 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInvestigating Adaptive Tuning of Assistive Exoskeletons Using Offline Reinforcement Learning: Challenges and Insights
Apr 30, 2025
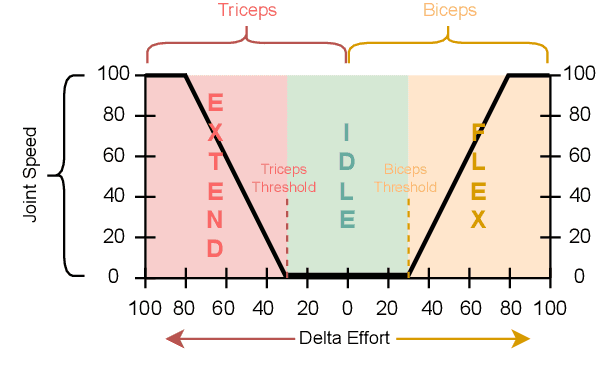
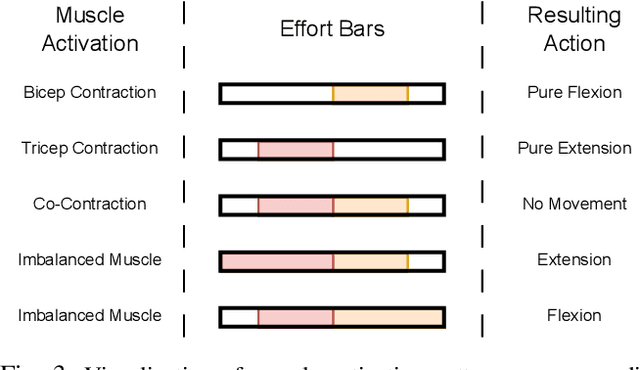
Assistive exoskeletons have shown great potential in enhancing mobility for individuals with motor impairments, yet their effectiveness relies on precise parameter tuning for personalized assistance. In this study, we investigate the potential of offline reinforcement learning for optimizing effort thresholds in upper-limb assistive exoskeletons, aiming to reduce reliance on manual calibration. Specifically, we frame the problem as a multi-agent system where separate agents optimize biceps and triceps effort thresholds, enabling a more adaptive and data-driven approach to exoskeleton control. Mixed Q-Functionals (MQF) is employed to efficiently handle continuous action spaces while leveraging pre-collected data, thereby mitigating the risks associated with real-time exploration. Experiments were conducted using the MyoPro 2 exoskeleton across two distinct tasks involving horizontal and vertical arm movements. Our results indicate that the proposed approach can dynamically adjust threshold values based on learned patterns, potentially improving user interaction and control, though performance evaluation remains challenging due to dataset limitations.
Collaborative Adaptation for Recovery from Unforeseen Malfunctions in Discrete and Continuous MARL Domains
Jul 27, 2024
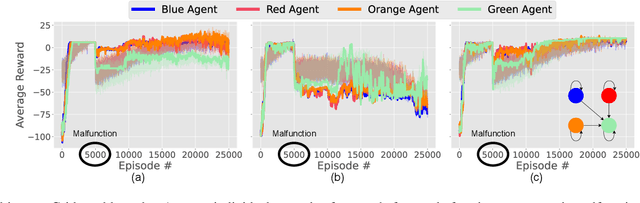

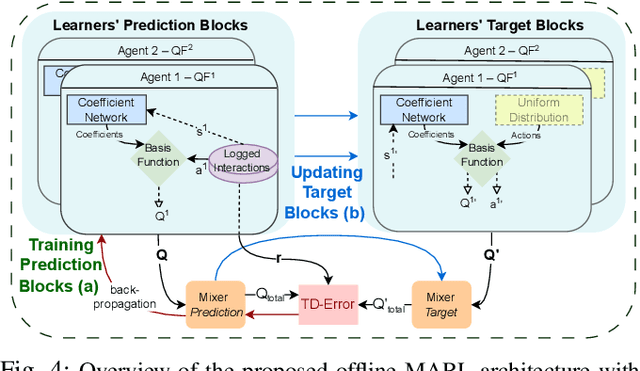
Cooperative multi-agent learning plays a crucial role for developing effective strategies to achieve individual or shared objectives in multi-agent teams. In real-world settings, agents may face unexpected failures, such as a robot's leg malfunctioning or a teammate's battery running out. These malfunctions decrease the team's ability to accomplish assigned task(s), especially if they occur after the learning algorithms have already converged onto a collaborative strategy. Current leading approaches in Multi-Agent Reinforcement Learning (MARL) often recover slowly -- if at all -- from such malfunctions. To overcome this limitation, we present the Collaborative Adaptation (CA) framework, highlighting its unique capability to operate in both continuous and discrete domains. Our framework enhances the adaptability of agents to unexpected failures by integrating inter-agent relationships into their learning processes, thereby accelerating the recovery from malfunctions. We evaluated our framework's performance through experiments in both discrete and continuous environments. Empirical results reveal that in scenarios involving unforeseen malfunction, although state-of-the-art algorithms often converge on sub-optimal solutions, the proposed CA framework mitigates and recovers more effectively.
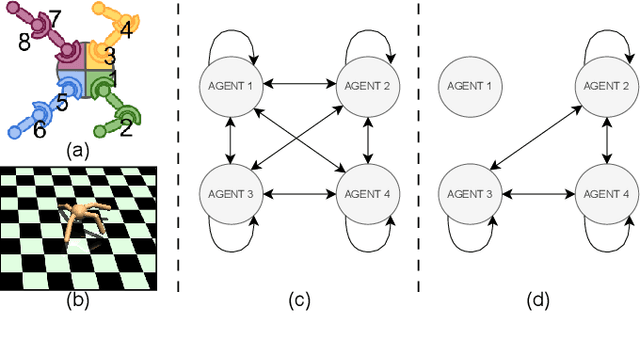
Relational Q-Functionals: Multi-Agent Learning to Recover from Unforeseen Robot Malfunctions in Continuous Action Domains
Jul 27, 2024



Cooperative multi-agent learning methods are essential in developing effective cooperation strategies in multi-agent domains. In robotics, these methods extend beyond multi-robot scenarios to single-robot systems, where they enable coordination among different robot modules (e.g., robot legs or joints). However, current methods often struggle to quickly adapt to unforeseen failures, such as a malfunctioning robot leg, especially after the algorithm has converged to a strategy. To overcome this, we introduce the Relational Q-Functionals (RQF) framework. RQF leverages a relational network, representing agents' relationships, to enhance adaptability, providing resilience against malfunction(s). Our algorithm also efficiently handles continuous state-action domains, making it adept for robotic learning tasks. Our empirical results show that RQF enables agents to use these relationships effectively to facilitate cooperation and recover from an unexpected malfunction in single-robot systems with multiple interacting modules. Thus, our approach offers promising applications in multi-agent systems, particularly in scenarios with unforeseen malfunctions.
Mixed Q-Functionals: Advancing Value-Based Methods in Cooperative MARL with Continuous Action Domains
Feb 12, 2024Tackling multi-agent learning problems efficiently is a challenging task in continuous action domains. While value-based algorithms excel in sample efficiency when applied to discrete action domains, they are usually inefficient when dealing with continuous actions. Policy-based algorithms, on the other hand, attempt to address this challenge by leveraging critic networks for guiding the learning process and stabilizing the gradient estimation. The limitations in the estimation of true return and falling into local optima in these methods result in inefficient and often sub-optimal policies. In this paper, we diverge from the trend of further enhancing critic networks, and focus on improving the effectiveness of value-based methods in multi-agent continuous domains by concurrently evaluating numerous actions. We propose a novel multi-agent value-based algorithm, Mixed Q-Functionals (MQF), inspired from the idea of Q-Functionals, that enables agents to transform their states into basis functions. Our algorithm fosters collaboration among agents by mixing their action-values. We evaluate the efficacy of our algorithm in six cooperative multi-agent scenarios. Our empirical findings reveal that MQF outperforms four variants of Deep Deterministic Policy Gradient through rapid action evaluation and increased sample efficiency.
Influence of Team Interactions on Multi-Robot Cooperation: A Relational Network Perspective
Oct 19, 2023



Relational networks within a team play a critical role in the performance of many real-world multi-robot systems. To successfully accomplish tasks that require cooperation and coordination, different agents (e.g., robots) necessitate different priorities based on their positioning within the team. Yet, many of the existing multi-robot cooperation algorithms regard agents as interchangeable and lack a mechanism to guide the type of cooperation strategy the agents should exhibit. To account for the team structure in cooperative tasks, we propose a novel algorithm that uses a relational network comprising inter-agent relationships to prioritize certain agents over others. Through appropriate design of the team's relational network, we can guide the cooperation strategy, resulting in the emergence of new behaviors that accomplish the specified task. We conducted six experiments in a multi-robot setting with a cooperative task. Our results demonstrate that the proposed method can effectively influence the type of solution that the algorithm converges to by specifying the relationships between the agents, making it a promising approach for tasks that require cooperation among agents with a specified team structure.
Impact of Relational Networks in Multi-Agent Learning: A Value-Based Factorization View
Oct 19, 2023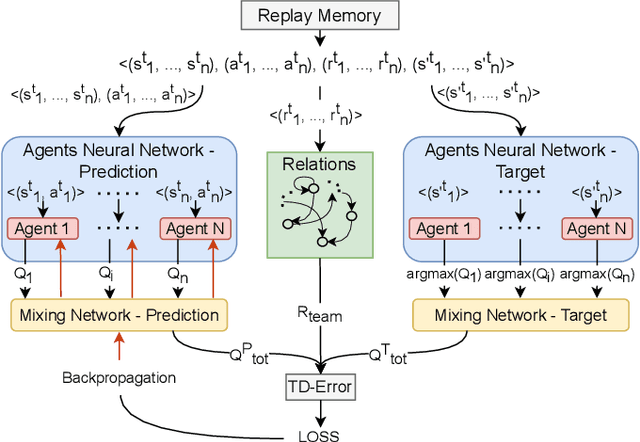
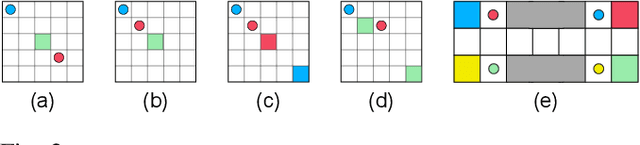
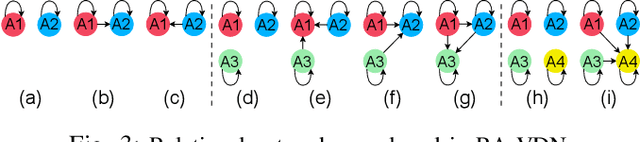
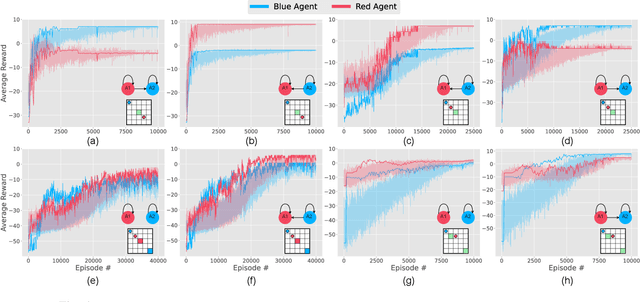
Effective coordination and cooperation among agents are crucial for accomplishing individual or shared objectives in multi-agent systems. In many real-world multi-agent systems, agents possess varying abilities and constraints, making it necessary to prioritize agents based on their specific properties to ensure successful coordination and cooperation within the team. However, most existing cooperative multi-agent algorithms do not take into account these individual differences, and lack an effective mechanism to guide coordination strategies. We propose a novel multi-agent learning approach that incorporates relationship awareness into value-based factorization methods. Given a relational network, our approach utilizes inter-agents relationships to discover new team behaviors by prioritizing certain agents over other, accounting for differences between them in cooperative tasks. We evaluated the effectiveness of our proposed approach by conducting fifteen experiments in two different environments. The results demonstrate that our proposed algorithm can influence and shape team behavior, guide cooperation strategies, and expedite agent learning. Therefore, our approach shows promise for use in multi-agent systems, especially when agents have diverse properties.
Collaborative Adaptation: Learning to Recover from Unforeseen Malfunctions in Multi-Robot Teams
Oct 19, 2023



Cooperative multi-agent reinforcement learning (MARL) approaches tackle the challenge of finding effective multi-agent cooperation strategies for accomplishing individual or shared objectives in multi-agent teams. In real-world scenarios, however, agents may encounter unforeseen failures due to constraints like battery depletion or mechanical issues. Existing state-of-the-art methods in MARL often recover slowly -- if at all -- from such malfunctions once agents have already converged on a cooperation strategy. To address this gap, we present the Collaborative Adaptation (CA) framework. CA introduces a mechanism that guides collaboration and accelerates adaptation from unforeseen failures by leveraging inter-agent relationships. Our findings demonstrate that CA enables agents to act on the knowledge of inter-agent relations, recovering from unforeseen agent failures and selecting appropriate cooperative strategies.
D-CBRS: Accounting For Intra-Class Diversity in Continual Learning
Jul 13, 2022


Continual learning -- accumulating knowledge from a sequence of learning experiences -- is an important yet challenging problem. In this paradigm, the model's performance for previously encountered instances may substantially drop as additional data are seen. When dealing with class-imbalanced data, forgetting is further exacerbated. Prior work has proposed replay-based approaches which aim at reducing forgetting by intelligently storing instances for future replay. Although Class-Balancing Reservoir Sampling (CBRS) has been successful in dealing with imbalanced data, the intra-class diversity has not been accounted for, implicitly assuming that each instance of a class is equally informative. We present Diverse-CBRS (D-CBRS), an algorithm that allows us to consider within class diversity when storing instances in the memory. Our results show that D-CBRS outperforms state-of-the-art memory management continual learning algorithms on data sets with considerable intra-class diversity.