 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMixed Q-Functionals: Advancing Value-Based Methods in Cooperative MARL with Continuous Action Domains
Feb 12, 2024Tackling multi-agent learning problems efficiently is a challenging task in continuous action domains. While value-based algorithms excel in sample efficiency when applied to discrete action domains, they are usually inefficient when dealing with continuous actions. Policy-based algorithms, on the other hand, attempt to address this challenge by leveraging critic networks for guiding the learning process and stabilizing the gradient estimation. The limitations in the estimation of true return and falling into local optima in these methods result in inefficient and often sub-optimal policies. In this paper, we diverge from the trend of further enhancing critic networks, and focus on improving the effectiveness of value-based methods in multi-agent continuous domains by concurrently evaluating numerous actions. We propose a novel multi-agent value-based algorithm, Mixed Q-Functionals (MQF), inspired from the idea of Q-Functionals, that enables agents to transform their states into basis functions. Our algorithm fosters collaboration among agents by mixing their action-values. We evaluate the efficacy of our algorithm in six cooperative multi-agent scenarios. Our empirical findings reveal that MQF outperforms four variants of Deep Deterministic Policy Gradient through rapid action evaluation and increased sample efficiency.
Impact of Relational Networks in Multi-Agent Learning: A Value-Based Factorization View
Oct 19, 2023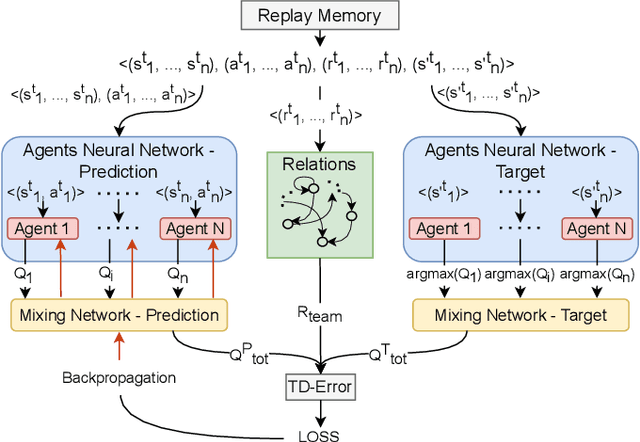
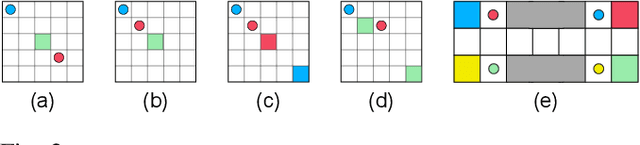
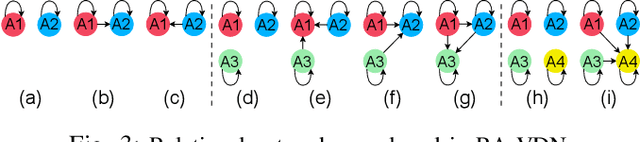
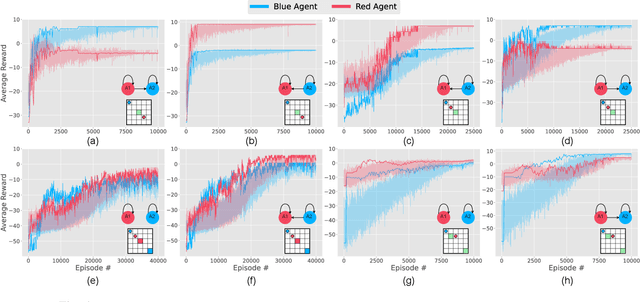
Effective coordination and cooperation among agents are crucial for accomplishing individual or shared objectives in multi-agent systems. In many real-world multi-agent systems, agents possess varying abilities and constraints, making it necessary to prioritize agents based on their specific properties to ensure successful coordination and cooperation within the team. However, most existing cooperative multi-agent algorithms do not take into account these individual differences, and lack an effective mechanism to guide coordination strategies. We propose a novel multi-agent learning approach that incorporates relationship awareness into value-based factorization methods. Given a relational network, our approach utilizes inter-agents relationships to discover new team behaviors by prioritizing certain agents over other, accounting for differences between them in cooperative tasks. We evaluated the effectiveness of our proposed approach by conducting fifteen experiments in two different environments. The results demonstrate that our proposed algorithm can influence and shape team behavior, guide cooperation strategies, and expedite agent learning. Therefore, our approach shows promise for use in multi-agent systems, especially when agents have diverse properties.
Collaborative Adaptation: Learning to Recover from Unforeseen Malfunctions in Multi-Robot Teams
Oct 19, 2023



Cooperative multi-agent reinforcement learning (MARL) approaches tackle the challenge of finding effective multi-agent cooperation strategies for accomplishing individual or shared objectives in multi-agent teams. In real-world scenarios, however, agents may encounter unforeseen failures due to constraints like battery depletion or mechanical issues. Existing state-of-the-art methods in MARL often recover slowly -- if at all -- from such malfunctions once agents have already converged on a cooperation strategy. To address this gap, we present the Collaborative Adaptation (CA) framework. CA introduces a mechanism that guides collaboration and accelerates adaptation from unforeseen failures by leveraging inter-agent relationships. Our findings demonstrate that CA enables agents to act on the knowledge of inter-agent relations, recovering from unforeseen agent failures and selecting appropriate cooperative strategies.
Influence of Team Interactions on Multi-Robot Cooperation: A Relational Network Perspective
Oct 19, 2023



Relational networks within a team play a critical role in the performance of many real-world multi-robot systems. To successfully accomplish tasks that require cooperation and coordination, different agents (e.g., robots) necessitate different priorities based on their positioning within the team. Yet, many of the existing multi-robot cooperation algorithms regard agents as interchangeable and lack a mechanism to guide the type of cooperation strategy the agents should exhibit. To account for the team structure in cooperative tasks, we propose a novel algorithm that uses a relational network comprising inter-agent relationships to prioritize certain agents over others. Through appropriate design of the team's relational network, we can guide the cooperation strategy, resulting in the emergence of new behaviors that accomplish the specified task. We conducted six experiments in a multi-robot setting with a cooperative task. Our results demonstrate that the proposed method can effectively influence the type of solution that the algorithm converges to by specifying the relationships between the agents, making it a promising approach for tasks that require cooperation among agents with a specified team structure.
A Multi-Robot Task Assignment Framework for Search and Rescue with Heterogeneous Teams
Sep 22, 2023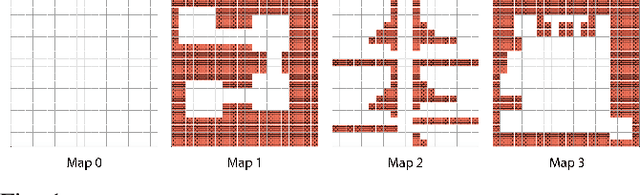
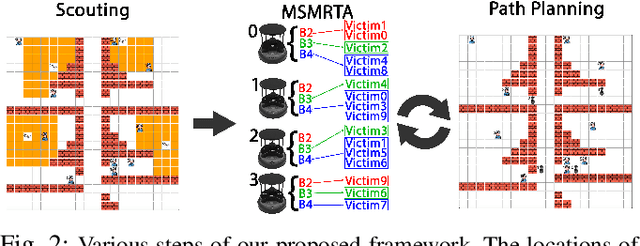

In post-disaster scenarios, efficient search and rescue operations involve collaborative efforts between robots and humans. Existing planning approaches focus on specific aspects but overlook crucial elements like information gathering, task assignment, and planning. Furthermore, previous methods considering robot capabilities and victim requirements suffer from time complexity due to repetitive planning steps. To overcome these challenges, we introduce a comprehensive framework__the Multi-Stage Multi-Robot Task Assignment. This framework integrates scouting, task assignment, and path-planning stages, optimizing task allocation based on robot capabilities, victim requirements, and past robot performance. Our iterative approach ensures objective fulfillment within problem constraints. Evaluation across four maps, comparing with a state-of-the-art baseline, demonstrates our algorithm's superiority with a remarkable 97 percent performance increase. Our code is open-sourced to enable result replication.
Research Report -- Persistent Autonomy and Robot Learning Lab
Aug 27, 2023



Robots capable of performing manipulation tasks in a broad range of missions in unstructured environments can develop numerous applications to impact and enhance human life. Existing work in robot learning has shown success in applying conventional machine learning algorithms to enable robots for replicating rather simple manipulation tasks in manufacturing, service and healthcare applications, among others. However, learning robust and versatile models for complex manipulation tasks that are inherently multi-faceted and naturally intricate demands algorithmic advancements in robot learning. Our research supports the long-term goal of making robots more accessible and serviceable to the general public by expanding robot applications to real-world scenarios that require systems capable of performing complex tasks. To achieve this goal, we focus on identifying and investigating knowledge gaps in robot learning of complex manipulation tasks by leveraging upon human-robot interaction and robot learning from human instructions. This document presents an overview of the recent research developments in the Persistent Autonomy and Robot Learning (PeARL) lab at the University of Massachusetts Lowell. Here, I briefly discuss different research directions, and present a few proposed approaches in our most recent publications. For each proposed approach, I then mention potential future directions that can advance the field.
Confidence-Based Skill Reproduction Through Perturbation Analysis
May 04, 2023Several methods exist for teaching robots, with one of the most prominent being Learning from Demonstration (LfD). Many LfD representations can be formulated as constrained optimization problems. We propose a novel convex formulation of the LfD problem represented as elastic maps, which models reproductions as a series of connected springs. Relying on the properties of strong duality and perturbation analysis of the constrained optimization problem, we create a confidence metric. Our method allows the demonstrated skill to be reproduced with varying confidence level yielding different levels of smoothness and flexibility. Our confidence-based method provides reproductions of the skill that perform better for a given set of constraints. By analyzing the constraints, our method can also remove unnecessary constraints. We validate our approach using several simulated and real-world experiments using a Jaco2 7DOF manipulator arm.
Design and Evaluation of a Bioinspired Tendon-Driven 3D-Printed Robotic Eye with Active Vision Capabilities
May 01, 2023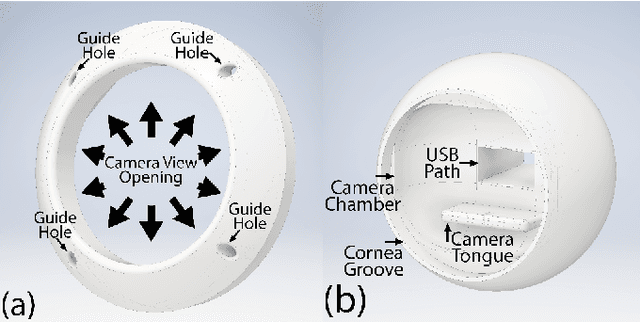



The field of robotics has seen significant advancements in recent years, particularly in the development of humanoid robots. One area of research that has yet to be fully explored is the design of robotic eyes. In this paper, we propose a computer-aided 3D design scheme for a robotic eye that incorporates realistic appearance, natural movements, and efficient actuation. The proposed design utilizes a tendon-driven actuation mechanism, which offers a broad range of motion capabilities. The use of the minimum number of servos for actuation, one for each agonist-antagonist pair of muscles, makes the proposed design highly efficient. Compared to existing ones in the same class, our designed robotic eye comprises aesthetic and realistic features. We evaluate the robot's performance using a vision-based controller, which demonstrates the effectiveness of the proposed design in achieving natural movement, and efficient actuation. The experiment code, toolbox, and printable 3D sketches of our design have been open-sourced.
Contextual Autonomy Evaluation of Unmanned Aerial Vehicles in Subterranean Environments
Jan 06, 2023


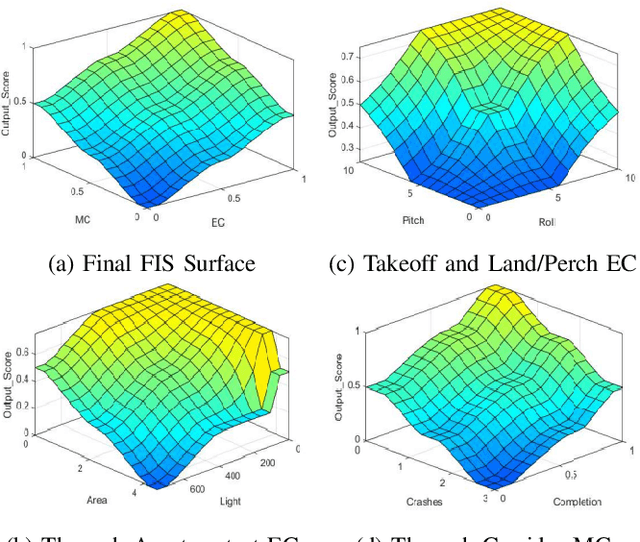
In this paper we focus on the evaluation of contextual autonomy for robots. More specifically, we propose a fuzzy framework for calculating the autonomy score for a small Unmanned Aerial Systems (sUAS) for performing a task while considering task complexity and environmental factors. Our framework is a cascaded Fuzzy Inference System (cFIS) composed of combination of three FIS which represent different contextual autonomy capabilities. We performed several experiments to test our framework in various contexts, such as endurance time, navigation, take off/land, and room clearing, with seven different sUAS. We introduce a predictive measure which improves upon previous predictive measures, allowing for previous real-world task performance to be used in predicting future mission performance.
Robot Learning from Demonstration Using Elastic Maps
Aug 03, 2022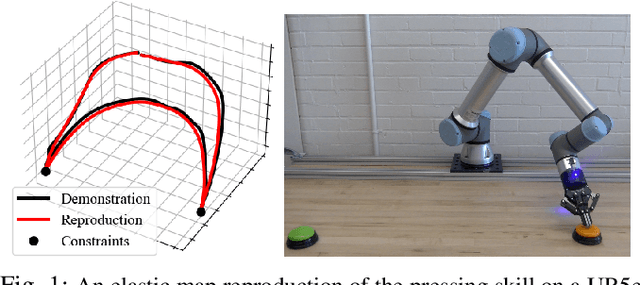
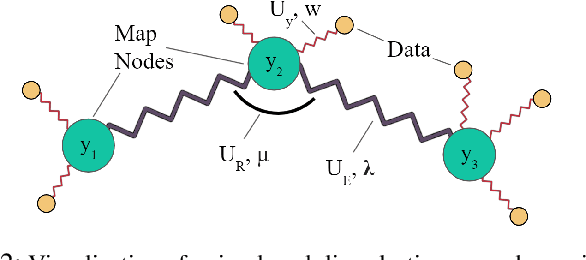
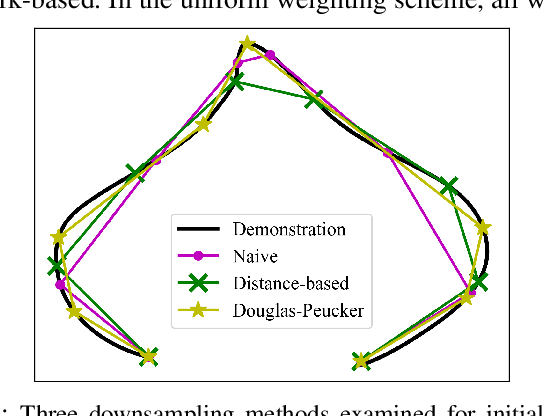

Learning from Demonstration (LfD) is a popular method of reproducing and generalizing robot skills from human-provided demonstrations. In this paper, we propose a novel optimization-based LfD method that encodes demonstrations as elastic maps. An elastic map is a graph of nodes connected through a mesh of springs. We build a skill model by fitting an elastic map to the set of demonstrations. The formulated optimization problem in our approach includes three objectives with natural and physical interpretations. The main term rewards the mean squared error in the Cartesian coordinate. The second term penalizes the non-equidistant distribution of points resulting in the optimum total length of the trajectory. The third term rewards smoothness while penalizing nonlinearity. These quadratic objectives form a convex problem that can be solved efficiently with local optimizers. We examine nine methods for constructing and weighting the elastic maps and study their performance in robotic tasks. We also evaluate the proposed method in several simulated and real-world experiments using a UR5e manipulator arm, and compare it to other LfD approaches to demonstrate its benefits and flexibility across a variety of metrics.