 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoDE: Collocation for Demonstration Encoding
Paper and Code
May 07, 2021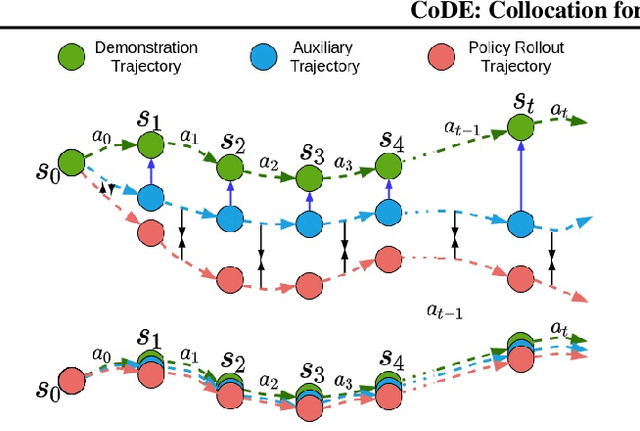
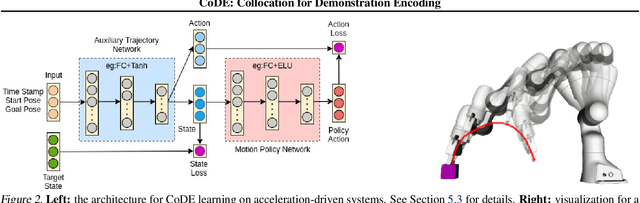
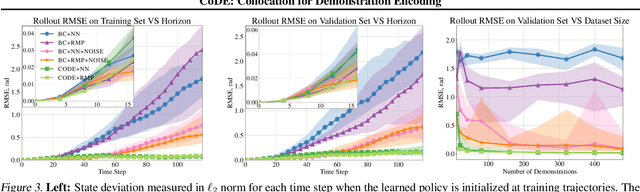
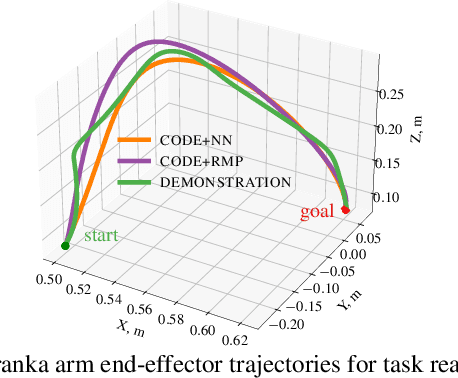
Roboticists frequently turn to Imitation learning (IL) for data efficient policy learning. Many IL methods, canonicalized by the seminal work on Dataset Aggregation (DAgger), combat distributional shift issues with older Behavior Cloning (BC) methods by introducing oracle experts. Unfortunately, access to oracle experts is often unrealistic in practice; data frequently comes from manual offline methods such as lead-through or teleoperation. We present a data-efficient imitation learning technique called Collocation for Demonstration Encoding (CoDE) that operates on only a fixed set of trajectory demonstrations by modeling learning as empirical risk minimization. We circumvent problematic back-propagation through time problems by introducing an auxiliary trajectory network taking inspiration from collocation techniques in optimal control. Our method generalizes well and is much more data efficient than standard BC methods. We present experiments on a 7-degree-of-freedom (DoF) robotic manipulator learning behavior shaping policies for efficient tabletop operation.