 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRoboflow100-VL: A Multi-Domain Object Detection Benchmark for Vision-Language Models
May 27, 2025Vision-language models (VLMs) trained on internet-scale data achieve remarkable zero-shot detection performance on common objects like car, truck, and pedestrian. However, state-of-the-art models still struggle to generalize to out-of-distribution classes, tasks and imaging modalities not typically found in their pre-training. Rather than simply re-training VLMs on more visual data, we argue that one should align VLMs to new concepts with annotation instructions containing a few visual examples and rich textual descriptions. To this end, we introduce Roboflow100-VL, a large-scale collection of 100 multi-modal object detection datasets with diverse concepts not commonly found in VLM pre-training. We evaluate state-of-the-art models on our benchmark in zero-shot, few-shot, semi-supervised, and fully-supervised settings, allowing for comparison across data regimes. Notably, we find that VLMs like GroundingDINO and Qwen2.5-VL achieve less than 2% zero-shot accuracy on challenging medical imaging datasets within Roboflow100-VL, demonstrating the need for few-shot concept alignment. Our code and dataset are available at https://github.com/roboflow/rf100-vl/ and https://universe.roboflow.com/rf100-vl/
Simultaneous Map and Object Reconstruction
Jun 19, 2024
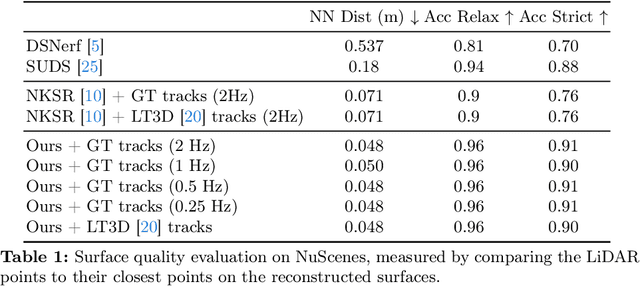

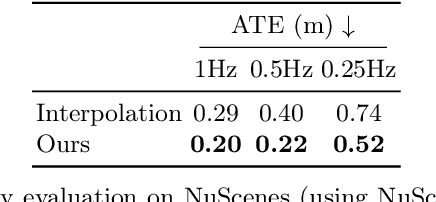
In this paper, we present a method for dynamic surface reconstruction of large-scale urban scenes from LiDAR. Depth-based reconstructions tend to focus on small-scale objects or large-scale SLAM reconstructions that treat moving objects as outliers. We take a holistic perspective and optimize a compositional model of a dynamic scene that decomposes the world into rigidly moving objects and the background. To achieve this, we take inspiration from recent novel view synthesis methods and pose the reconstruction problem as a global optimization, minimizing the distance between our predicted surface and the input LiDAR scans. We show how this global optimization can be decomposed into registration and surface reconstruction steps, which are handled well by off-the-shelf methods without any re-training. By careful modeling of continuous-time motion, our reconstructions can compensate for the rolling shutter effects of rotating LiDAR sensors. This allows for the first system (to our knowledge) that properly motion compensates LiDAR scans for rigidly-moving objects, complementing widely-used techniques for motion compensation of static scenes. Beyond pursuing dynamic reconstruction as a goal in and of itself, we also show that such a system can be used to auto-label partially annotated sequences and produce ground truth annotation for hard-to-label problems such as depth completion and scene flow.
NurtureNet: A Multi-task Video-based Approach for Newborn Anthropometry
May 09, 2024Malnutrition among newborns is a top public health concern in developing countries. Identification and subsequent growth monitoring are key to successful interventions. However, this is challenging in rural communities where health systems tend to be inaccessible and under-equipped, with poor adherence to protocol. Our goal is to equip health workers and public health systems with a solution for contactless newborn anthropometry in the community. We propose NurtureNet, a multi-task model that fuses visual information (a video taken with a low-cost smartphone) with tabular inputs to regress multiple anthropometry estimates including weight, length, head circumference, and chest circumference. We show that visual proxy tasks of segmentation and keypoint prediction further improve performance. We establish the efficacy of the model through several experiments and achieve a relative error of 3.9% and mean absolute error of 114.3 g for weight estimation. Model compression to 15 MB also allows offline deployment to low-cost smartphones.
Revisiting Few-Shot Object Detection with Vision-Language Models
Dec 22, 2023


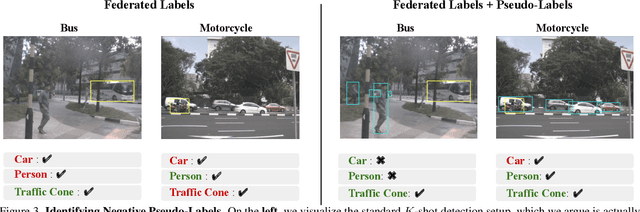
Few-shot object detection (FSOD) benchmarks have advanced techniques for detecting new categories with limited annotations. Existing benchmarks repurpose well-established datasets like COCO by partitioning categories into base and novel classes for pre-training and fine-tuning respectively. However, these benchmarks do not reflect how FSOD is deployed in practice. Rather than only pre-training on a small number of base categories, we argue that it is more practical to fine-tune a foundation model (e.g., a vision-language model (VLM) pre-trained on web-scale data) for a target domain. Surprisingly, we find that zero-shot inference from VLMs like GroundingDINO significantly outperforms the state-of-the-art (48.3 vs. 33.1 AP) on COCO. However, such zero-shot models can still be misaligned to target concepts of interest. For example, trailers on the web may be different from trailers in the context of autonomous vehicles. In this work, we propose Foundational FSOD, a new benchmark protocol that evaluates detectors pre-trained on any external datasets and fine-tuned on K-shots per target class. Further, we note that current FSOD benchmarks are actually federated datasets containing exhaustive annotations for each category on a subset of the data. We leverage this insight to propose simple strategies for fine-tuning VLMs with federated losses. We demonstrate the effectiveness of our approach on LVIS and nuImages, improving over prior work by 5.9 AP.
B-SMALL: A Bayesian Neural Network approach to Sparse Model-Agnostic Meta-Learning
Jan 01, 2021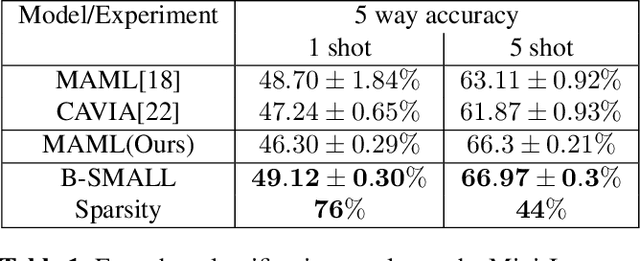

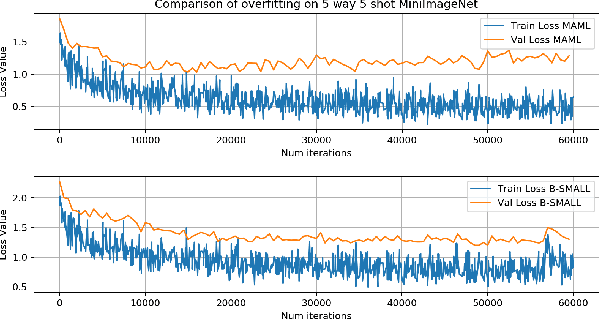
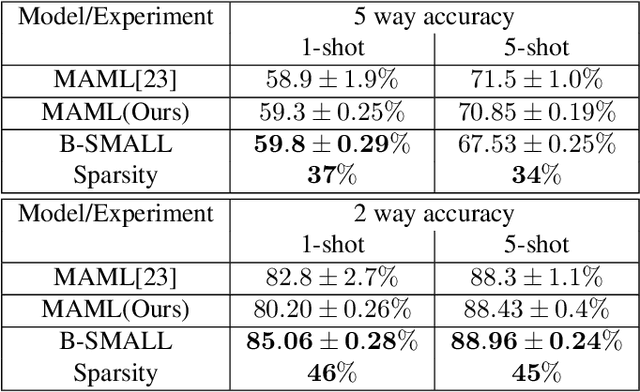
There is a growing interest in the learning-to-learn paradigm, also known as meta-learning, where models infer on new tasks using a few training examples. Recently, meta-learning based methods have been widely used in few-shot classification, regression, reinforcement learning, and domain adaptation. The model-agnostic meta-learning (MAML) algorithm is a well-known algorithm that obtains model parameter initialization at meta-training phase. In the meta-test phase, this initialization is rapidly adapted to new tasks by using gradient descent. However, meta-learning models are prone to overfitting since there are insufficient training tasks resulting in over-parameterized models with poor generalization performance for unseen tasks. In this paper, we propose a Bayesian neural network based MAML algorithm, which we refer to as the B-SMALL algorithm. The proposed framework incorporates a sparse variational loss term alongside the loss function of MAML, which uses a sparsifying approximated KL divergence as a regularizer. We demonstrate the performance of B-MAML using classification and regression tasks, and highlight that training a sparsifying BNN using MAML indeed improves the parameter footprint of the model while performing at par or even outperforming the MAML approach. We also illustrate applicability of our approach in distributed sensor networks, where sparsity and meta-learning can be beneficial.
Dissecting Deep Networks into an Ensemble of Generative Classifiers for Robust Predictions
Jun 18, 2020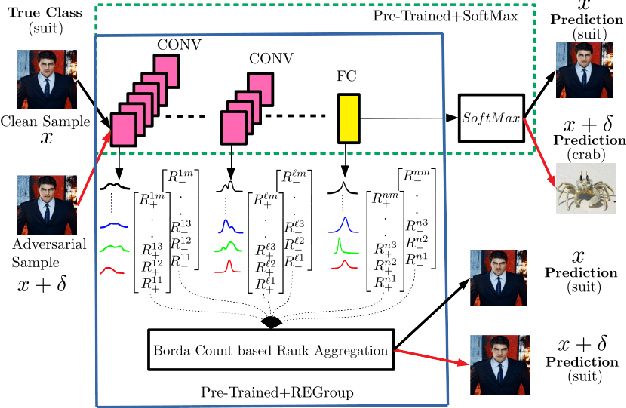
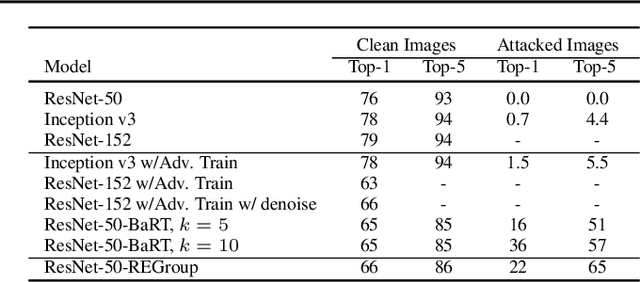
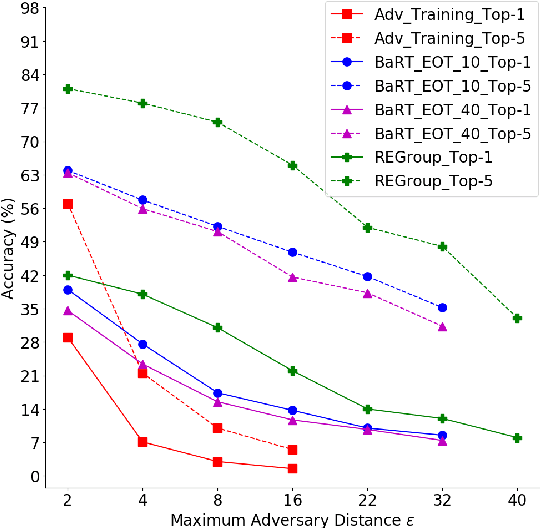
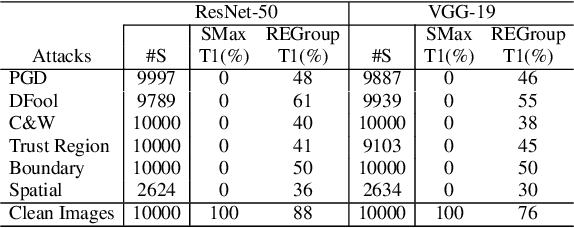
Deep Neural Networks (DNNs) are often criticized for being susceptible to adversarial attacks. Most successful defense strategies adopt adversarial training or random input transformations that typically require retraining or fine-tuning the model to achieve reasonable performance. In this work, our investigations of intermediate representations of a pre-trained DNN lead to an interesting discovery pointing to intrinsic robustness to adversarial attacks. We find that we can learn a generative classifier by statistically characterizing the neural response of an intermediate layer to clean training samples. The predictions of multiple such intermediate-layer based classifiers, when aggregated, show unexpected robustness to adversarial attacks. Specifically, we devise an ensemble of these generative classifiers that rank-aggregates their predictions via a Borda count-based consensus. Our proposed approach uses a subset of the clean training data and a pre-trained model, and yet is agnostic to network architectures or the adversarial attack generation method. We show extensive experiments to establish that our defense strategy achieves state-of-the-art performance on the ImageNet validation set.
C3VQG: Category Consistent Cyclic Visual Question Generation
Jun 13, 2020
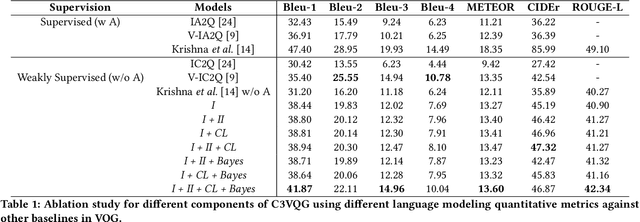
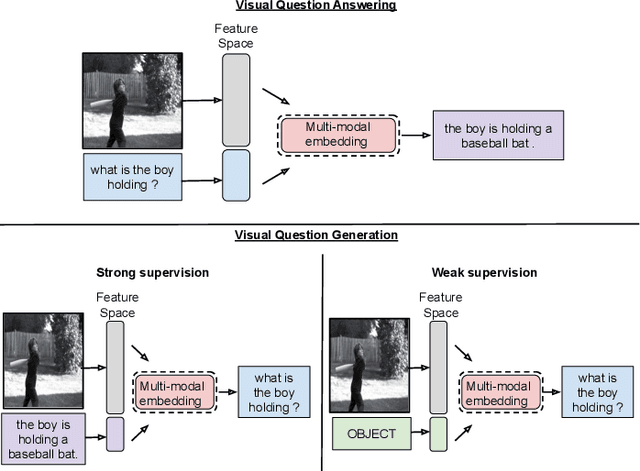
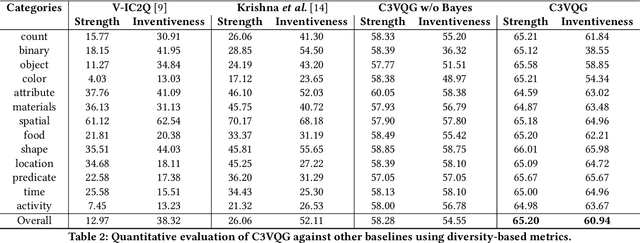
Visual Question Generation (VQG) is the task of generating natural questions based on an image. Popular methods in the past have explored image-to-sequence architectures trained with maximum likelihood which have demonstrated meaningful generated questions given an image and its associated ground-truth answer. VQG becomes more challenging if the image contains rich context information describing its different semantic categories. In this paper, we try to exploit the different visual cues and concepts in an image to generate questions using a variational autoencoder (VAE) without ground-truth answers. Our approach solves two major shortcomings of existing VQG systems: (i) minimize the level of supervision and (ii) replace generic questions with category relevant generations. Most importantly, through eliminating expensive answer annotations, the required supervision is weakened. Using different categories enables us to exploit different concepts as the inference requires only the image and category. Mutual information is maximized between the image, question, and answer category in the latent space of our VAE. A novel category consistent cyclic loss is proposed to enable the model to generate consistent predictions with respect to the answer category, reducing its redundancies and irregularities. Additionally, we also impose supplementary constraints on the latent space of our generative model to provide structure based on categories and enhance generalization by encapsulating decorrelated features within each dimension. Through extensive experiments, the proposed C3VQG outperforms the state-of-the-art visual question generation methods with weak supervision.