 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDexWild: Dexterous Human Interactions for In-the-Wild Robot Policies
May 12, 2025Large-scale, diverse robot datasets have emerged as a promising path toward enabling dexterous manipulation policies to generalize to novel environments, but acquiring such datasets presents many challenges. While teleoperation provides high-fidelity datasets, its high cost limits its scalability. Instead, what if people could use their own hands, just as they do in everyday life, to collect data? In DexWild, a diverse team of data collectors uses their hands to collect hours of interactions across a multitude of environments and objects. To record this data, we create DexWild-System, a low-cost, mobile, and easy-to-use device. The DexWild learning framework co-trains on both human and robot demonstrations, leading to improved performance compared to training on each dataset individually. This combination results in robust robot policies capable of generalizing to novel environments, tasks, and embodiments with minimal additional robot-specific data. Experimental results demonstrate that DexWild significantly improves performance, achieving a 68.5% success rate in unseen environments-nearly four times higher than policies trained with robot data only-and offering 5.8x better cross-embodiment generalization. Video results, codebases, and instructions at https://dexwild.github.io
Policy Agnostic RL: Offline RL and Online RL Fine-Tuning of Any Class and Backbone
Dec 09, 2024Recent advances in learning decision-making policies can largely be attributed to training expressive policy models, largely via imitation learning. While imitation learning discards non-expert data, reinforcement learning (RL) can still learn from suboptimal data. However, instantiating RL training of a new policy class often presents a different challenge: most deep RL machinery is co-developed with assumptions on the policy class and backbone, resulting in poor performance when the policy class changes. For instance, SAC utilizes a low-variance reparameterization policy gradient for Gaussian policies, but this is unstable for diffusion policies and intractable for autoregressive categorical policies. To address this issue, we develop an offline RL and online fine-tuning approach called policy-agnostic RL (PA-RL) that can effectively train multiple policy classes, with varying architectures and sizes. We build off the basic idea that a universal supervised learning loss can replace the policy improvement step in RL, as long as it is applied on "optimized" actions. To obtain these optimized actions, we first sample multiple actions from a base policy, and run global optimization (i.e., re-ranking multiple action samples using the Q-function) and local optimization (i.e., running gradient steps on an action sample) to maximize the critic on these candidates. PA-RL enables fine-tuning diffusion and transformer policies with either autoregressive tokens or continuous action outputs, at different sizes, entirely via actor-critic RL. Moreover, PA-RL improves the performance and sample-efficiency by up to 2 times compared to existing offline RL and online fine-tuning methods. We show the first result that successfully fine-tunes OpenVLA, a 7B generalist robot policy, autonomously with Cal-QL, an online RL fine-tuning algorithm, improving from 40% to 70% in the real world in 40 minutes.
Bimanual Dexterity for Complex Tasks
Nov 20, 2024



To train generalist robot policies, machine learning methods often require a substantial amount of expert human teleoperation data. An ideal robot for humans collecting data is one that closely mimics them: bimanual arms and dexterous hands. However, creating such a bimanual teleoperation system with over 50 DoF is a significant challenge. To address this, we introduce Bidex, an extremely dexterous, low-cost, low-latency and portable bimanual dexterous teleoperation system which relies on motion capture gloves and teacher arms. We compare Bidex to a Vision Pro teleoperation system and a SteamVR system and find Bidex to produce better quality data for more complex tasks at a faster rate. Additionally, we show Bidex operating a mobile bimanual robot for in the wild tasks. The robot hands (5k USD) and teleoperation system (7k USD) is readily reproducible and can be used on many robot arms including two xArms (16k USD). Website at https://bidex-teleop.github.io/
The Ingredients for Robotic Diffusion Transformers
Oct 14, 2024In recent years roboticists have achieved remarkable progress in solving increasingly general tasks on dexterous robotic hardware by leveraging high capacity Transformer network architectures and generative diffusion models. Unfortunately, combining these two orthogonal improvements has proven surprisingly difficult, since there is no clear and well-understood process for making important design choices. In this paper, we identify, study and improve key architectural design decisions for high-capacity diffusion transformer policies. The resulting models can efficiently solve diverse tasks on multiple robot embodiments, without the excruciating pain of per-setup hyper-parameter tuning. By combining the results of our investigation with our improved model components, we are able to present a novel architecture, named \method, that significantly outperforms the state of the art in solving long-horizon ($1500+$ time-steps) dexterous tasks on a bi-manual ALOHA robot. In addition, we find that our policies show improved scaling performance when trained on 10 hours of highly multi-modal, language annotated ALOHA demonstration data. We hope this work will open the door for future robot learning techniques that leverage the efficiency of generative diffusion modeling with the scalability of large scale transformer architectures. Code, robot dataset, and videos are available at: https://dit-policy.github.io
HRP: Human Affordances for Robotic Pre-Training
Jul 26, 2024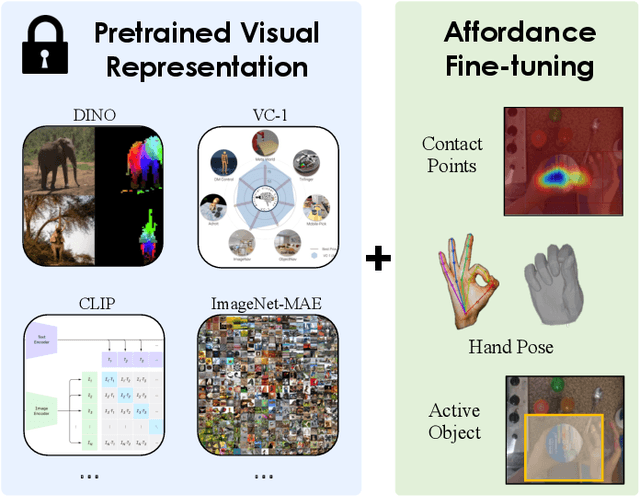
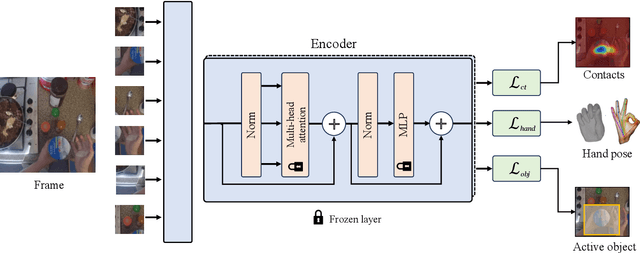
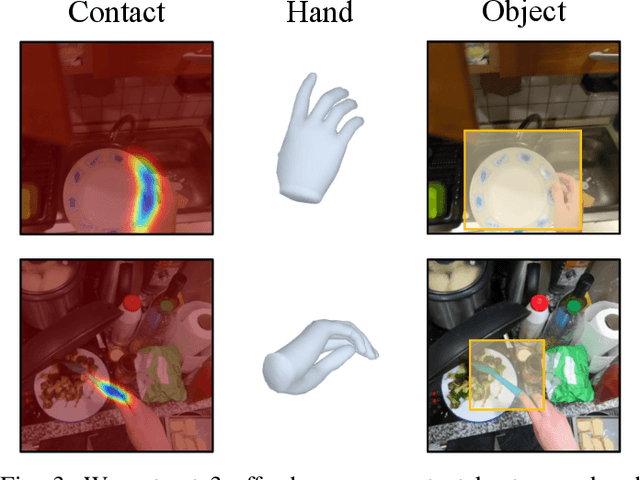
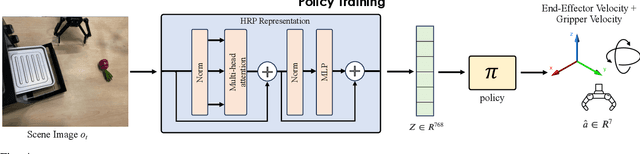
In order to *generalize* to various tasks in the wild, robotic agents will need a suitable representation (i.e., vision network) that enables the robot to predict optimal actions given high dimensional vision inputs. However, learning such a representation requires an extreme amount of diverse training data, which is prohibitively expensive to collect on a real robot. How can we overcome this problem? Instead of collecting more robot data, this paper proposes using internet-scale, human videos to extract "affordances," both at the environment and agent level, and distill them into a pre-trained representation. We present a simple framework for pre-training representations on hand, object, and contact "affordance labels" that highlight relevant objects in images and how to interact with them. These affordances are automatically extracted from human video data (with the help of off-the-shelf computer vision modules) and used to fine-tune existing representations. Our approach can efficiently fine-tune *any* existing representation, and results in models with stronger downstream robotic performance across the board. We experimentally demonstrate (using 3000+ robot trials) that this affordance pre-training scheme boosts performance by a minimum of 15% on 5 real-world tasks, which consider three diverse robot morphologies (including a dexterous hand). Unlike prior works in the space, these representations improve performance across 3 different camera views. Quantitatively, we find that our approach leads to higher levels of generalization in out-of-distribution settings. For code, weights, and data check: https://hrp-robot.github.io
DROID: A Large-Scale In-The-Wild Robot Manipulation Dataset
Mar 19, 2024



The creation of large, diverse, high-quality robot manipulation datasets is an important stepping stone on the path toward more capable and robust robotic manipulation policies. However, creating such datasets is challenging: collecting robot manipulation data in diverse environments poses logistical and safety challenges and requires substantial investments in hardware and human labour. As a result, even the most general robot manipulation policies today are mostly trained on data collected in a small number of environments with limited scene and task diversity. In this work, we introduce DROID (Distributed Robot Interaction Dataset), a diverse robot manipulation dataset with 76k demonstration trajectories or 350 hours of interaction data, collected across 564 scenes and 84 tasks by 50 data collectors in North America, Asia, and Europe over the course of 12 months. We demonstrate that training with DROID leads to policies with higher performance and improved generalization ability. We open source the full dataset, policy learning code, and a detailed guide for reproducing our robot hardware setup.
Open X-Embodiment: Robotic Learning Datasets and RT-X Models
Oct 17, 2023



Large, high-capacity models trained on diverse datasets have shown remarkable successes on efficiently tackling downstream applications. In domains from NLP to Computer Vision, this has led to a consolidation of pretrained models, with general pretrained backbones serving as a starting point for many applications. Can such a consolidation happen in robotics? Conventionally, robotic learning methods train a separate model for every application, every robot, and even every environment. Can we instead train generalist X-robot policy that can be adapted efficiently to new robots, tasks, and environments? In this paper, we provide datasets in standardized data formats and models to make it possible to explore this possibility in the context of robotic manipulation, alongside experimental results that provide an example of effective X-robot policies. We assemble a dataset from 22 different robots collected through a collaboration between 21 institutions, demonstrating 527 skills (160266 tasks). We show that a high-capacity model trained on this data, which we call RT-X, exhibits positive transfer and improves the capabilities of multiple robots by leveraging experience from other platforms. More details can be found on the project website $\href{https://robotics-transformer-x.github.io}{\text{robotics-transformer-x.github.io}}$.
An Unbiased Look at Datasets for Visuo-Motor Pre-Training
Oct 13, 2023Visual representation learning hold great promise for robotics, but is severely hampered by the scarcity and homogeneity of robotics datasets. Recent works address this problem by pre-training visual representations on large-scale but out-of-domain data (e.g., videos of egocentric interactions) and then transferring them to target robotics tasks. While the field is heavily focused on developing better pre-training algorithms, we find that dataset choice is just as important to this paradigm's success. After all, the representation can only learn the structures or priors present in the pre-training dataset. To this end, we flip the focus on algorithms, and instead conduct a dataset centric analysis of robotic pre-training. Our findings call into question some common wisdom in the field. We observe that traditional vision datasets (like ImageNet, Kinetics and 100 Days of Hands) are surprisingly competitive options for visuo-motor representation learning, and that the pre-training dataset's image distribution matters more than its size. Finally, we show that common simulation benchmarks are not a reliable proxy for real world performance and that simple regularization strategies can dramatically improve real world policy learning. https://data4robotics.github.io
Train Offline, Test Online: A Real Robot Learning Benchmark
Jun 01, 2023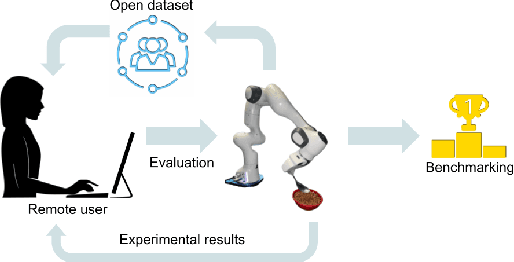
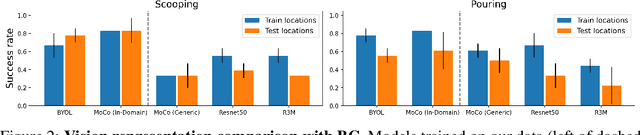
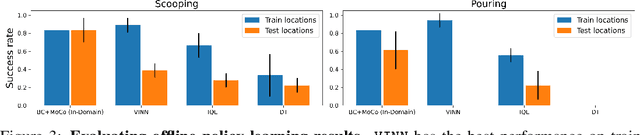

Three challenges limit the progress of robot learning research: robots are expensive (few labs can participate), everyone uses different robots (findings do not generalize across labs), and we lack internet-scale robotics data. We take on these challenges via a new benchmark: Train Offline, Test Online (TOTO). TOTO provides remote users with access to shared robotic hardware for evaluating methods on common tasks and an open-source dataset of these tasks for offline training. Its manipulation task suite requires challenging generalization to unseen objects, positions, and lighting. We present initial results on TOTO comparing five pretrained visual representations and four offline policy learning baselines, remotely contributed by five institutions. The real promise of TOTO, however, lies in the future: we release the benchmark for additional submissions from any user, enabling easy, direct comparison to several methods without the need to obtain hardware or collect data.
Manipulate by Seeing: Creating Manipulation Controllers from Pre-Trained Representations
Mar 15, 2023



The field of visual representation learning has seen explosive growth in the past years, but its benefits in robotics have been surprisingly limited so far. Prior work uses generic visual representations as a basis to learn (task-specific) robot action policies (e.g. via behavior cloning). While the visual representations do accelerate learning, they are primarily used to encode visual observations. Thus, action information has to be derived purely from robot data, which is expensive to collect! In this work, we present a scalable alternative where the visual representations can help directly infer robot actions. We observe that vision encoders express relationships between image observations as distances (e.g. via embedding dot product) that could be used to efficiently plan robot behavior. We operationalize this insight and develop a simple algorithm for acquiring a distance function and dynamics predictor, by fine-tuning a pre-trained representation on human collected video sequences. The final method is able to substantially outperform traditional robot learning baselines (e.g. 70% success v.s. 50% for behavior cloning on pick-place) on a suite of diverse real-world manipulation tasks. It can also generalize to novel objects, without using any robot demonstrations during train time. For visualizations of the learned policies please check: https://agi-labs.github.io/manipulate-by-seeing/