 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRMP2: A Structured Composable Policy Class for Robot Learning
Mar 10, 2021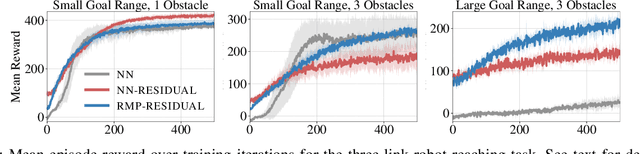
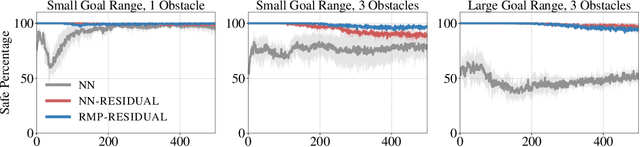
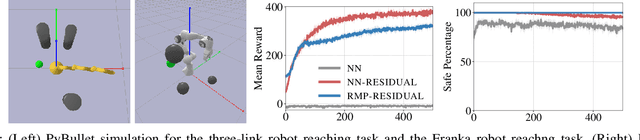
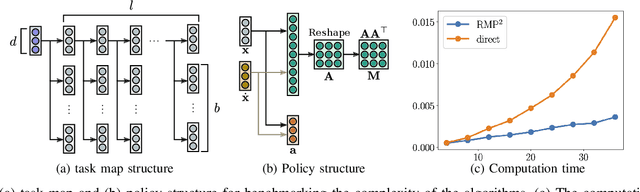
We consider the problem of learning motion policies for acceleration-based robotics systems with a structured policy class specified by RMPflow. RMPflow is a multi-task control framework that has been successfully applied in many robotics problems. Using RMPflow as a structured policy class in learning has several benefits, such as sufficient expressiveness, the flexibility to inject different levels of prior knowledge as well as the ability to transfer policies between robots. However, implementing a system for end-to-end learning RMPflow policies faces several computational challenges. In this work, we re-examine the message passing algorithm of RMPflow and propose a more efficient alternate algorithm, called RMP2, that uses modern automatic differentiation tools (such as TensorFlow and PyTorch) to compute RMPflow policies. Our new design retains the strengths of RMPflow while bringing in advantages from automatic differentiation, including 1) easy programming interfaces to designing complex transformations; 2) support of general directed acyclic graph (DAG) transformation structures; 3) end-to-end differentiability for policy learning; 4) improved computational efficiency. Because of these features, RMP2 can be treated as a structured policy class for efficient robot learning which is suitable encoding domain knowledge. Our experiments show that using structured policy class given by RMP2 can improve policy performance and safety in reinforcement learning tasks for goal reaching in cluttered space.
Towards Coordinated Robot Motions: End-to-End Learning of Motion Policies on Transform Trees
Dec 24, 2020
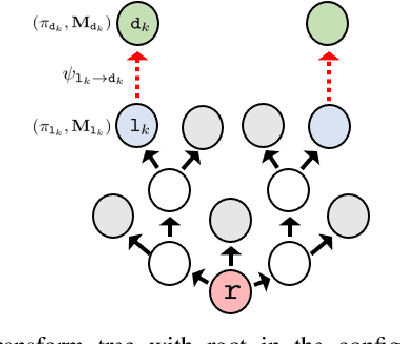
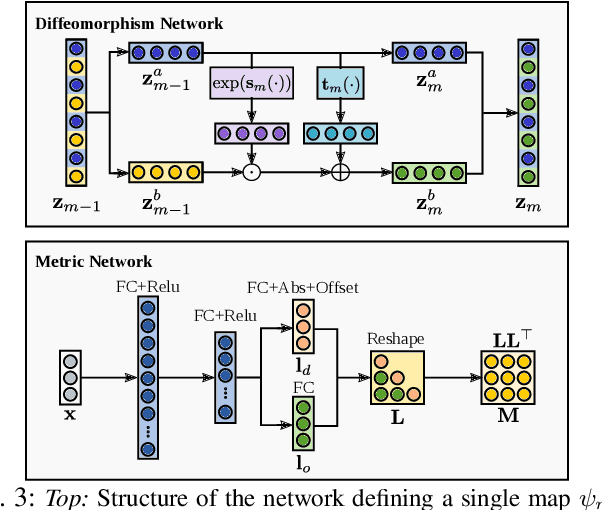
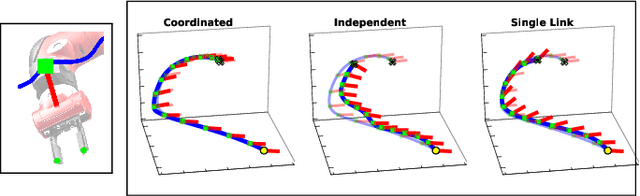
Robotic tasks often require generation of motions that satisfy multiple motion constraints, that may live on different parts of a robot's body. In this paper, we address the challenge of learning motion policies to generate motions for execution of such tasks. Additionally, to encode multiple motion constraints and their synergies, we enforce structure in our motion policy. Specifically, the structure results from decomposing a motion policy into multiple subtask policies, whereby each subtask policy dictates a particular subtask behavior. By learning the subtask policies together in an end-to-end fashion, our formulation not only learns coordination between subtask behaviors, but also learns how to trade them off against default behaviors that may exist. Furthermore, due to our choice of parameterization for the constituting subtask policies, our overall structured motion policy is guaranteed to generate stable motions. To corroborate our theory, we also present qualitative and quantitative evaluations on multiple robotic tasks.
Benchmark for Skill Learning from Demonstration: Impact of User Experience, Task Complexity, and Start Configuration on Performance
Nov 07, 2019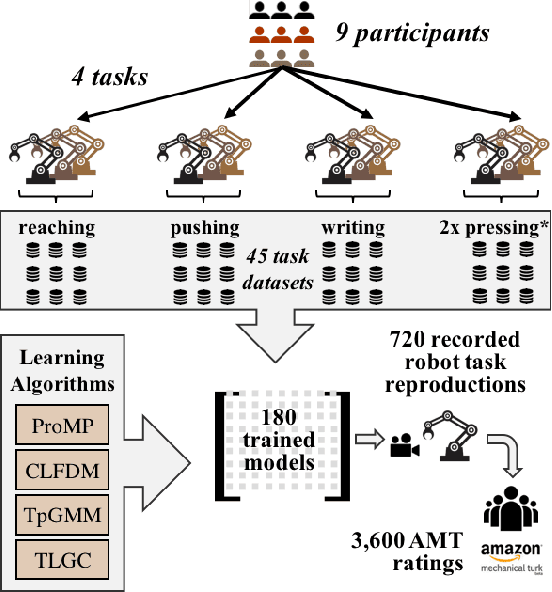
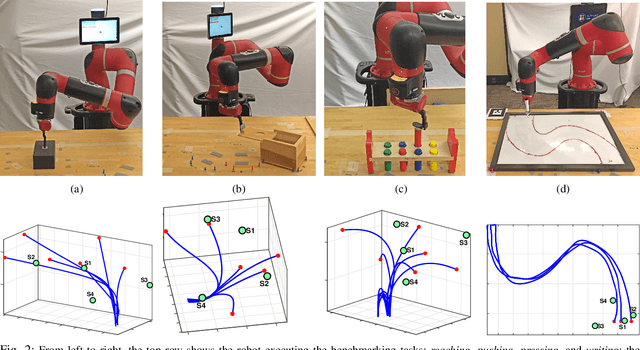
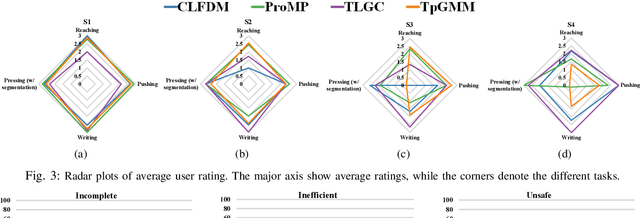

In this work, we contribute a large-scale study benchmarking the performance of multiple motion-based learning from demonstration approaches. Given the number and diversity of existing methods, it is critical that comprehensive empirical studies be performed comparing the relative strengths of these learning techniques. In particular, we evaluate four different approaches based on properties an end user may desire for real-world tasks. To perform this evaluation, we collected data from nine participants, across four different manipulation tasks with varying starting conditions. The resulting demonstrations were used to train 180 task models and evaluated on 720 task reproductions on a physical robot. Our results detail how i) complexity of the task, ii) the expertise of the human demonstrator, and iii) the starting configuration of the robot affect task performance. The collected dataset of demonstrations, robot executions, and evaluations are being made publicly available. Research insights and guidelines are also provided to guide future research and deployment choices about these approaches.
Skill Acquisition via Automated Multi-Coordinate Cost Balancing
Mar 27, 2019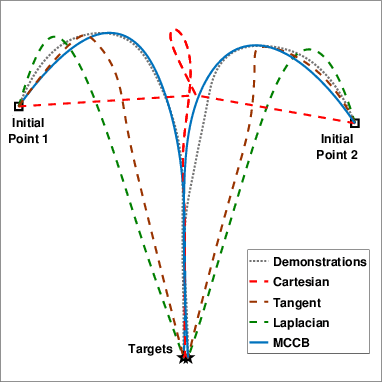
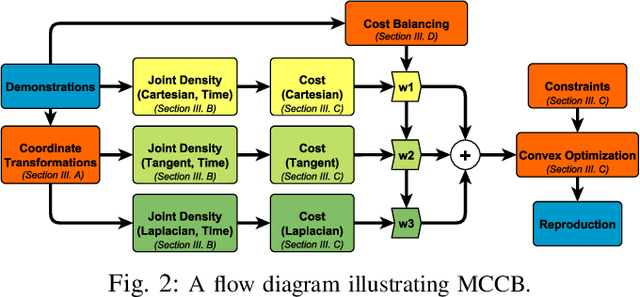

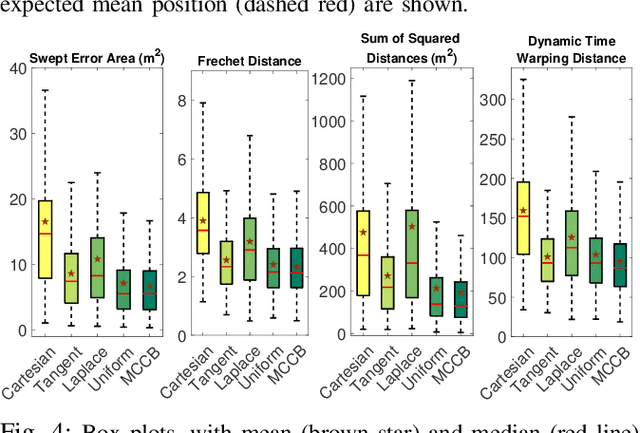
We propose a learning framework, named Multi-Coordinate Cost Balancing (MCCB), to address the problem of acquiring point-to-point movement skills from demonstrations. MCCB encodes demonstrations simultaneously in multiple differential coordinates that specify local geometric properties. MCCB generates reproductions by solving a convex optimization problem with a multi-coordinate cost function and linear constraints on the reproductions, such as initial, target, and via points. Further, since the relative importance of each coordinate system in the cost function might be unknown for a given skill, MCCB learns optimal weighting factors that balance the cost function. We demonstrate the effectiveness of MCCB via detailed experiments conducted on one handwriting dataset and three complex skill datasets.