 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDECISIVE Benchmarking Data Report: sUAS Performance Results from Phase I
Jan 20, 2023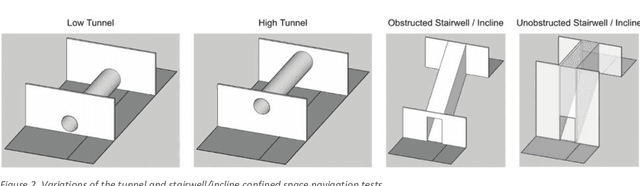
This report reviews all results derived from performance benchmarking conducted during Phase I of the Development and Execution of Comprehensive and Integrated Subterranean Intelligent Vehicle Evaluations (DECISIVE) project by the University of Massachusetts Lowell, using the test methods specified in the DECISIVE Test Methods Handbook v1.1 for evaluating small unmanned aerial systems (sUAS) performance in subterranean and constrained indoor environments, spanning communications, field readiness, interface, obstacle avoidance, navigation, mapping, autonomy, trust, and situation awareness. Using those 20 test methods, over 230 tests were conducted across 8 sUAS platforms: Cleo Robotics Dronut X1P (P = prototype), FLIR Black Hornet PRS, Flyability Elios 2 GOV, Lumenier Nighthawk V3, Parrot ANAFI USA GOV, Skydio X2D, Teal Golden Eagle, and Vantage Robotics Vesper. Best in class criteria is specified for each applicable test method and the sUAS that match this criteria are named for each test method, including a high-level executive summary of their performance.
DECISIVE Test Methods Handbook: Test Methods for Evaluating sUAS in Subterranean and Constrained Indoor Environments, Version 1.1
Nov 01, 2022
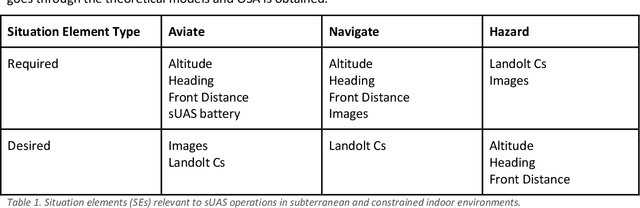
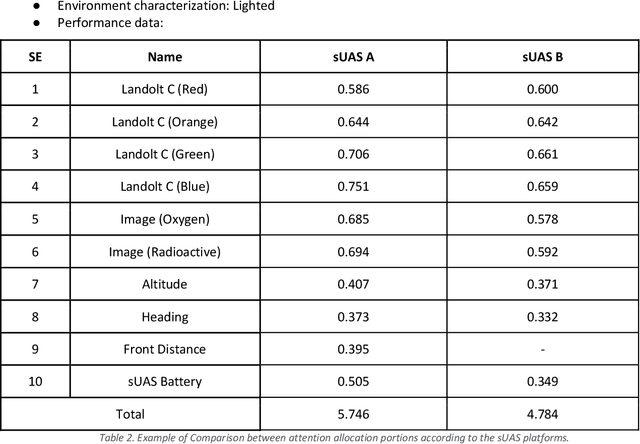
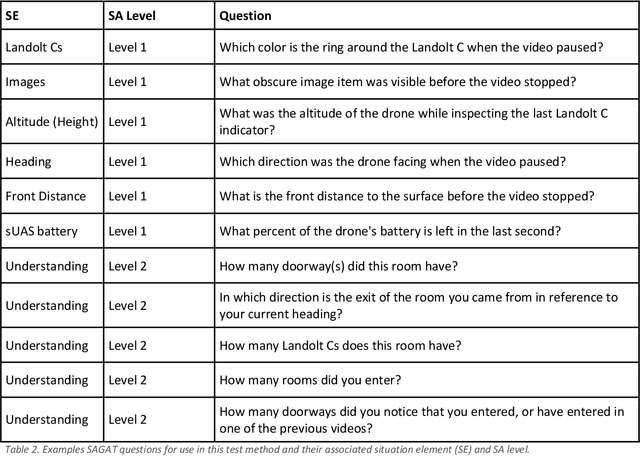
This handbook outlines all test methods developed under the Development and Execution of Comprehensive and Integrated Subterranean Intelligent Vehicle Evaluations (DECISIVE) project by the University of Massachusetts Lowell for evaluating small unmanned aerial systems (sUAS) performance in subterranean and constrained indoor environments, spanning communications, field readiness, interface, obstacle avoidance, navigation, mapping, autonomy, trust, and situation awareness. For sUAS deployment in subterranean and constrained indoor environments, this puts forth two assumptions about applicable sUAS to be evaluated using these test methods: (1) able to operate without access to GPS signal, and (2) width from prop top to prop tip does not exceed 91 cm (36 in) wide (i.e., can physically fit through a typical doorway, although successful navigation through is not guaranteed). All test methods are specified using a common format: Purpose, Summary of Test Method, Apparatus and Artifacts, Equipment, Metrics, Procedure, and Example Data. All test methods are designed to be run in real-world environments (e.g., MOUT sites) or using fabricated apparatuses (e.g., test bays built from wood, or contained inside of one or more shipping containers).
Reward-Sharing Relational Networks in Multi-Agent Reinforcement Learning as a Framework for Emergent Behavior
Jul 14, 2022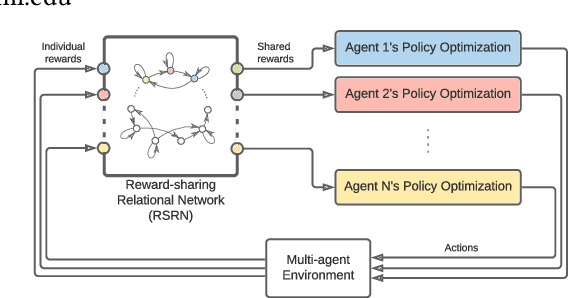
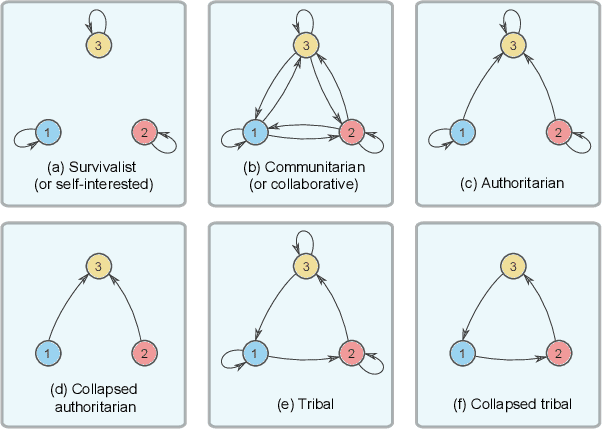
In this work, we integrate `social' interactions into the MARL setup through a user-defined relational network and examine the effects of agent-agent relations on the rise of emergent behaviors. Leveraging insights from sociology and neuroscience, our proposed framework models agent relationships using the notion of Reward-Sharing Relational Networks (RSRN), where network edge weights act as a measure of how much one agent is invested in the success of (or `cares about') another. We construct relational rewards as a function of the RSRN interaction weights to collectively train the multi-agent system via a multi-agent reinforcement learning algorithm. The performance of the system is tested for a 3-agent scenario with different relational network structures (e.g., self-interested, communitarian, and authoritarian networks). Our results indicate that reward-sharing relational networks can significantly influence learned behaviors. We posit that RSRN can act as a framework where different relational networks produce distinct emergent behaviors, often analogous to the intuited sociological understanding of such networks.
Modeling Trust in Human-Robot Interaction: A Survey
Nov 09, 2020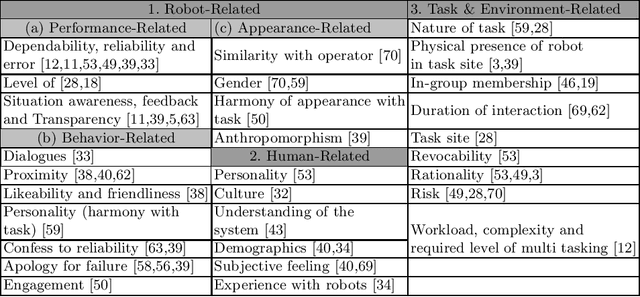
As the autonomy and capabilities of robotic systems increase, they are expected to play the role of teammates rather than tools and interact with human collaborators in a more realistic manner, creating a more human-like relationship. Given the impact of trust observed in human-robot interaction (HRI), appropriate trust in robotic collaborators is one of the leading factors influencing the performance of human-robot interaction. Team performance can be diminished if people do not trust robots appropriately by disusing or misusing them based on limited experience. Therefore, trust in HRI needs to be calibrated properly, rather than maximized, to let the formation of an appropriate level of trust in human collaborators. For trust calibration in HRI, trust needs to be modeled first. There are many reviews on factors affecting trust in HRI, however, as there are no reviews concentrated on different trust models, in this paper, we review different techniques and methods for trust modeling in HRI. We also present a list of potential directions for further research and some challenges that need to be addressed in future work on human-robot trust modeling.