 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRelational Q-Functionals: Multi-Agent Learning to Recover from Unforeseen Robot Malfunctions in Continuous Action Domains
Jul 27, 2024



Cooperative multi-agent learning methods are essential in developing effective cooperation strategies in multi-agent domains. In robotics, these methods extend beyond multi-robot scenarios to single-robot systems, where they enable coordination among different robot modules (e.g., robot legs or joints). However, current methods often struggle to quickly adapt to unforeseen failures, such as a malfunctioning robot leg, especially after the algorithm has converged to a strategy. To overcome this, we introduce the Relational Q-Functionals (RQF) framework. RQF leverages a relational network, representing agents' relationships, to enhance adaptability, providing resilience against malfunction(s). Our algorithm also efficiently handles continuous state-action domains, making it adept for robotic learning tasks. Our empirical results show that RQF enables agents to use these relationships effectively to facilitate cooperation and recover from an unexpected malfunction in single-robot systems with multiple interacting modules. Thus, our approach offers promising applications in multi-agent systems, particularly in scenarios with unforeseen malfunctions.
Impact of Relational Networks in Multi-Agent Learning: A Value-Based Factorization View
Oct 19, 2023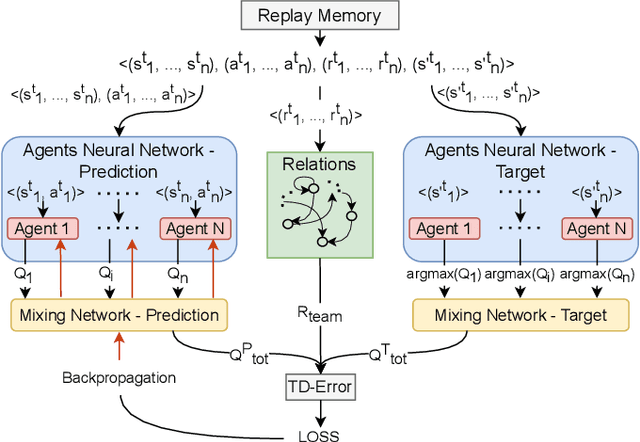
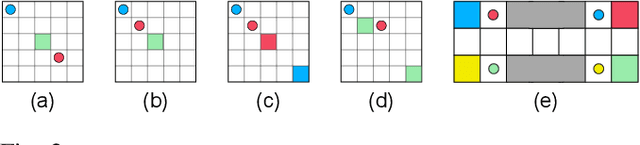
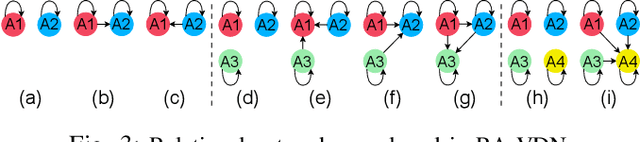
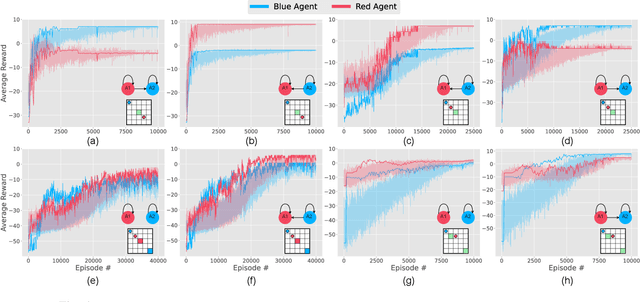
Effective coordination and cooperation among agents are crucial for accomplishing individual or shared objectives in multi-agent systems. In many real-world multi-agent systems, agents possess varying abilities and constraints, making it necessary to prioritize agents based on their specific properties to ensure successful coordination and cooperation within the team. However, most existing cooperative multi-agent algorithms do not take into account these individual differences, and lack an effective mechanism to guide coordination strategies. We propose a novel multi-agent learning approach that incorporates relationship awareness into value-based factorization methods. Given a relational network, our approach utilizes inter-agents relationships to discover new team behaviors by prioritizing certain agents over other, accounting for differences between them in cooperative tasks. We evaluated the effectiveness of our proposed approach by conducting fifteen experiments in two different environments. The results demonstrate that our proposed algorithm can influence and shape team behavior, guide cooperation strategies, and expedite agent learning. Therefore, our approach shows promise for use in multi-agent systems, especially when agents have diverse properties.
Influence of Team Interactions on Multi-Robot Cooperation: A Relational Network Perspective
Oct 19, 2023



Relational networks within a team play a critical role in the performance of many real-world multi-robot systems. To successfully accomplish tasks that require cooperation and coordination, different agents (e.g., robots) necessitate different priorities based on their positioning within the team. Yet, many of the existing multi-robot cooperation algorithms regard agents as interchangeable and lack a mechanism to guide the type of cooperation strategy the agents should exhibit. To account for the team structure in cooperative tasks, we propose a novel algorithm that uses a relational network comprising inter-agent relationships to prioritize certain agents over others. Through appropriate design of the team's relational network, we can guide the cooperation strategy, resulting in the emergence of new behaviors that accomplish the specified task. We conducted six experiments in a multi-robot setting with a cooperative task. Our results demonstrate that the proposed method can effectively influence the type of solution that the algorithm converges to by specifying the relationships between the agents, making it a promising approach for tasks that require cooperation among agents with a specified team structure.
Collaborative Adaptation: Learning to Recover from Unforeseen Malfunctions in Multi-Robot Teams
Oct 19, 2023



Cooperative multi-agent reinforcement learning (MARL) approaches tackle the challenge of finding effective multi-agent cooperation strategies for accomplishing individual or shared objectives in multi-agent teams. In real-world scenarios, however, agents may encounter unforeseen failures due to constraints like battery depletion or mechanical issues. Existing state-of-the-art methods in MARL often recover slowly -- if at all -- from such malfunctions once agents have already converged on a cooperation strategy. To address this gap, we present the Collaborative Adaptation (CA) framework. CA introduces a mechanism that guides collaboration and accelerates adaptation from unforeseen failures by leveraging inter-agent relationships. Our findings demonstrate that CA enables agents to act on the knowledge of inter-agent relations, recovering from unforeseen agent failures and selecting appropriate cooperative strategies.
A Multi-Robot Task Assignment Framework for Search and Rescue with Heterogeneous Teams
Sep 22, 2023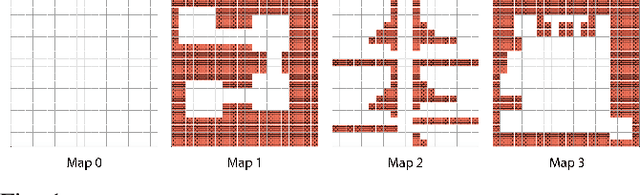
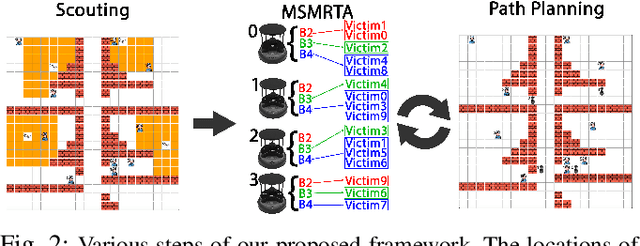
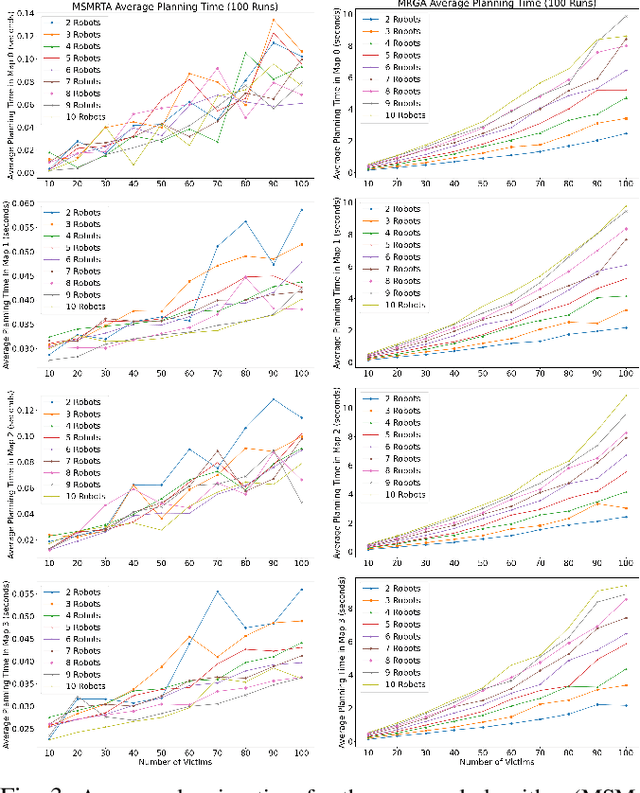

In post-disaster scenarios, efficient search and rescue operations involve collaborative efforts between robots and humans. Existing planning approaches focus on specific aspects but overlook crucial elements like information gathering, task assignment, and planning. Furthermore, previous methods considering robot capabilities and victim requirements suffer from time complexity due to repetitive planning steps. To overcome these challenges, we introduce a comprehensive framework__the Multi-Stage Multi-Robot Task Assignment. This framework integrates scouting, task assignment, and path-planning stages, optimizing task allocation based on robot capabilities, victim requirements, and past robot performance. Our iterative approach ensures objective fulfillment within problem constraints. Evaluation across four maps, comparing with a state-of-the-art baseline, demonstrates our algorithm's superiority with a remarkable 97 percent performance increase. Our code is open-sourced to enable result replication.
DECISIVE Benchmarking Data Report: sUAS Performance Results from Phase I
Jan 20, 2023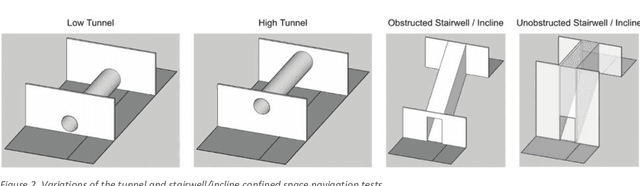
This report reviews all results derived from performance benchmarking conducted during Phase I of the Development and Execution of Comprehensive and Integrated Subterranean Intelligent Vehicle Evaluations (DECISIVE) project by the University of Massachusetts Lowell, using the test methods specified in the DECISIVE Test Methods Handbook v1.1 for evaluating small unmanned aerial systems (sUAS) performance in subterranean and constrained indoor environments, spanning communications, field readiness, interface, obstacle avoidance, navigation, mapping, autonomy, trust, and situation awareness. Using those 20 test methods, over 230 tests were conducted across 8 sUAS platforms: Cleo Robotics Dronut X1P (P = prototype), FLIR Black Hornet PRS, Flyability Elios 2 GOV, Lumenier Nighthawk V3, Parrot ANAFI USA GOV, Skydio X2D, Teal Golden Eagle, and Vantage Robotics Vesper. Best in class criteria is specified for each applicable test method and the sUAS that match this criteria are named for each test method, including a high-level executive summary of their performance.
DECISIVE Test Methods Handbook: Test Methods for Evaluating sUAS in Subterranean and Constrained Indoor Environments, Version 1.1
Nov 01, 2022
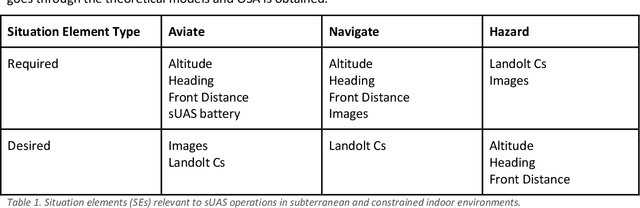
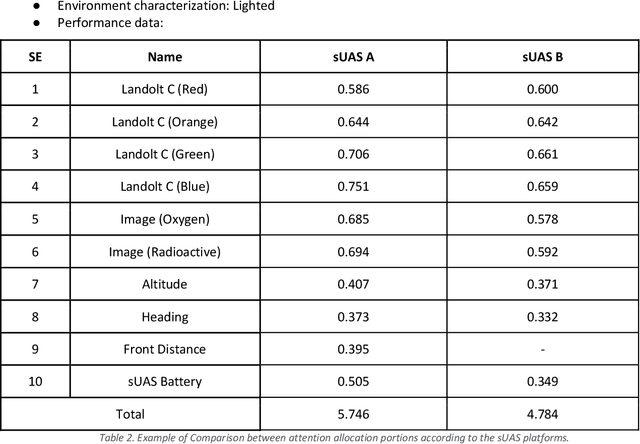
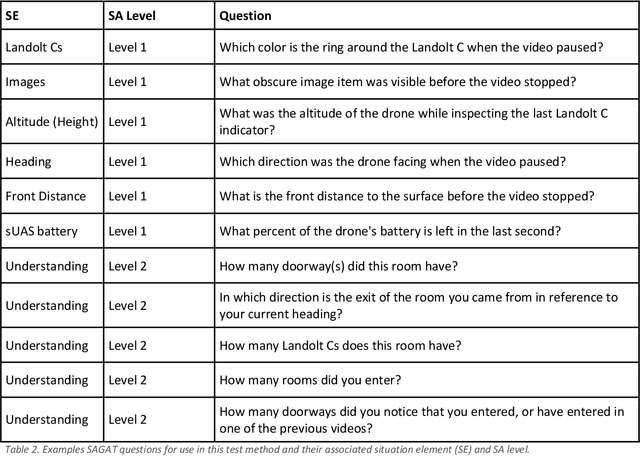
This handbook outlines all test methods developed under the Development and Execution of Comprehensive and Integrated Subterranean Intelligent Vehicle Evaluations (DECISIVE) project by the University of Massachusetts Lowell for evaluating small unmanned aerial systems (sUAS) performance in subterranean and constrained indoor environments, spanning communications, field readiness, interface, obstacle avoidance, navigation, mapping, autonomy, trust, and situation awareness. For sUAS deployment in subterranean and constrained indoor environments, this puts forth two assumptions about applicable sUAS to be evaluated using these test methods: (1) able to operate without access to GPS signal, and (2) width from prop top to prop tip does not exceed 91 cm (36 in) wide (i.e., can physically fit through a typical doorway, although successful navigation through is not guaranteed). All test methods are specified using a common format: Purpose, Summary of Test Method, Apparatus and Artifacts, Equipment, Metrics, Procedure, and Example Data. All test methods are designed to be run in real-world environments (e.g., MOUT sites) or using fabricated apparatuses (e.g., test bays built from wood, or contained inside of one or more shipping containers).
MassMIND: Massachusetts Maritime INfrared Dataset
Sep 09, 2022

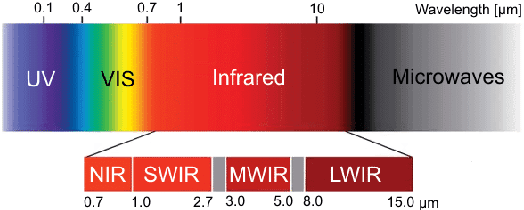

Recent advances in deep learning technology have triggered radical progress in the autonomy of ground vehicles. Marine coastal Autonomous Surface Vehicles (ASVs) that are regularly used for surveillance, monitoring and other routine tasks can benefit from this autonomy. Long haul deep sea transportation activities are additional opportunities. These two use cases present very different terrains -- the first being coastal waters -- with many obstacles, structures and human presence while the latter is mostly devoid of such obstacles. Variations in environmental conditions are common to both terrains. Robust labeled datasets mapping such terrains are crucial in improving the situational awareness that can drive autonomy. However, there are only limited such maritime datasets available and these primarily consist of optical images. Although, Long Wave Infrared (LWIR) is a strong complement to the optical spectrum that helps in extreme light conditions, a labeled public dataset with LWIR images does not currently exist. In this paper, we fill this gap by presenting a labeled dataset of over 2,900 LWIR segmented images captured in coastal maritime environment under diverse conditions. The images are labeled using instance segmentation and classified in seven categories -- sky, water, obstacle, living obstacle, bridge, self and background. We also evaluate this dataset across three deep learning architectures (UNet, PSPNet, DeepLabv3) and provide detailed analysis of its efficacy. While the dataset focuses on the coastal terrain it can equally help deep sea use cases. Such terrain would have less traffic, and the classifier trained on cluttered environment would be able to handle sparse scenes effectively. We share this dataset with the research community with the hope that it spurs new scene understanding capabilities in the maritime environment.
Evaluation of Performance-Trust vs Moral-Trust Violation in 3D Environment
Jun 30, 2022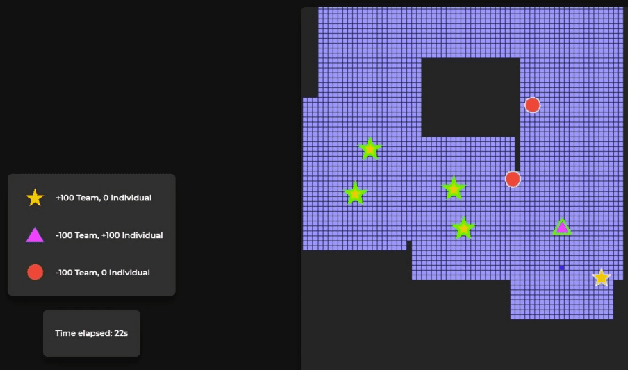

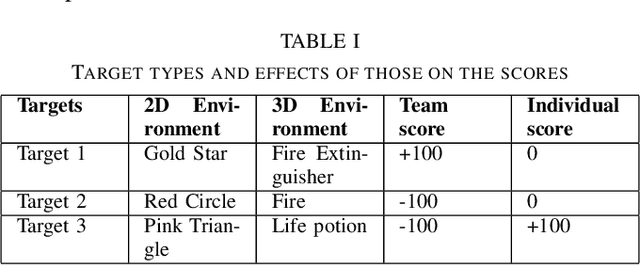
Human-Robot Interaction, in which a robot with some level of autonomy interacts with a human to achieve a specific goal has seen much recent progress. With the introduction of autonomous robots and the possibility of widespread use of those in near future, it is critical that humans understand the robot's intention while interacting with them as this will foster the development of human-robot trust. The new conceptualization of trust which had been introduced by researchers in recent years considers trust in Human-Robot Interaction to be a multidimensional nature. Two main aspects which are attributed to trust are performance trust and moral trust. We aim to design an experiment to investigate the consequences of performance-trust violation and moral-trust violation in a search and rescue scenario. We want to see if two similar robot failures, one caused by a performance-trust violation and the other by a moral-trust violation have distinct effects on human trust. In addition to this, we plan to develop an interface that allows us to investigate whether altering the interface's modality from grid-world scenario (2D environment) to realistic simulation (3D environment) affects human perception of the task and the effects of the robot's failure on human trust.
Trust Calibration and Trust Respect: A Method for Building Team Cohesion in Human Robot Teams
Oct 13, 2021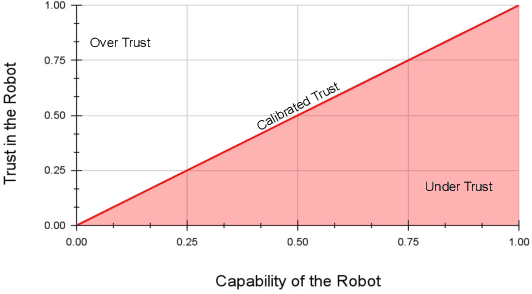
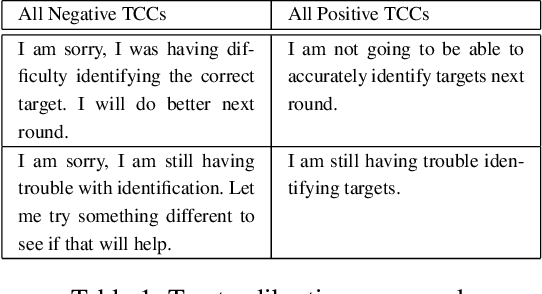
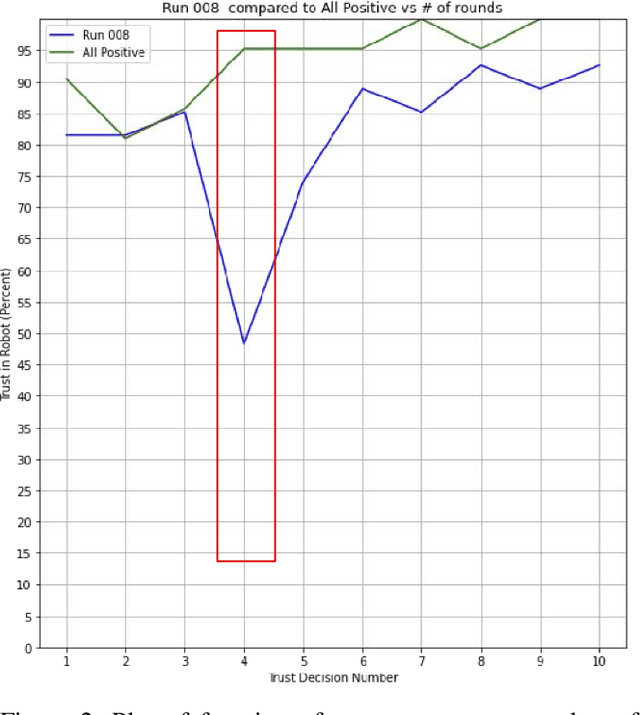
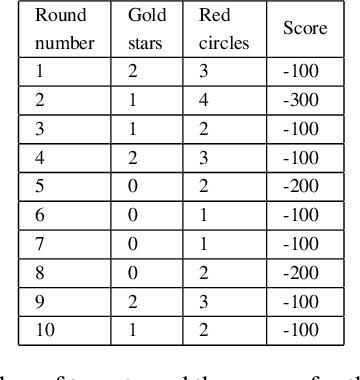
Recent advances in the areas of human-robot interaction (HRI) and robot autonomy are changing the world. Today robots are used in a variety of applications. People and robots work together in human autonomous teams (HATs) to accomplish tasks that, separately, cannot be easily accomplished. Trust between robots and humans in HATs is vital to task completion and effective team cohesion. For optimal performance and safety of human operators in HRI, human trust should be adjusted to the actual performance and reliability of the robotic system. The cost of poor trust calibration in HRI, is at a minimum, low performance, and at higher levels it causes human injury or critical task failures. While the role of trust calibration is vital to team cohesion it is also important for a robot to be able to assess whether or not a human is exhibiting signs of mistrust due to some other factor such as anger, distraction or frustration. In these situations the robot chooses not to calibrate trust, instead the robot chooses to respect trust. The decision to respect trust is determined by the robots knowledge of whether or not a human should trust the robot based on its actions(successes and failures) and its feedback to the human. We show that the feedback in the form of trust calibration cues(TCCs) can effectively change the trust level in humans. This information is potentially useful in aiding a robot it its decision to respect trust.