 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIFG: Internet-Scale Guidance for Functional Grasping Generation
Nov 12, 2025



Large Vision Models trained on internet-scale data have demonstrated strong capabilities in segmenting and semantically understanding object parts, even in cluttered, crowded scenes. However, while these models can direct a robot toward the general region of an object, they lack the geometric understanding required to precisely control dexterous robotic hands for 3D grasping. To overcome this, our key insight is to leverage simulation with a force-closure grasping generation pipeline that understands local geometries of the hand and object in the scene. Because this pipeline is slow and requires ground-truth observations, the resulting data is distilled into a diffusion model that operates in real-time on camera point clouds. By combining the global semantic understanding of internet-scale models with the geometric precision of a simulation-based locally-aware force-closure, \our achieves high-performance semantic grasping without any manually collected training data. For visualizations of this please visit our website at https://ifgrasping.github.io/
Deep Reactive Policy: Learning Reactive Manipulator Motion Planning for Dynamic Environments
Sep 08, 2025Generating collision-free motion in dynamic, partially observable environments is a fundamental challenge for robotic manipulators. Classical motion planners can compute globally optimal trajectories but require full environment knowledge and are typically too slow for dynamic scenes. Neural motion policies offer a promising alternative by operating in closed-loop directly on raw sensory inputs but often struggle to generalize in complex or dynamic settings. We propose Deep Reactive Policy (DRP), a visuo-motor neural motion policy designed for reactive motion generation in diverse dynamic environments, operating directly on point cloud sensory input. At its core is IMPACT, a transformer-based neural motion policy pretrained on 10 million generated expert trajectories across diverse simulation scenarios. We further improve IMPACT's static obstacle avoidance through iterative student-teacher finetuning. We additionally enhance the policy's dynamic obstacle avoidance at inference time using DCP-RMP, a locally reactive goal-proposal module. We evaluate DRP on challenging tasks featuring cluttered scenes, dynamic moving obstacles, and goal obstructions. DRP achieves strong generalization, outperforming prior classical and neural methods in success rate across both simulated and real-world settings. Video results and code available at https://deep-reactive-policy.com
DexWild: Dexterous Human Interactions for In-the-Wild Robot Policies
May 12, 2025Large-scale, diverse robot datasets have emerged as a promising path toward enabling dexterous manipulation policies to generalize to novel environments, but acquiring such datasets presents many challenges. While teleoperation provides high-fidelity datasets, its high cost limits its scalability. Instead, what if people could use their own hands, just as they do in everyday life, to collect data? In DexWild, a diverse team of data collectors uses their hands to collect hours of interactions across a multitude of environments and objects. To record this data, we create DexWild-System, a low-cost, mobile, and easy-to-use device. The DexWild learning framework co-trains on both human and robot demonstrations, leading to improved performance compared to training on each dataset individually. This combination results in robust robot policies capable of generalizing to novel environments, tasks, and embodiments with minimal additional robot-specific data. Experimental results demonstrate that DexWild significantly improves performance, achieving a 68.5% success rate in unseen environments-nearly four times higher than policies trained with robot data only-and offering 5.8x better cross-embodiment generalization. Video results, codebases, and instructions at https://dexwild.github.io
FACTR: Force-Attending Curriculum Training for Contact-Rich Policy Learning
Feb 24, 2025



Many contact-rich tasks humans perform, such as box pickup or rolling dough, rely on force feedback for reliable execution. However, this force information, which is readily available in most robot arms, is not commonly used in teleoperation and policy learning. Consequently, robot behavior is often limited to quasi-static kinematic tasks that do not require intricate force-feedback. In this paper, we first present a low-cost, intuitive, bilateral teleoperation setup that relays external forces of the follower arm back to the teacher arm, facilitating data collection for complex, contact-rich tasks. We then introduce FACTR, a policy learning method that employs a curriculum which corrupts the visual input with decreasing intensity throughout training. The curriculum prevents our transformer-based policy from over-fitting to the visual input and guides the policy to properly attend to the force modality. We demonstrate that by fully utilizing the force information, our method significantly improves generalization to unseen objects by 43\% compared to baseline approaches without a curriculum. Video results and instructions at https://jasonjzliu.com/factr/
Bimanual Dexterity for Complex Tasks
Nov 20, 2024



To train generalist robot policies, machine learning methods often require a substantial amount of expert human teleoperation data. An ideal robot for humans collecting data is one that closely mimics them: bimanual arms and dexterous hands. However, creating such a bimanual teleoperation system with over 50 DoF is a significant challenge. To address this, we introduce Bidex, an extremely dexterous, low-cost, low-latency and portable bimanual dexterous teleoperation system which relies on motion capture gloves and teacher arms. We compare Bidex to a Vision Pro teleoperation system and a SteamVR system and find Bidex to produce better quality data for more complex tasks at a faster rate. Additionally, we show Bidex operating a mobile bimanual robot for in the wild tasks. The robot hands (5k USD) and teleoperation system (7k USD) is readily reproducible and can be used on many robot arms including two xArms (16k USD). Website at https://bidex-teleop.github.io/
SPIN: Simultaneous Perception, Interaction and Navigation
May 13, 2024While there has been remarkable progress recently in the fields of manipulation and locomotion, mobile manipulation remains a long-standing challenge. Compared to locomotion or static manipulation, a mobile system must make a diverse range of long-horizon tasks feasible in unstructured and dynamic environments. While the applications are broad and interesting, there are a plethora of challenges in developing these systems such as coordination between the base and arm, reliance on onboard perception for perceiving and interacting with the environment, and most importantly, simultaneously integrating all these parts together. Prior works approach the problem using disentangled modular skills for mobility and manipulation that are trivially tied together. This causes several limitations such as compounding errors, delays in decision-making, and no whole-body coordination. In this work, we present a reactive mobile manipulation framework that uses an active visual system to consciously perceive and react to its environment. Similar to how humans leverage whole-body and hand-eye coordination, we develop a mobile manipulator that exploits its ability to move and see, more specifically -- to move in order to see and to see in order to move. This allows it to not only move around and interact with its environment but also, choose "when" to perceive "what" using an active visual system. We observe that such an agent learns to navigate around complex cluttered scenarios while displaying agile whole-body coordination using only ego-vision without needing to create environment maps. Results visualizations and videos at https://spin-robot.github.io/
Adaptive Mobile Manipulation for Articulated Objects In the Open World
Jan 28, 2024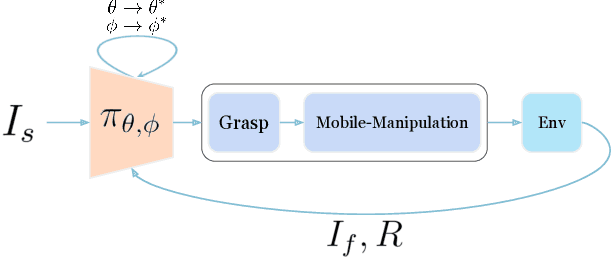
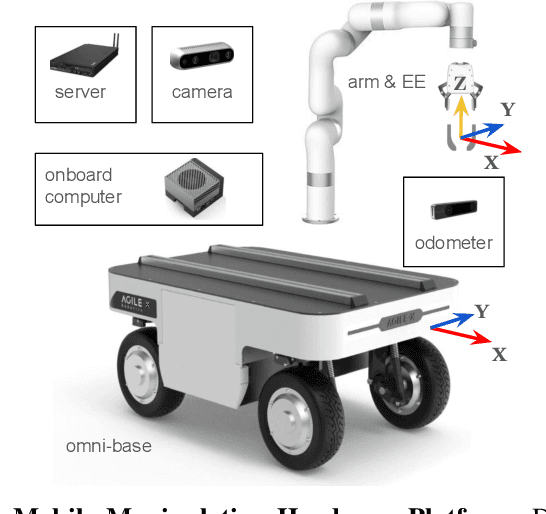

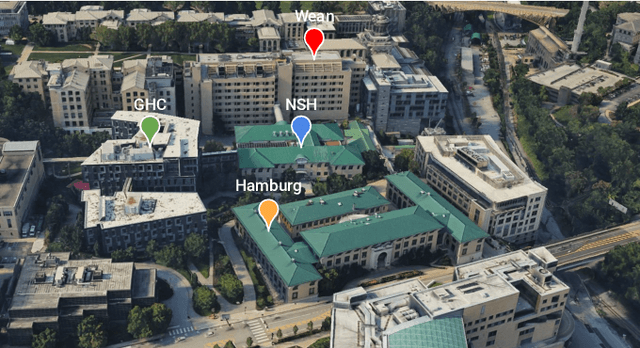
Deploying robots in open-ended unstructured environments such as homes has been a long-standing research problem. However, robots are often studied only in closed-off lab settings, and prior mobile manipulation work is restricted to pick-move-place, which is arguably just the tip of the iceberg in this area. In this paper, we introduce Open-World Mobile Manipulation System, a full-stack approach to tackle realistic articulated object operation, e.g. real-world doors, cabinets, drawers, and refrigerators in open-ended unstructured environments. The robot utilizes an adaptive learning framework to initially learns from a small set of data through behavior cloning, followed by learning from online practice on novel objects that fall outside the training distribution. We also develop a low-cost mobile manipulation hardware platform capable of safe and autonomous online adaptation in unstructured environments with a cost of around 20,000 USD. In our experiments we utilize 20 articulate objects across 4 buildings in the CMU campus. With less than an hour of online learning for each object, the system is able to increase success rate from 50% of BC pre-training to 95% using online adaptation. Video results at https://open-world-mobilemanip.github.io/
Dexterous Functional Grasping
Dec 05, 2023

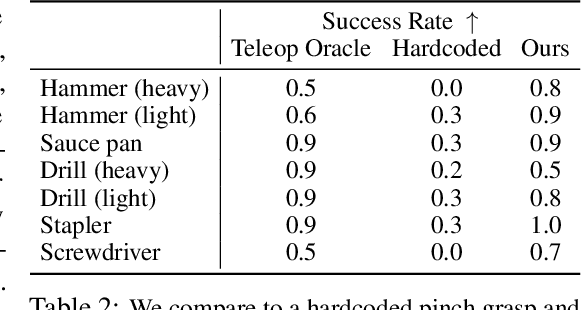
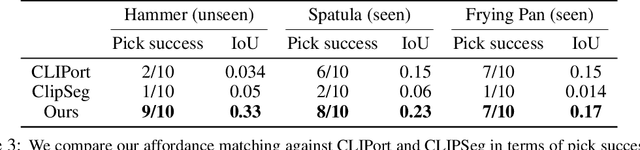
While there have been significant strides in dexterous manipulation, most of it is limited to benchmark tasks like in-hand reorientation which are of limited utility in the real world. The main benefit of dexterous hands over two-fingered ones is their ability to pickup tools and other objects (including thin ones) and grasp them firmly to apply force. However, this task requires both a complex understanding of functional affordances as well as precise low-level control. While prior work obtains affordances from human data this approach doesn't scale to low-level control. Similarly, simulation training cannot give the robot an understanding of real-world semantics. In this paper, we aim to combine the best of both worlds to accomplish functional grasping for in-the-wild objects. We use a modular approach. First, affordances are obtained by matching corresponding regions of different objects and then a low-level policy trained in sim is run to grasp it. We propose a novel application of eigengrasps to reduce the search space of RL using a small amount of human data and find that it leads to more stable and physically realistic motion. We find that eigengrasp action space beats baselines in simulation and outperforms hardcoded grasping in real and matches or outperforms a trained human teleoperator. Results visualizations and videos at https://dexfunc.github.io/
DEFT: Dexterous Fine-Tuning for Real-World Hand Policies
Oct 30, 2023
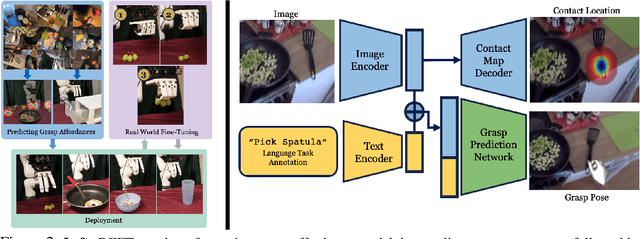
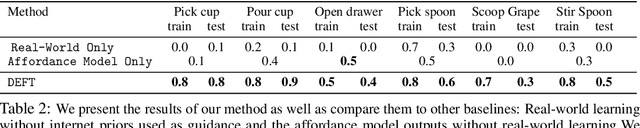

Dexterity is often seen as a cornerstone of complex manipulation. Humans are able to perform a host of skills with their hands, from making food to operating tools. In this paper, we investigate these challenges, especially in the case of soft, deformable objects as well as complex, relatively long-horizon tasks. However, learning such behaviors from scratch can be data inefficient. To circumvent this, we propose a novel approach, DEFT (DExterous Fine-Tuning for Hand Policies), that leverages human-driven priors, which are executed directly in the real world. In order to improve upon these priors, DEFT involves an efficient online optimization procedure. With the integration of human-based learning and online fine-tuning, coupled with a soft robotic hand, DEFT demonstrates success across various tasks, establishing a robust, data-efficient pathway toward general dexterous manipulation. Please see our website at https://dexterous-finetuning.github.io for video results.
LEAP Hand: Low-Cost, Efficient, and Anthropomorphic Hand for Robot Learning
Sep 12, 2023


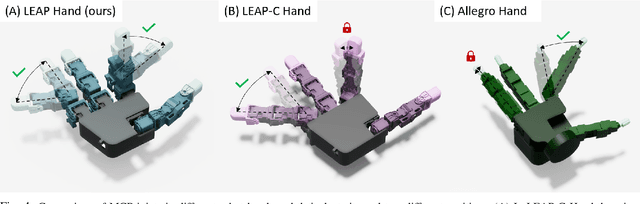
Dexterous manipulation has been a long-standing challenge in robotics. While machine learning techniques have shown some promise, results have largely been currently limited to simulation. This can be mostly attributed to the lack of suitable hardware. In this paper, we present LEAP Hand, a low-cost dexterous and anthropomorphic hand for machine learning research. In contrast to previous hands, LEAP Hand has a novel kinematic structure that allows maximal dexterity regardless of finger pose. LEAP Hand is low-cost and can be assembled in 4 hours at a cost of 2000 USD from readily available parts. It is capable of consistently exerting large torques over long durations of time. We show that LEAP Hand can be used to perform several manipulation tasks in the real world -- from visual teleoperation to learning from passive video data and sim2real. LEAP Hand significantly outperforms its closest competitor Allegro Hand in all our experiments while being 1/8th of the cost. We release detailed assembly instructions, the Sim2Real pipeline and a development platform with useful APIs on our website at https://leap-hand.github.io/