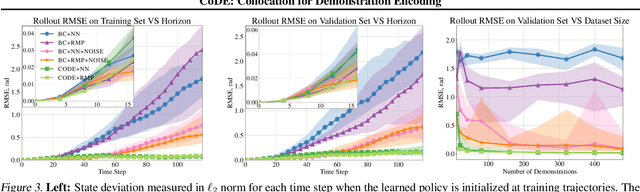
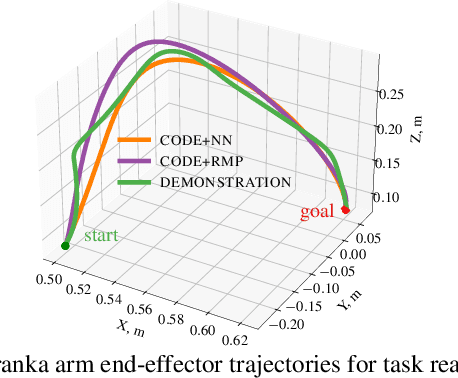
Roboticists frequently turn to Imitation learning (IL) for data efficient policy learning. Many IL methods, canonicalized by the seminal work on Dataset Aggregation (DAgger), combat distributional shift issues with older Behavior Cloning (BC) methods by introducing oracle experts. Unfortunately, access to oracle experts is often unrealistic in practice; data frequently comes from manual offline methods such as lead-through or teleoperation. We present a data-efficient imitation learning technique called Collocation for Demonstration Encoding (CoDE) that operates on only a fixed set of trajectory demonstrations by modeling learning as empirical risk minimization. We circumvent problematic back-propagation through time problems by introducing an auxiliary trajectory network taking inspiration from collocation techniques in optimal control. Our method generalizes well and is much more data efficient than standard BC methods. We present experiments on a 7-degree-of-freedom (DoF) robotic manipulator learning behavior shaping policies for efficient tabletop operation.
Fast Joint Space Model-Predictive Control for Reactive Manipulation
Apr 28, 2021
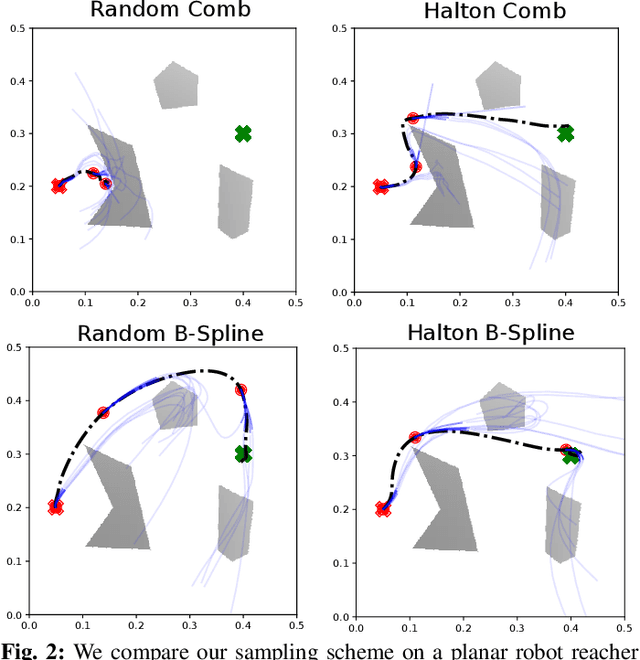
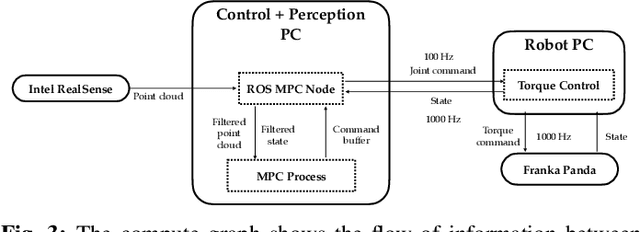
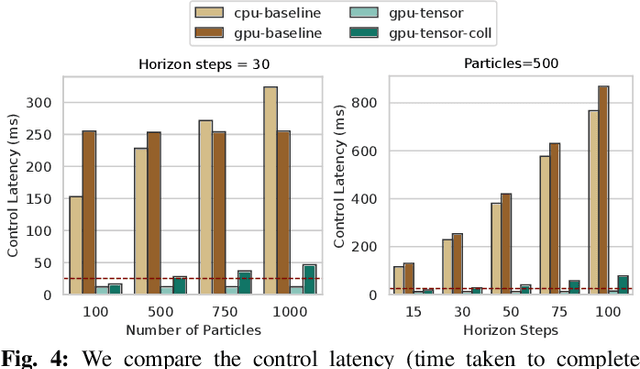
Sampling-based model predictive control (MPC) is a promising tool for feedback control of robots with complex and non-smooth dynamics and cost functions. The computationally demanding nature of sampling-based MPC algorithms is a key bottleneck in their application to high-dimensional robotic manipulation problems. Previous methods have addressed this issue by running MPC in the task space while relying on a low-level operational space controller for joint control. However, by not using the joint space of the robot in the MPC formulation, existing methods cannot directly account for non-task space related constraints such as avoiding joint limits, singular configurations, and link collisions. In this paper, we develop a joint space sampling-based MPC for manipulators that can be efficiently parallelized using GPUs. Our approach can handle task and joint space constraints while taking less than 0.02 seconds (50Hz) to compute the next control command. Further, our method can integrate perception into the control problem by utilizing learned cost functions from raw sensor data. We validate our approach by deploying it on a Franka Panda robot for a variety of common manipulation tasks. We study the effect of different cost formulations and MPC parameters on the synthesized behavior and provide key insights that pave the way for the application of sampling-based MPC for manipulators in a principled manner. Videos of experiments can be found at: https://sites.google.com/view/manipulation-mppi.
RMP2: A Structured Composable Policy Class for Robot Learning
Mar 10, 2021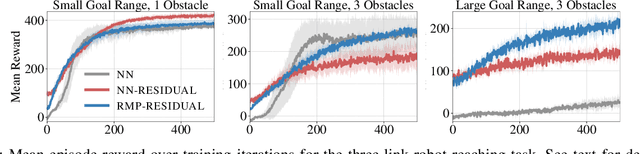
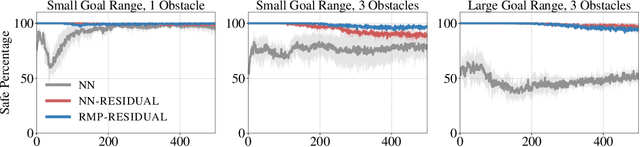
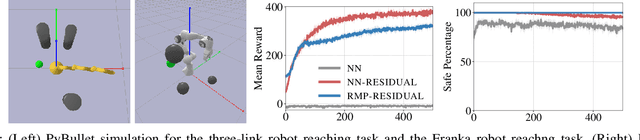
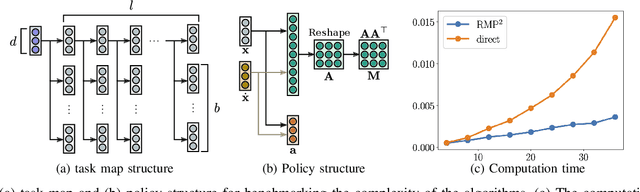
We consider the problem of learning motion policies for acceleration-based robotics systems with a structured policy class specified by RMPflow. RMPflow is a multi-task control framework that has been successfully applied in many robotics problems. Using RMPflow as a structured policy class in learning has several benefits, such as sufficient expressiveness, the flexibility to inject different levels of prior knowledge as well as the ability to transfer policies between robots. However, implementing a system for end-to-end learning RMPflow policies faces several computational challenges. In this work, we re-examine the message passing algorithm of RMPflow and propose a more efficient alternate algorithm, called RMP2, that uses modern automatic differentiation tools (such as TensorFlow and PyTorch) to compute RMPflow policies. Our new design retains the strengths of RMPflow while bringing in advantages from automatic differentiation, including 1) easy programming interfaces to designing complex transformations; 2) support of general directed acyclic graph (DAG) transformation structures; 3) end-to-end differentiability for policy learning; 4) improved computational efficiency. Because of these features, RMP2 can be treated as a structured policy class for efficient robot learning which is suitable encoding domain knowledge. Our experiments show that using structured policy class given by RMP2 can improve policy performance and safety in reinforcement learning tasks for goal reaching in cluttered space.
Towards Coordinated Robot Motions: End-to-End Learning of Motion Policies on Transform Trees
Dec 24, 2020
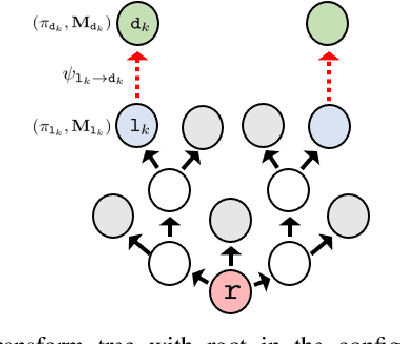
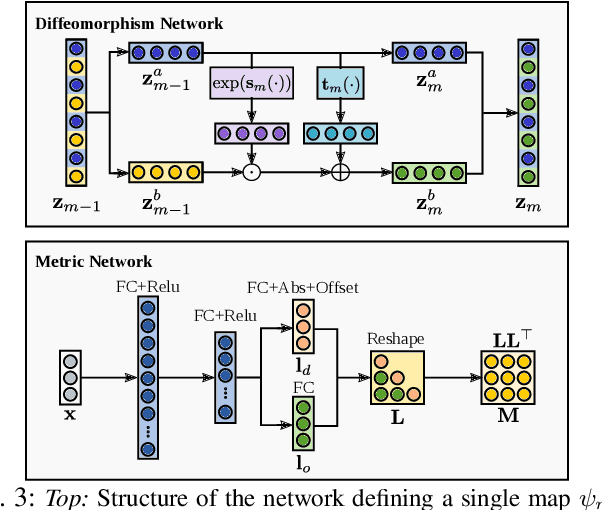
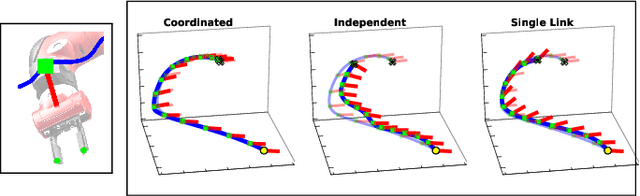
Robotic tasks often require generation of motions that satisfy multiple motion constraints, that may live on different parts of a robot's body. In this paper, we address the challenge of learning motion policies to generate motions for execution of such tasks. Additionally, to encode multiple motion constraints and their synergies, we enforce structure in our motion policy. Specifically, the structure results from decomposing a motion policy into multiple subtask policies, whereby each subtask policy dictates a particular subtask behavior. By learning the subtask policies together in an end-to-end fashion, our formulation not only learns coordination between subtask behaviors, but also learns how to trade them off against default behaviors that may exist. Furthermore, due to our choice of parameterization for the constituting subtask policies, our overall structured motion policy is guaranteed to generate stable motions. To corroborate our theory, we also present qualitative and quantitative evaluations on multiple robotic tasks.
Geometric Fabrics for the Acceleration-based Design of Robotic Motion
Nov 11, 2020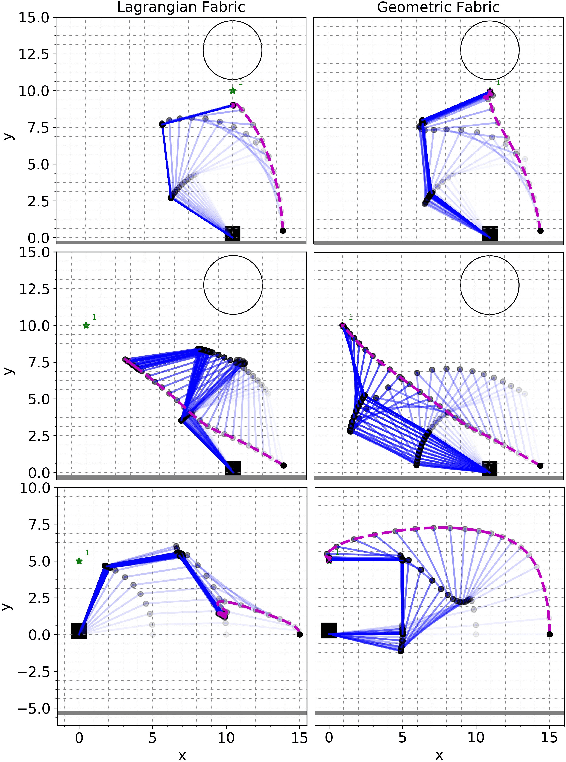

This paper describes the pragmatic design and construction of geometric fabrics for shaping a robot's task-independent nominal behavior, capturing behavioral components such as obstacle avoidance, joint limit avoidance, redundancy resolution, global navigation heuristics, etc. Geometric fabrics constitute the most concrete incarnation of a new mathematical formulation for reactive behavior called optimization fabrics. Fabrics generalize recent work on Riemannian Motion Policies (RMPs); they add provable stability guarantees and improve design consistency while promoting the intuitive acceleration-based principles of modular design that make RMPs successful. We describe a suite of mathematical modeling tools that practitioners can employ in practice and demonstrate both how to mitigate system complexity by constructing behaviors layer-wise and how to employ these tools to design robust, strongly-generalizing, policies that solve practical problems one would expect to find in industry applications. Our system exhibits intelligent global navigation behaviors expressed entirely as fabrics with zero planning or state machine governance.