 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Human-AI Coordination through Adversarial Training and Generative Models
Apr 21, 2025Being able to cooperate with new people is an important component of many economically valuable AI tasks, from household robotics to autonomous driving. However, generalizing to novel humans requires training on data that captures the diversity of human behaviors. Adversarial training is one avenue for searching for such data and ensuring that agents are robust. However, it is difficult to apply in the cooperative setting because adversarial policies intentionally learn to sabotage the task instead of simulating valid cooperation partners. To address this challenge, we propose a novel strategy for overcoming self-sabotage that combines a pre-trained generative model to simulate valid cooperative agent policies with adversarial training to maximize regret. We call our method GOAT: Generative Online Adversarial Training. In this framework, the GOAT dynamically searches for and generates coordination strategies where the learning policy -- the Cooperator agent -- underperforms. GOAT enables better generalization by exposing the Cooperator to various challenging interaction scenarios. We maintain realistic coordination strategies by updating only the generative model's embedding while keeping its parameters frozen, thus avoiding adversarial exploitation. We evaluate GOAT with real human partners, and the results demonstrate state-of-the-art performance on the Overcooked benchmark, highlighting its effectiveness in generalizing to diverse human behaviors.
Learning to Cooperate with Humans using Generative Agents
Nov 21, 2024Training agents that can coordinate zero-shot with humans is a key mission in multi-agent reinforcement learning (MARL). Current algorithms focus on training simulated human partner policies which are then used to train a Cooperator agent. The simulated human is produced either through behavior cloning over a dataset of human cooperation behavior, or by using MARL to create a population of simulated agents. However, these approaches often struggle to produce a Cooperator that can coordinate well with real humans, since the simulated humans fail to cover the diverse strategies and styles employed by people in the real world. We show \emph{learning a generative model of human partners} can effectively address this issue. Our model learns a latent variable representation of the human that can be regarded as encoding the human's unique strategy, intention, experience, or style. This generative model can be flexibly trained from any (human or neural policy) agent interaction data. By sampling from the latent space, we can use the generative model to produce different partners to train Cooperator agents. We evaluate our method -- \textbf{G}enerative \textbf{A}gent \textbf{M}odeling for \textbf{M}ulti-agent \textbf{A}daptation (GAMMA) -- on Overcooked, a challenging cooperative cooking game that has become a standard benchmark for zero-shot coordination. We conduct an evaluation with real human teammates, and the results show that GAMMA consistently improves performance, whether the generative model is trained on simulated populations or human datasets. Further, we propose a method for posterior sampling from the generative model that is biased towards the human data, enabling us to efficiently improve performance with only a small amount of expensive human interaction data.
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Anticipatory Human-Robot Collaboration via Multi-Objective Trajectory Optimization
Jun 05, 2020
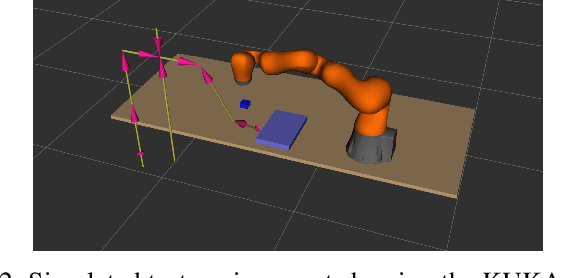

We address the problem of adapting robot trajectories to improve safety, comfort, and efficiency in human-robot collaborative tasks. To this end, we propose CoMOTO, a trajectory optimization framework that utilizes stochastic motion prediction models to anticipate the human's motion and adapt the robot's joint trajectory accordingly. We design a multi-objective cost function that simultaneously optimizes for i) separation distance, ii) visibility of the end-effector, iii) legibility, iv) efficiency, and v) smoothness. We evaluate CoMOTO against three existing methods for robot trajectory generation when in close proximity to humans. Our experimental results indicate that our approach consistently outperforms existing methods over a combined set of safety, comfort, and efficiency metrics.
Benchmark for Skill Learning from Demonstration: Impact of User Experience, Task Complexity, and Start Configuration on Performance
Nov 07, 2019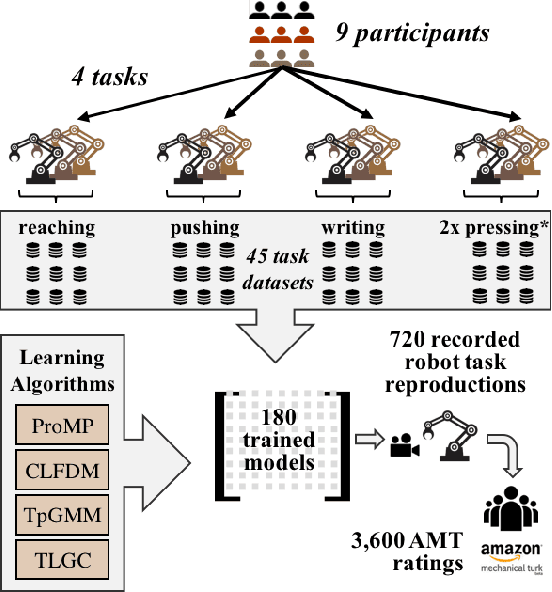
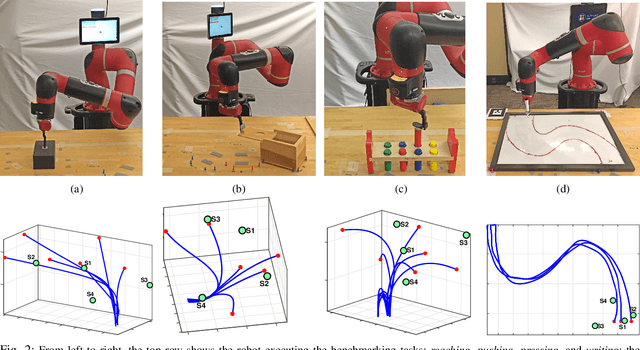
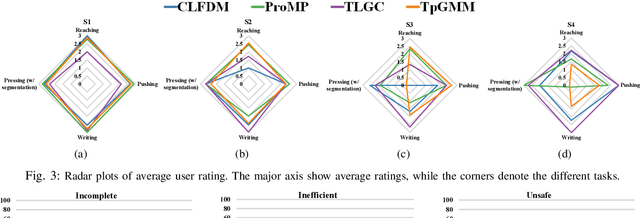

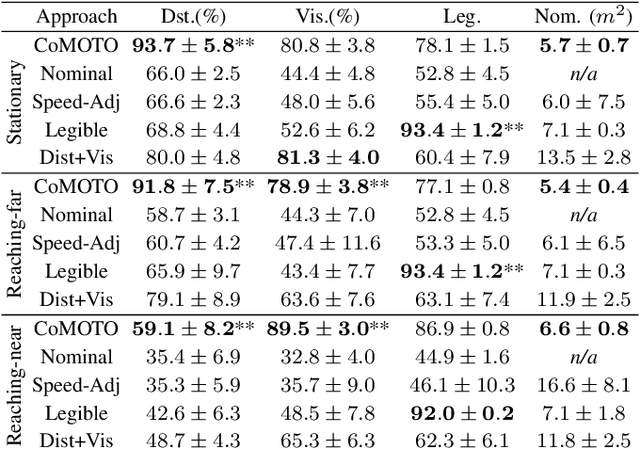
In this work, we contribute a large-scale study benchmarking the performance of multiple motion-based learning from demonstration approaches. Given the number and diversity of existing methods, it is critical that comprehensive empirical studies be performed comparing the relative strengths of these learning techniques. In particular, we evaluate four different approaches based on properties an end user may desire for real-world tasks. To perform this evaluation, we collected data from nine participants, across four different manipulation tasks with varying starting conditions. The resulting demonstrations were used to train 180 task models and evaluated on 720 task reproductions on a physical robot. Our results detail how i) complexity of the task, ii) the expertise of the human demonstrator, and iii) the starting configuration of the robot affect task performance. The collected dataset of demonstrations, robot executions, and evaluations are being made publicly available. Research insights and guidelines are also provided to guide future research and deployment choices about these approaches.