 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMP2: A Structured Composable Policy Class for Robot Learning
Paper and Code
Mar 10, 2021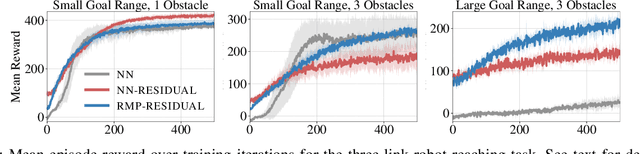
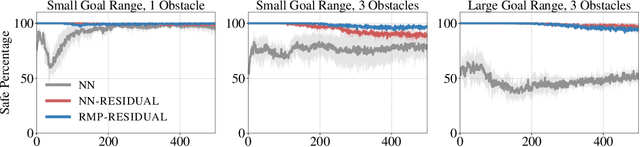
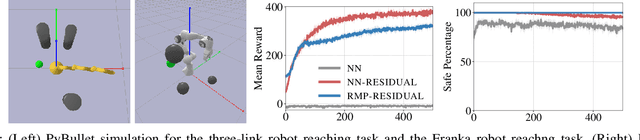
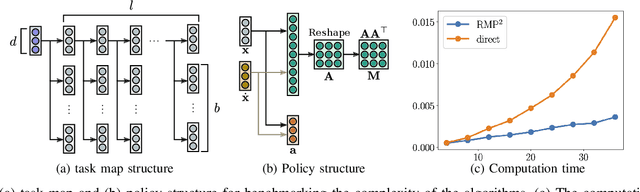
We consider the problem of learning motion policies for acceleration-based robotics systems with a structured policy class specified by RMPflow. RMPflow is a multi-task control framework that has been successfully applied in many robotics problems. Using RMPflow as a structured policy class in learning has several benefits, such as sufficient expressiveness, the flexibility to inject different levels of prior knowledge as well as the ability to transfer policies between robots. However, implementing a system for end-to-end learning RMPflow policies faces several computational challenges. In this work, we re-examine the message passing algorithm of RMPflow and propose a more efficient alternate algorithm, called RMP2, that uses modern automatic differentiation tools (such as TensorFlow and PyTorch) to compute RMPflow policies. Our new design retains the strengths of RMPflow while bringing in advantages from automatic differentiation, including 1) easy programming interfaces to designing complex transformations; 2) support of general directed acyclic graph (DAG) transformation structures; 3) end-to-end differentiability for policy learning; 4) improved computational efficiency. Because of these features, RMP2 can be treated as a structured policy class for efficient robot learning which is suitable encoding domain knowledge. Our experiments show that using structured policy class given by RMP2 can improve policy performance and safety in reinforcement learning tasks for goal reaching in cluttered space.