 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOPENTOUCH: Bringing Full-Hand Touch to Real-World Interaction
Dec 18, 2025The human hand is our primary interface to the physical world, yet egocentric perception rarely knows when, where, or how forcefully it makes contact. Robust wearable tactile sensors are scarce, and no existing in-the-wild datasets align first-person video with full-hand touch. To bridge the gap between visual perception and physical interaction, we present OpenTouch, the first in-the-wild egocentric full-hand tactile dataset, containing 5.1 hours of synchronized video-touch-pose data and 2,900 curated clips with detailed text annotations. Using OpenTouch, we introduce retrieval and classification benchmarks that probe how touch grounds perception and action. We show that tactile signals provide a compact yet powerful cue for grasp understanding, strengthen cross-modal alignment, and can be reliably retrieved from in-the-wild video queries. By releasing this annotated vision-touch-pose dataset and benchmark, we aim to advance multimodal egocentric perception, embodied learning, and contact-rich robotic manipulation.
Vision in Action: Learning Active Perception from Human Demonstrations
Jun 18, 2025We present Vision in Action (ViA), an active perception system for bimanual robot manipulation. ViA learns task-relevant active perceptual strategies (e.g., searching, tracking, and focusing) directly from human demonstrations. On the hardware side, ViA employs a simple yet effective 6-DoF robotic neck to enable flexible, human-like head movements. To capture human active perception strategies, we design a VR-based teleoperation interface that creates a shared observation space between the robot and the human operator. To mitigate VR motion sickness caused by latency in the robot's physical movements, the interface uses an intermediate 3D scene representation, enabling real-time view rendering on the operator side while asynchronously updating the scene with the robot's latest observations. Together, these design elements enable the learning of robust visuomotor policies for three complex, multi-stage bimanual manipulation tasks involving visual occlusions, significantly outperforming baseline systems.
Bimanual Dexterity for Complex Tasks
Nov 20, 2024



To train generalist robot policies, machine learning methods often require a substantial amount of expert human teleoperation data. An ideal robot for humans collecting data is one that closely mimics them: bimanual arms and dexterous hands. However, creating such a bimanual teleoperation system with over 50 DoF is a significant challenge. To address this, we introduce Bidex, an extremely dexterous, low-cost, low-latency and portable bimanual dexterous teleoperation system which relies on motion capture gloves and teacher arms. We compare Bidex to a Vision Pro teleoperation system and a SteamVR system and find Bidex to produce better quality data for more complex tasks at a faster rate. Additionally, we show Bidex operating a mobile bimanual robot for in the wild tasks. The robot hands (5k USD) and teleoperation system (7k USD) is readily reproducible and can be used on many robot arms including two xArms (16k USD). Website at https://bidex-teleop.github.io/
SPIN: Simultaneous Perception, Interaction and Navigation
May 13, 2024While there has been remarkable progress recently in the fields of manipulation and locomotion, mobile manipulation remains a long-standing challenge. Compared to locomotion or static manipulation, a mobile system must make a diverse range of long-horizon tasks feasible in unstructured and dynamic environments. While the applications are broad and interesting, there are a plethora of challenges in developing these systems such as coordination between the base and arm, reliance on onboard perception for perceiving and interacting with the environment, and most importantly, simultaneously integrating all these parts together. Prior works approach the problem using disentangled modular skills for mobility and manipulation that are trivially tied together. This causes several limitations such as compounding errors, delays in decision-making, and no whole-body coordination. In this work, we present a reactive mobile manipulation framework that uses an active visual system to consciously perceive and react to its environment. Similar to how humans leverage whole-body and hand-eye coordination, we develop a mobile manipulator that exploits its ability to move and see, more specifically -- to move in order to see and to see in order to move. This allows it to not only move around and interact with its environment but also, choose "when" to perceive "what" using an active visual system. We observe that such an agent learns to navigate around complex cluttered scenarios while displaying agile whole-body coordination using only ego-vision without needing to create environment maps. Results visualizations and videos at https://spin-robot.github.io/
Adaptive Mobile Manipulation for Articulated Objects In the Open World
Jan 28, 2024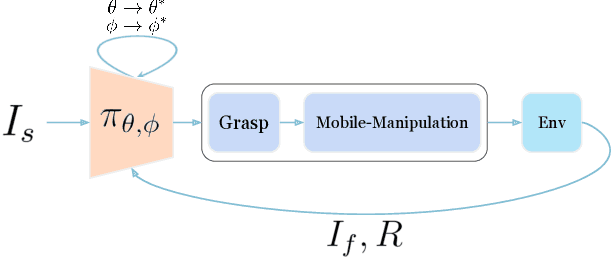
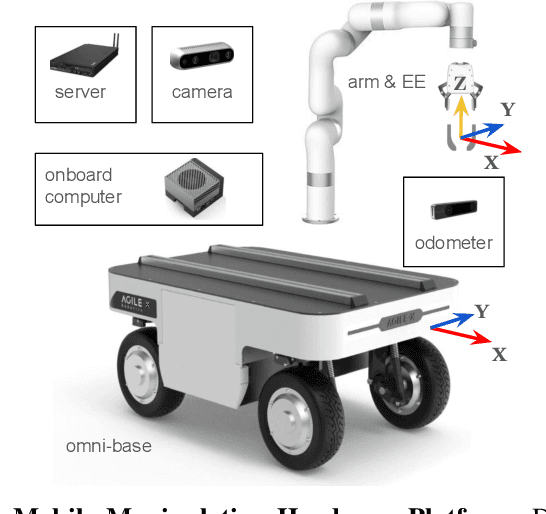

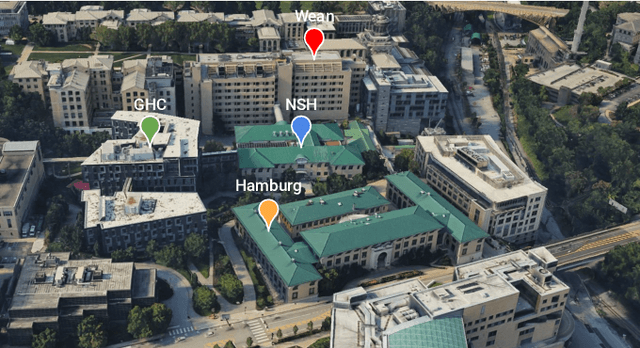
Deploying robots in open-ended unstructured environments such as homes has been a long-standing research problem. However, robots are often studied only in closed-off lab settings, and prior mobile manipulation work is restricted to pick-move-place, which is arguably just the tip of the iceberg in this area. In this paper, we introduce Open-World Mobile Manipulation System, a full-stack approach to tackle realistic articulated object operation, e.g. real-world doors, cabinets, drawers, and refrigerators in open-ended unstructured environments. The robot utilizes an adaptive learning framework to initially learns from a small set of data through behavior cloning, followed by learning from online practice on novel objects that fall outside the training distribution. We also develop a low-cost mobile manipulation hardware platform capable of safe and autonomous online adaptation in unstructured environments with a cost of around 20,000 USD. In our experiments we utilize 20 articulate objects across 4 buildings in the CMU campus. With less than an hour of online learning for each object, the system is able to increase success rate from 50% of BC pre-training to 95% using online adaptation. Video results at https://open-world-mobilemanip.github.io/
AMPLIFY:Attention-based Mixup for Performance Improvement and Label Smoothing in Transformer
Sep 22, 2023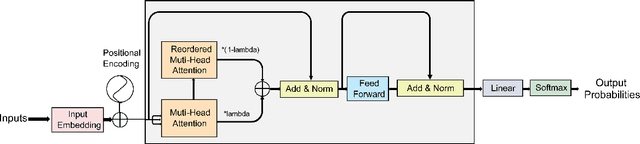
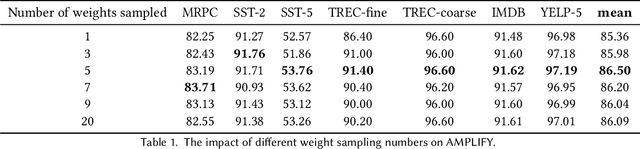
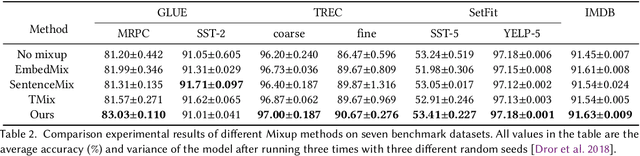
Mixup is an effective data augmentation method that generates new augmented samples by aggregating linear combinations of different original samples. However, if there are noises or aberrant features in the original samples, Mixup may propagate them to the augmented samples, leading to over-sensitivity of the model to these outliers . To solve this problem, this paper proposes a new Mixup method called AMPLIFY. This method uses the Attention mechanism of Transformer itself to reduce the influence of noises and aberrant values in the original samples on the prediction results, without increasing additional trainable parameters, and the computational cost is very low, thereby avoiding the problem of high resource consumption in common Mixup methods such as Sentence Mixup . The experimental results show that, under a smaller computational resource cost, AMPLIFY outperforms other Mixup methods in text classification tasks on 7 benchmark datasets, providing new ideas and new ways to further improve the performance of pre-trained models based on the Attention mechanism, such as BERT, ALBERT, RoBERTa, and GPT. Our code can be obtained at https://github.com/kiwi-lilo/AMPLIFY.
Learning by Watching: Physical Imitation of Manipulation Skills from Human Videos
Jan 18, 2021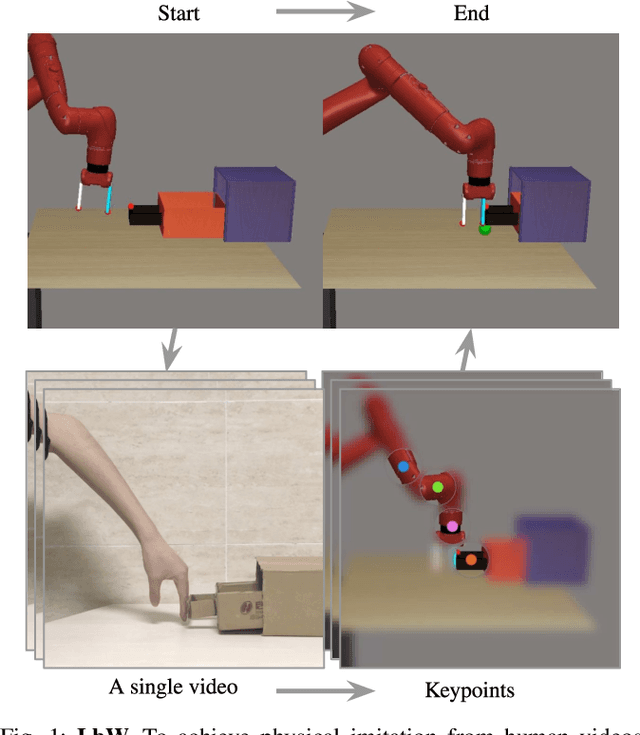
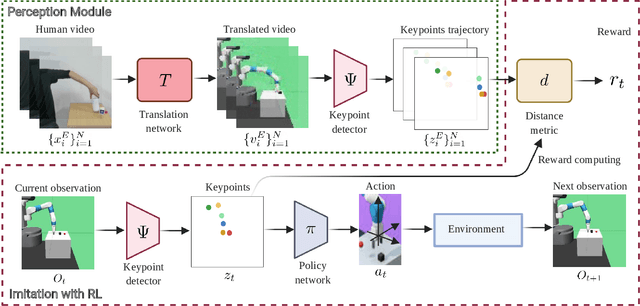
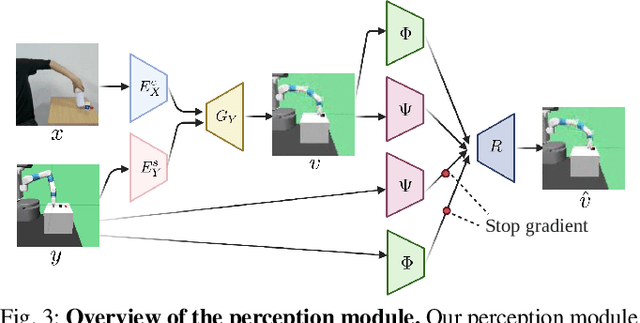

We present an approach for physical imitation from human videos for robot manipulation tasks. The key idea of our method lies in explicitly exploiting the kinematics and motion information embedded in the video to learn structured representations that endow the robot with the ability to imagine how to perform manipulation tasks in its own context. To achieve this, we design a perception module that learns to translate human videos to the robot domain followed by unsupervised keypoint detection. The resulting keypoint-based representations provide semantically meaningful information that can be directly used for reward computing and policy learning. We evaluate the effectiveness of our approach on five robot manipulation tasks, including reaching, pushing, sliding, coffee making, and drawer closing. Detailed experimental evaluations demonstrate that our method performs favorably against previous approaches.