 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECISIVE Benchmarking Data Report: sUAS Performance Results from Phase I
Jan 20, 2023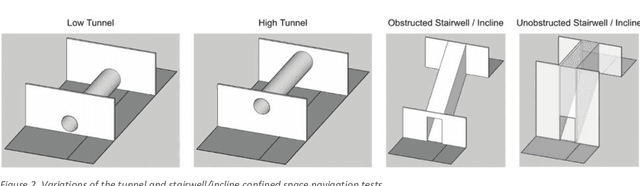
This report reviews all results derived from performance benchmarking conducted during Phase I of the Development and Execution of Comprehensive and Integrated Subterranean Intelligent Vehicle Evaluations (DECISIVE) project by the University of Massachusetts Lowell, using the test methods specified in the DECISIVE Test Methods Handbook v1.1 for evaluating small unmanned aerial systems (sUAS) performance in subterranean and constrained indoor environments, spanning communications, field readiness, interface, obstacle avoidance, navigation, mapping, autonomy, trust, and situation awareness. Using those 20 test methods, over 230 tests were conducted across 8 sUAS platforms: Cleo Robotics Dronut X1P (P = prototype), FLIR Black Hornet PRS, Flyability Elios 2 GOV, Lumenier Nighthawk V3, Parrot ANAFI USA GOV, Skydio X2D, Teal Golden Eagle, and Vantage Robotics Vesper. Best in class criteria is specified for each applicable test method and the sUAS that match this criteria are named for each test method, including a high-level executive summary of their performance.
DECISIVE Test Methods Handbook: Test Methods for Evaluating sUAS in Subterranean and Constrained Indoor Environments, Version 1.1
Nov 01, 2022
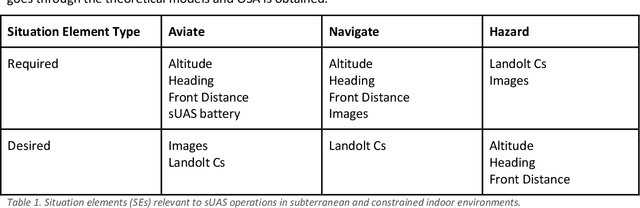
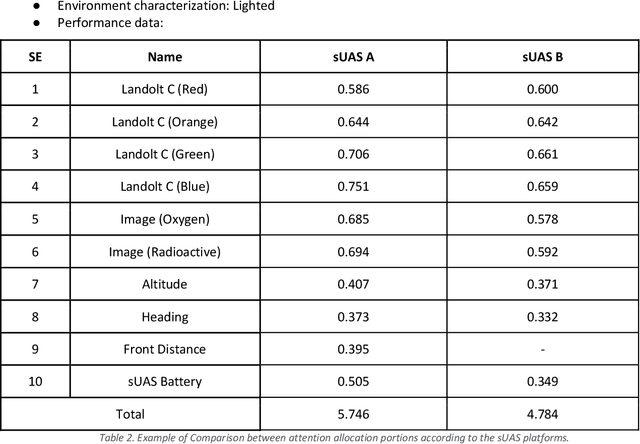
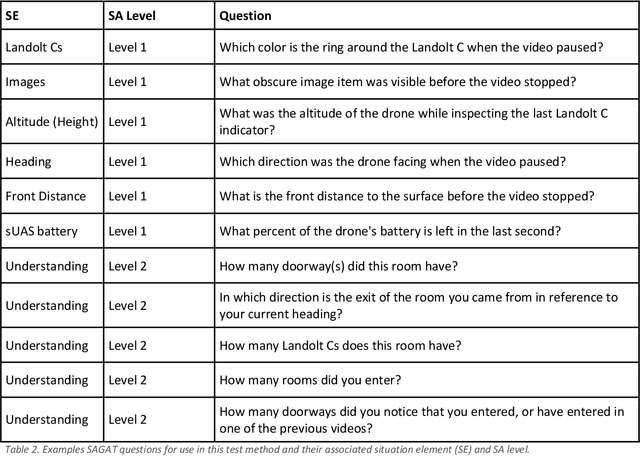
This handbook outlines all test methods developed under the Development and Execution of Comprehensive and Integrated Subterranean Intelligent Vehicle Evaluations (DECISIVE) project by the University of Massachusetts Lowell for evaluating small unmanned aerial systems (sUAS) performance in subterranean and constrained indoor environments, spanning communications, field readiness, interface, obstacle avoidance, navigation, mapping, autonomy, trust, and situation awareness. For sUAS deployment in subterranean and constrained indoor environments, this puts forth two assumptions about applicable sUAS to be evaluated using these test methods: (1) able to operate without access to GPS signal, and (2) width from prop top to prop tip does not exceed 91 cm (36 in) wide (i.e., can physically fit through a typical doorway, although successful navigation through is not guaranteed). All test methods are specified using a common format: Purpose, Summary of Test Method, Apparatus and Artifacts, Equipment, Metrics, Procedure, and Example Data. All test methods are designed to be run in real-world environments (e.g., MOUT sites) or using fabricated apparatuses (e.g., test bays built from wood, or contained inside of one or more shipping containers).
Evidence Updating for Stream-Processing in Big-Data: Robust Conditioning in Soft and Hard Fusion Environments
Jun 10, 2017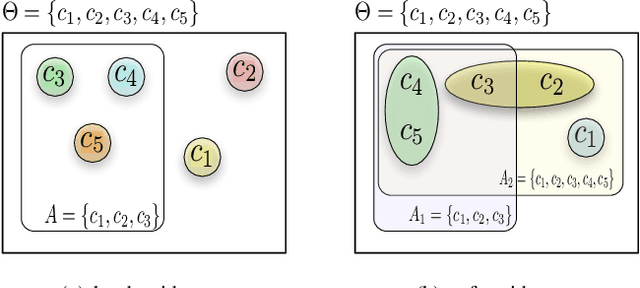
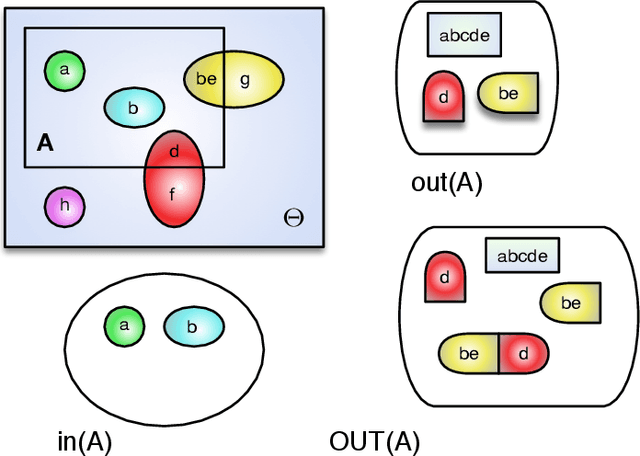
Robust belief revision methods are crucial in streaming data situations for updating existing knowledge or beliefs with new incoming evidence. Bayes conditioning is the primary mechanism in use for belief revision in data fusion systems that use probabilistic inference. However, traditional conditioning methods face several challenges due to inherent data/source imperfections in big-data environments that harness soft (i.e., human or human-based) sources in addition to hard (i.e., physics-based) sensors. The objective of this paper is to investigate the most natural extension of Bayes conditioning that is suitable for evidence updating in the presence of such uncertainties. By viewing the evidence updating process as a thought experiment, an elegant strategy is derived for robust evidence updating in the presence of extreme uncertainties that are characteristic of big-data environments. In particular, utilizing the Fagin-Halpern conditional notions, a natural extension to Bayes conditioning is derived for evidence that takes the form of a general belief function. The presented work differs fundamentally from the Conditional Update Equation (CUE) and authors own extensions of it. An overview of this development is provided via illustrative examples. Furthermore, insights into parameter selection under various fusion contexts are also provided.