 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSPIN: Simultaneous Perception, Interaction and Navigation
May 13, 2024While there has been remarkable progress recently in the fields of manipulation and locomotion, mobile manipulation remains a long-standing challenge. Compared to locomotion or static manipulation, a mobile system must make a diverse range of long-horizon tasks feasible in unstructured and dynamic environments. While the applications are broad and interesting, there are a plethora of challenges in developing these systems such as coordination between the base and arm, reliance on onboard perception for perceiving and interacting with the environment, and most importantly, simultaneously integrating all these parts together. Prior works approach the problem using disentangled modular skills for mobility and manipulation that are trivially tied together. This causes several limitations such as compounding errors, delays in decision-making, and no whole-body coordination. In this work, we present a reactive mobile manipulation framework that uses an active visual system to consciously perceive and react to its environment. Similar to how humans leverage whole-body and hand-eye coordination, we develop a mobile manipulator that exploits its ability to move and see, more specifically -- to move in order to see and to see in order to move. This allows it to not only move around and interact with its environment but also, choose "when" to perceive "what" using an active visual system. We observe that such an agent learns to navigate around complex cluttered scenarios while displaying agile whole-body coordination using only ego-vision without needing to create environment maps. Results visualizations and videos at https://spin-robot.github.io/
Dexterous Functional Grasping
Dec 05, 2023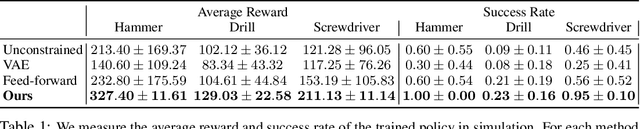

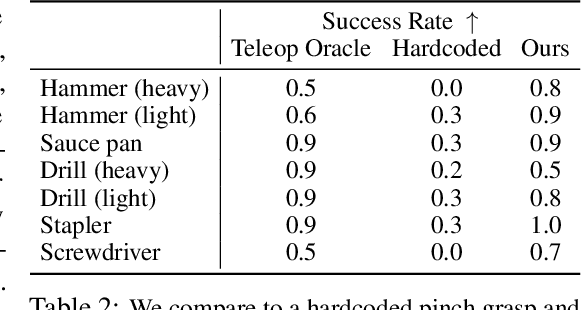
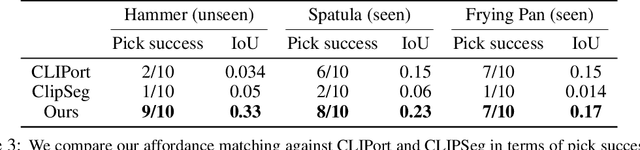
While there have been significant strides in dexterous manipulation, most of it is limited to benchmark tasks like in-hand reorientation which are of limited utility in the real world. The main benefit of dexterous hands over two-fingered ones is their ability to pickup tools and other objects (including thin ones) and grasp them firmly to apply force. However, this task requires both a complex understanding of functional affordances as well as precise low-level control. While prior work obtains affordances from human data this approach doesn't scale to low-level control. Similarly, simulation training cannot give the robot an understanding of real-world semantics. In this paper, we aim to combine the best of both worlds to accomplish functional grasping for in-the-wild objects. We use a modular approach. First, affordances are obtained by matching corresponding regions of different objects and then a low-level policy trained in sim is run to grasp it. We propose a novel application of eigengrasps to reduce the search space of RL using a small amount of human data and find that it leads to more stable and physically realistic motion. We find that eigengrasp action space beats baselines in simulation and outperforms hardcoded grasping in real and matches or outperforms a trained human teleoperator. Results visualizations and videos at https://dexfunc.github.io/
Emotionally Enhanced Talking Face Generation
Mar 26, 2023



Several works have developed end-to-end pipelines for generating lip-synced talking faces with various real-world applications, such as teaching and language translation in videos. However, these prior works fail to create realistic-looking videos since they focus little on people's expressions and emotions. Moreover, these methods' effectiveness largely depends on the faces in the training dataset, which means they may not perform well on unseen faces. To mitigate this, we build a talking face generation framework conditioned on a categorical emotion to generate videos with appropriate expressions, making them more realistic and convincing. With a broad range of six emotions, i.e., \emph{happiness}, \emph{sadness}, \emph{fear}, \emph{anger}, \emph{disgust}, and \emph{neutral}, we show that our model can adapt to arbitrary identities, emotions, and languages. Our proposed framework is equipped with a user-friendly web interface with a real-time experience for talking face generation with emotions. We also conduct a user study for subjective evaluation of our interface's usability, design, and functionality. Project page: https://midas.iiitd.edu.in/emo/
FaIRCoP: Facial Image Retrieval using Contrastive Personalization
May 28, 2022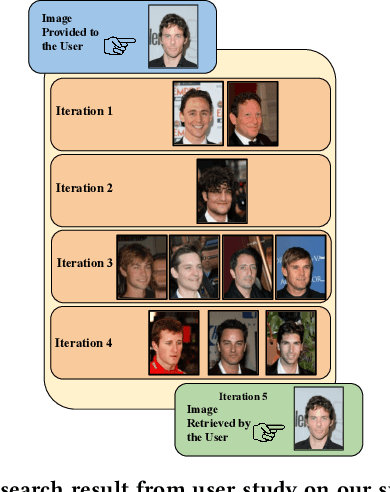
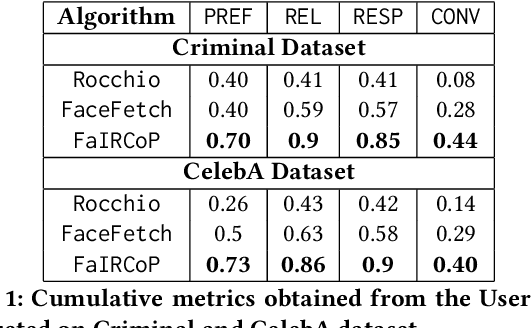

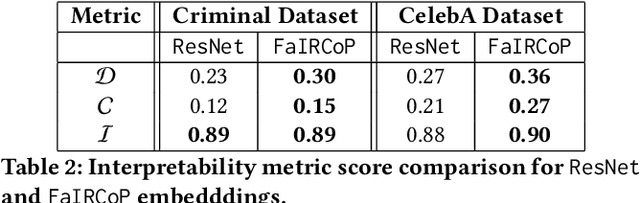
Retrieving facial images from attributes plays a vital role in various systems such as face recognition and suspect identification. Compared to other image retrieval tasks, facial image retrieval is more challenging due to the high subjectivity involved in describing a person's facial features. Existing methods do so by comparing specific characteristics from the user's mental image against the suggested images via high-level supervision such as using natural language. In contrast, we propose a method that uses a relatively simpler form of binary supervision by utilizing the user's feedback to label images as either similar or dissimilar to the target image. Such supervision enables us to exploit the contrastive learning paradigm for encapsulating each user's personalized notion of similarity. For this, we propose a novel loss function optimized online via user feedback. We validate the efficacy of our proposed approach using a carefully designed testbed to simulate user feedback and a large-scale user study. Our experiments demonstrate that our method iteratively improves personalization, leading to faster convergence and enhanced recommendation relevance, thereby, improving user satisfaction. Our proposed framework is also equipped with a user-friendly web interface with a real-time experience for facial image retrieval.
Distilling Motion Planner Augmented Policies into Visual Control Policies for Robot Manipulation
Nov 11, 2021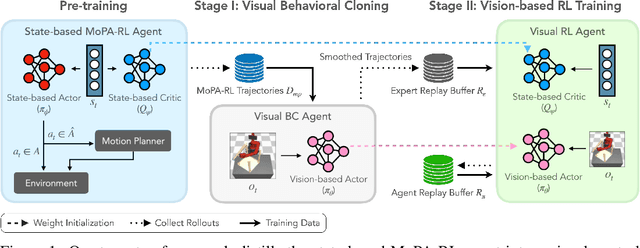
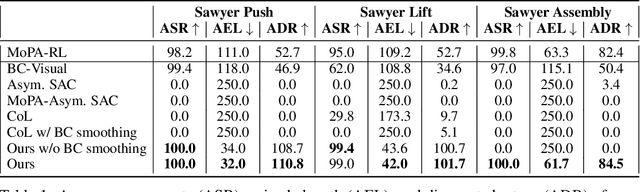
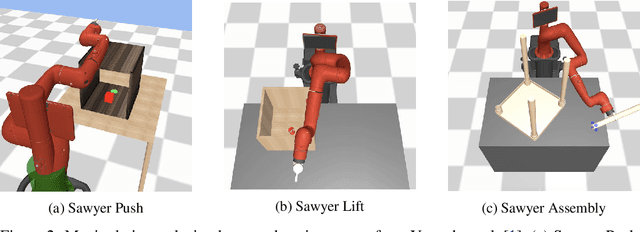

Learning complex manipulation tasks in realistic, obstructed environments is a challenging problem due to hard exploration in the presence of obstacles and high-dimensional visual observations. Prior work tackles the exploration problem by integrating motion planning and reinforcement learning. However, the motion planner augmented policy requires access to state information, which is often not available in the real-world settings. To this end, we propose to distill a state-based motion planner augmented policy to a visual control policy via (1) visual behavioral cloning to remove the motion planner dependency along with its jittery motion, and (2) vision-based reinforcement learning with the guidance of the smoothed trajectories from the behavioral cloning agent. We evaluate our method on three manipulation tasks in obstructed environments and compare it against various reinforcement learning and imitation learning baselines. The results demonstrate that our framework is highly sample-efficient and outperforms the state-of-the-art algorithms. Moreover, coupled with domain randomization, our policy is capable of zero-shot transfer to unseen environment settings with distractors. Code and videos are available at https://clvrai.com/mopa-pd
Emerging Trends of Multimodal Research in Vision and Language
Oct 19, 2020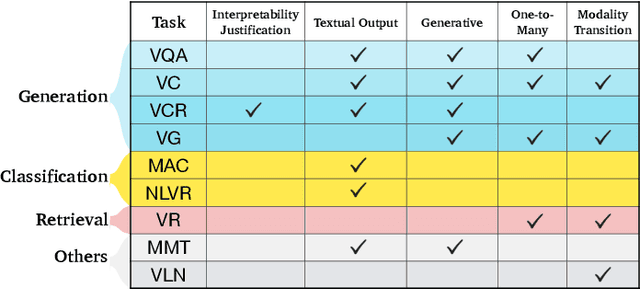
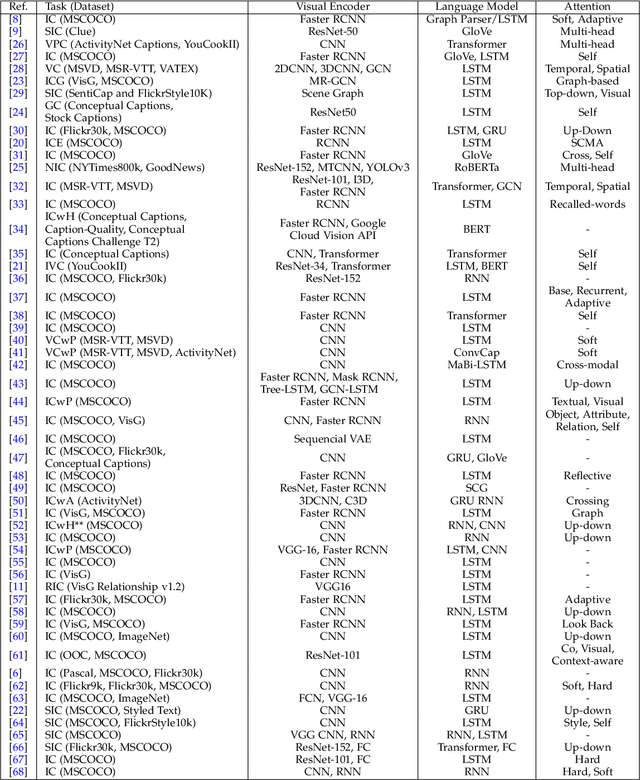
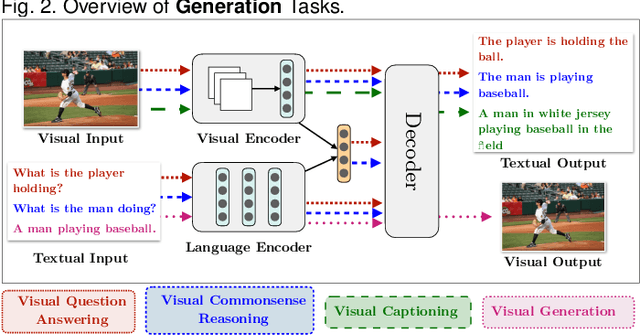
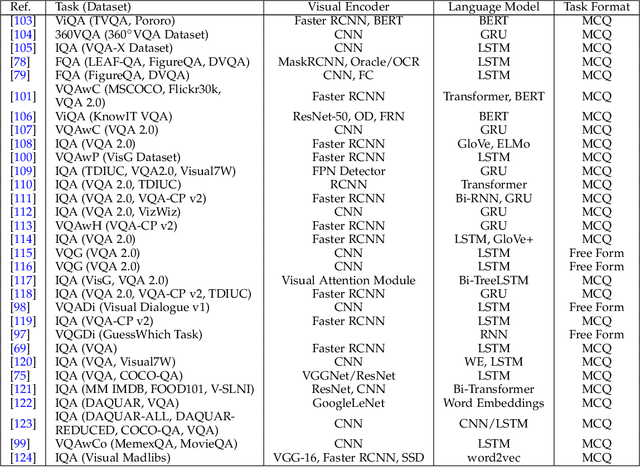
Deep Learning and its applications have cascaded impactful research and development with a diverse range of modalities present in the real-world data. More recently, this has enhanced research interests in the intersection of the Vision and Language arena with its numerous applications and fast-paced growth. In this paper, we present a detailed overview of the latest trends in research pertaining to visual and language modalities. We look at its applications in their task formulations and how to solve various problems related to semantic perception and content generation. We also address task-specific trends, along with their evaluation strategies and upcoming challenges. Moreover, we shed some light on multi-disciplinary patterns and insights that have emerged in the recent past, directing this field towards more modular and transparent intelligent systems. This survey identifies key trends gravitating recent literature in VisLang research and attempts to unearth directions that the field is heading towards.
DisCont: Self-Supervised Visual Attribute Disentanglement using Context Vectors
Jun 29, 2020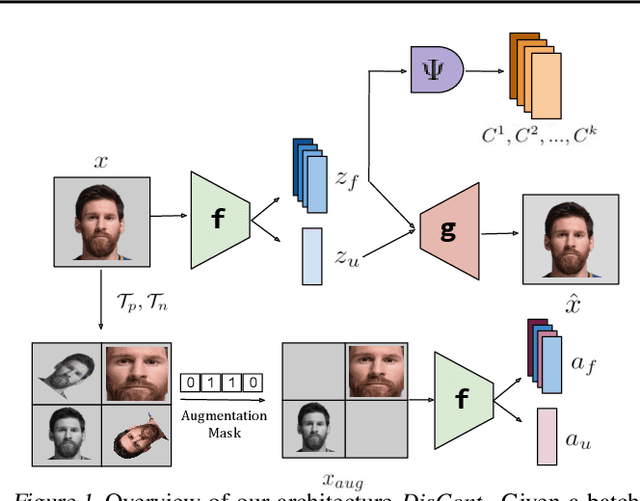
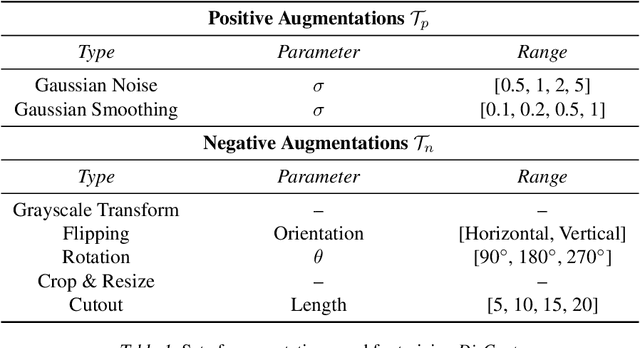


Disentangling the underlying feature attributes within an image with no prior supervision is a challenging task. Models that can disentangle attributes well provide greater interpretability and control. In this paper, we propose a self-supervised framework DisCont to disentangle multiple attributes by exploiting the structural inductive biases within images. Motivated by the recent surge in contrastive learning paradigms, our model bridges the gap between self-supervised contrastive learning algorithms and unsupervised disentanglement. We evaluate the efficacy of our approach, both qualitatively and quantitatively, on four benchmark datasets.
C3VQG: Category Consistent Cyclic Visual Question Generation
Jun 13, 2020
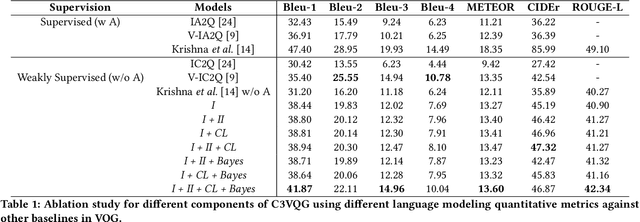
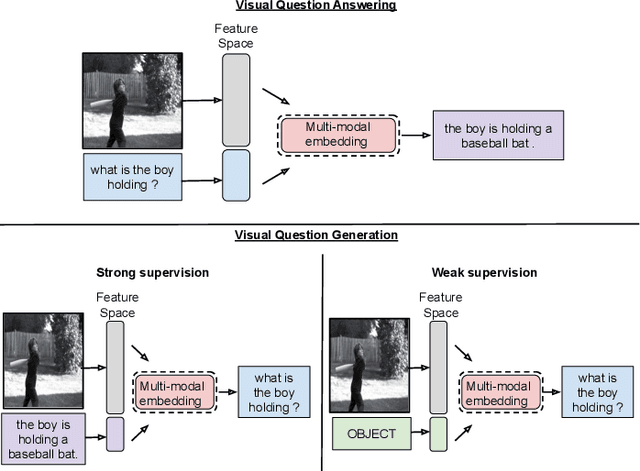
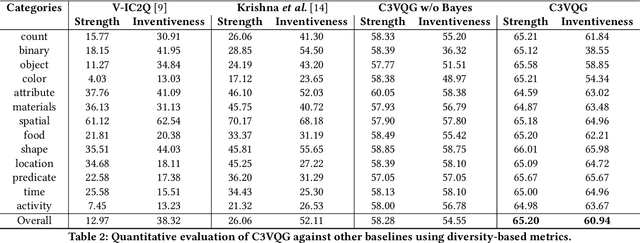
Visual Question Generation (VQG) is the task of generating natural questions based on an image. Popular methods in the past have explored image-to-sequence architectures trained with maximum likelihood which have demonstrated meaningful generated questions given an image and its associated ground-truth answer. VQG becomes more challenging if the image contains rich context information describing its different semantic categories. In this paper, we try to exploit the different visual cues and concepts in an image to generate questions using a variational autoencoder (VAE) without ground-truth answers. Our approach solves two major shortcomings of existing VQG systems: (i) minimize the level of supervision and (ii) replace generic questions with category relevant generations. Most importantly, through eliminating expensive answer annotations, the required supervision is weakened. Using different categories enables us to exploit different concepts as the inference requires only the image and category. Mutual information is maximized between the image, question, and answer category in the latent space of our VAE. A novel category consistent cyclic loss is proposed to enable the model to generate consistent predictions with respect to the answer category, reducing its redundancies and irregularities. Additionally, we also impose supplementary constraints on the latent space of our generative model to provide structure based on categories and enhance generalization by encapsulating decorrelated features within each dimension. Through extensive experiments, the proposed C3VQG outperforms the state-of-the-art visual question generation methods with weak supervision.
Disentangling Representations using Gaussian Processes in Variational Autoencoders for Video Prediction
Jan 08, 2020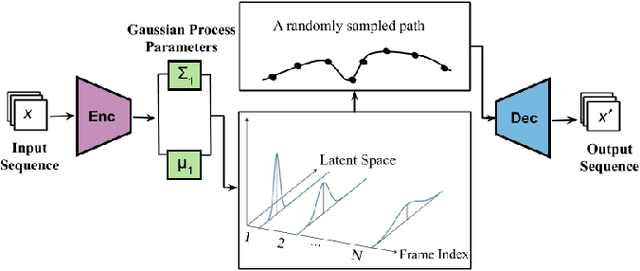
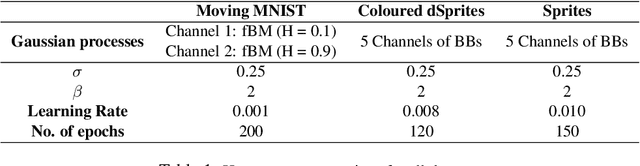
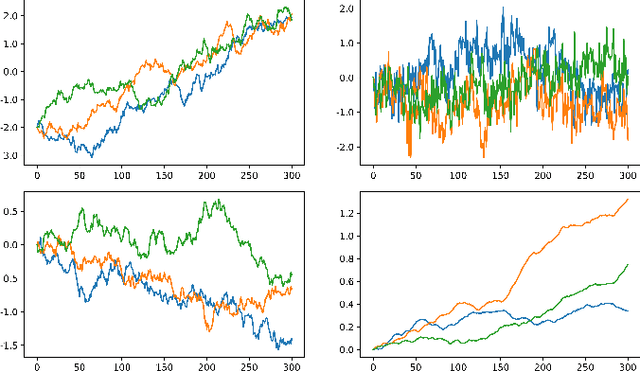
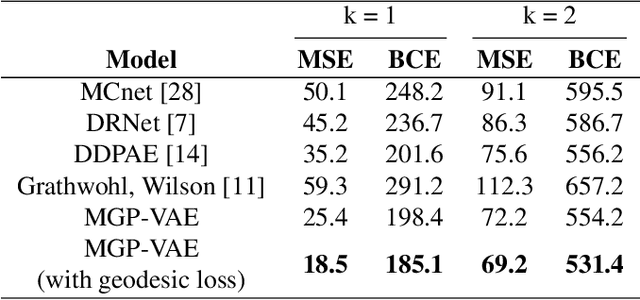
We introduce MGP-VAE, a variational autoencoder which uses Gaussian processes (GP) to model the latent space distribution. We employ MGP-VAE for the unsupervised learning of video sequences to obtain disentangled representations. Previous work in this area has mainly been confined to separating dynamic information from static content. We improve on previous results by establishing a framework by which multiple features, static or dynamic, can be disentangled. Specifically we use fractional Brownian motions (fBM) and Brownian bridges (BB) to enforce an inter-frame correlation structure in each independent channel. We show that varying this correlation structure enables one to capture different aspects of variation in the data. We demonstrate the quality of our disentangled representations on numerous experiments on three publicly available datasets, and also perform quantitative tests on a video prediction task. In addition, we introduce a novel geodesic loss function which takes into account the curvature of the data manifold to improve learning in the prediction task. Our experiments show quantitatively that the combination of our improved disentangled representations with the novel loss function enable MGP-VAE to outperform the state-of-the-art in video prediction.
Learning based Methods for Code Runtime Complexity Prediction
Nov 04, 2019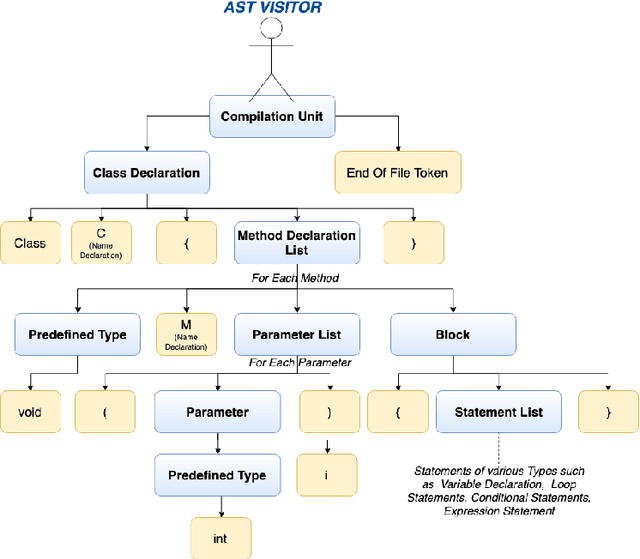
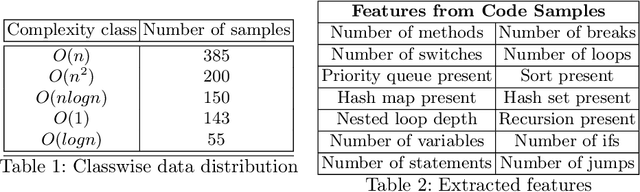
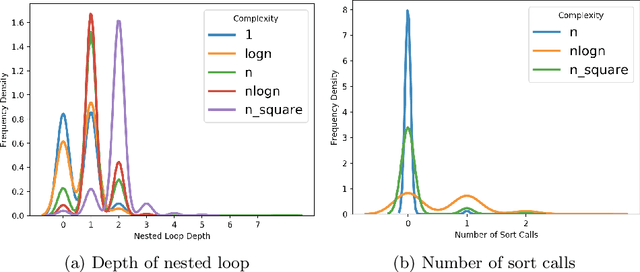
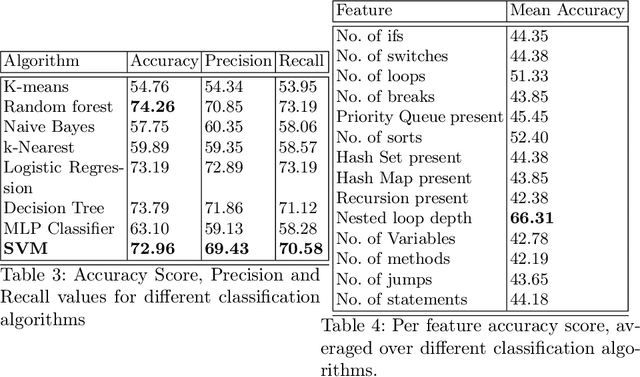
Predicting the runtime complexity of a programming code is an arduous task. In fact, even for humans, it requires a subtle analysis and comprehensive knowledge of algorithms to predict time complexity with high fidelity, given any code. As per Turing's Halting problem proof, estimating code complexity is mathematically impossible. Nevertheless, an approximate solution to such a task can help developers to get real-time feedback for the efficiency of their code. In this work, we model this problem as a machine learning task and check its feasibility with thorough analysis. Due to the lack of any open source dataset for this task, we propose our own annotated dataset CoRCoD: Code Runtime Complexity Dataset, extracted from online judges. We establish baselines using two different approaches: feature engineering and code embeddings, to achieve state of the art results and compare their performances. Such solutions can be widely useful in potential applications like automatically grading coding assignments, IDE-integrated tools for static code analysis, and others.