 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCLIP-Inspector: Model-Level Backdoor Detection for Prompt-Tuned CLIP via OOD Trigger Inversion
Apr 10, 2026Organisations with limited data and computational resources increasingly outsource model training to Machine Learning as a Service (MLaaS) providers, who adapt vision-language models (VLMs) such as CLIP to downstream tasks via prompt tuning rather than training from scratch. This semi-honest setting creates a security risk where a malicious provider can follow the prompt-tuning protocol yet implant a backdoor, forcing triggered inputs to be classified into an attacker-chosen class, even for out-of-distribution (OOD) data. Such backdoors leave encoders untouched, making them undetectable to existing methods that focus on encoder corruption. Other data-level methods that sanitize data before training or during inference, also fail to answer the critical question, "Is the delivered model backdoored or not?" To address this model-level verification problem, we introduce CLIP-Inspector (CI), a backdoor detection method designed for prompt-tuned CLIP models. Assuming white-box access to the delivered model and a pool of unlabeled OOD images, CI reconstructs possible triggers for each class to determine if the model exhibits backdoor behaviour or not. Additionally, we demonstrate that using CI's reconstructed trigger for fine-tuning on correctly labeled triggered inputs enables us to re-align the model and reduce backdoor effectiveness. Through extensive experiments across ten datasets and four backdoor attacks, we demonstrate that CI can reconstruct effective triggers in a single epoch using only 1,000 OOD images, achieving a 94% detection accuracy (47/50 models). Compared to adapted trigger-inversion baselines, CI yields a markedly higher AUROC score (0.973 vs 0.495/0.687), thus enabling the vetting and post-hoc repair of prompt-tuned CLIP models to ensure safe deployment.
Active Learning for Animal Re-Identification with Ambiguity-Aware Sampling
Nov 11, 2025Animal Re-ID has recently gained substantial attention in the AI research community due to its high impact on biodiversity monitoring and unique research challenges arising from environmental factors. The subtle distinguishing patterns, handling new species and the inherent open-set nature make the problem even harder. To address these complexities, foundation models trained on labeled, large-scale and multi-species animal Re-ID datasets have recently been introduced to enable zero-shot Re-ID. However, our benchmarking reveals significant gaps in their zero-shot Re-ID performance for both known and unknown species. While this highlights the need for collecting labeled data in new domains, exhaustive annotation for Re-ID is laborious and requires domain expertise. Our analyses show that existing unsupervised (USL) and AL Re-ID methods underperform for animal Re-ID. To address these limitations, we introduce a novel AL Re-ID framework that leverages complementary clustering methods to uncover and target structurally ambiguous regions in the embedding space for mining pairs of samples that are both informative and broadly representative. Oracle feedback on these pairs, in the form of must-link and cannot-link constraints, facilitates a simple annotation interface, which naturally integrates with existing USL methods through our proposed constrained clustering refinement algorithm. Through extensive experiments, we demonstrate that, by utilizing only 0.033% of all annotations, our approach consistently outperforms existing foundational, USL and AL baselines. Specifically, we report an average improvement of 10.49%, 11.19% and 3.99% (mAP) on 13 wildlife datasets over foundational, USL and AL methods, respectively, while attaining state-of-the-art performance on each dataset. Furthermore, we also show an improvement of 11.09%, 8.2% and 2.06% for unknown individuals in an open-world setting.
Learning and Evaluating Hierarchical Feature Representations
Mar 10, 2025Hierarchy-aware representations ensure that the semantically closer classes are mapped closer in the feature space, thereby reducing the severity of mistakes while enabling consistent coarse-level class predictions. Towards this end, we propose a novel framework, Hierarchical Composition of Orthogonal Subspaces (Hier-COS), which learns to map deep feature embeddings into a vector space that is, by design, consistent with the structure of a given taxonomy tree. Our approach augments neural network backbones with a simple transformation module that maps learned discriminative features to subspaces defined using a fixed orthogonal frame. This construction naturally improves the severity of mistakes and promotes hierarchical consistency. Furthermore, we highlight the fundamental limitations of existing hierarchical evaluation metrics popularly used by the vision community and introduce a preference-based metric, Hierarchically Ordered Preference Score (HOPS), to overcome these limitations. We benchmark our method on multiple large and challenging datasets having deep label hierarchies (ranging from 3 - 12 levels) and compare with several baselines and SOTA. Through extensive experiments, we demonstrate that Hier-COS achieves state-of-the-art hierarchical performance across all the datasets while simultaneously beating top-1 accuracy in all but one case. We also demonstrate the performance of a Vision Transformer (ViT) backbone and show that learning a transformation module alone can map the learned features from a pre-trained ViT to Hier-COS and yield substantial performance benefits.
Graph-Based Multi-Modal Sensor Fusion for Autonomous Driving
Nov 06, 2024
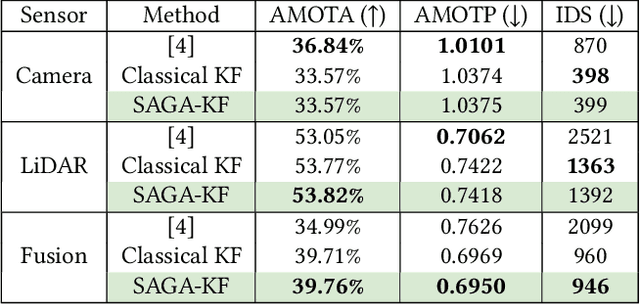
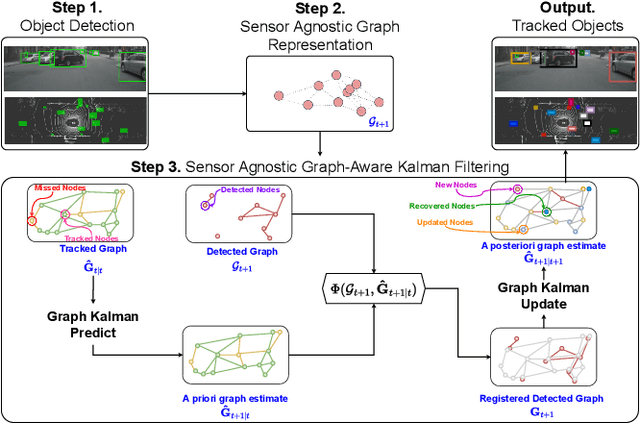
The growing demand for robust scene understanding in mobile robotics and autonomous driving has highlighted the importance of integrating multiple sensing modalities. By combining data from diverse sensors like cameras and LIDARs, fusion techniques can overcome the limitations of individual sensors, enabling a more complete and accurate perception of the environment. We introduce a novel approach to multi-modal sensor fusion, focusing on developing a graph-based state representation that supports critical decision-making processes in autonomous driving. We present a Sensor-Agnostic Graph-Aware Kalman Filter [3], the first online state estimation technique designed to fuse multi-modal graphs derived from noisy multi-sensor data. The estimated graph-based state representations serve as a foundation for advanced applications like Multi-Object Tracking (MOT), offering a comprehensive framework for enhancing the situational awareness and safety of autonomous systems. We validate the effectiveness of our proposed framework through extensive experiments conducted on both synthetic and real-world driving datasets (nuScenes). Our results showcase an improvement in MOTA and a reduction in estimated position errors (MOTP) and identity switches (IDS) for tracked objects using the SAGA-KF. Furthermore, we highlight the capability of such a framework to develop methods that can leverage heterogeneous information (like semantic objects and geometric structures) from various sensing modalities, enabling a more holistic approach to scene understanding and enhancing the safety and effectiveness of autonomous systems.
SICKLE: A Multi-Sensor Satellite Imagery Dataset Annotated with Multiple Key Cropping Parameters
Nov 29, 2023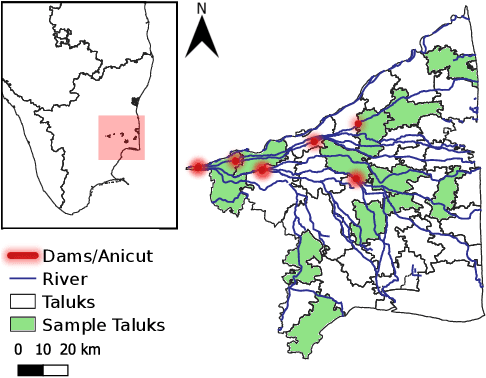
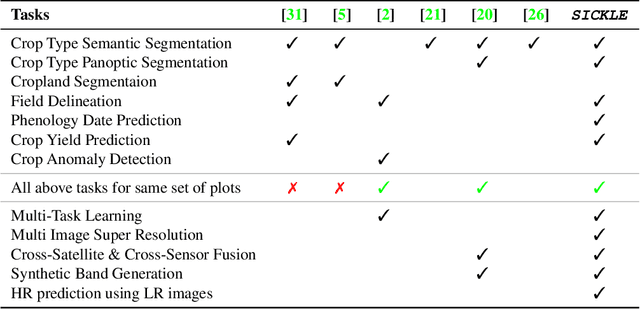
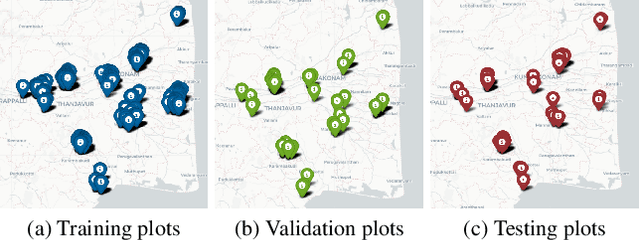
The availability of well-curated datasets has driven the success of Machine Learning (ML) models. Despite greater access to earth observation data in agriculture, there is a scarcity of curated and labelled datasets, which limits the potential of its use in training ML models for remote sensing (RS) in agriculture. To this end, we introduce a first-of-its-kind dataset called SICKLE, which constitutes a time-series of multi-resolution imagery from 3 distinct satellites: Landsat-8, Sentinel-1 and Sentinel-2. Our dataset constitutes multi-spectral, thermal and microwave sensors during January 2018 - March 2021 period. We construct each temporal sequence by considering the cropping practices followed by farmers primarily engaged in paddy cultivation in the Cauvery Delta region of Tamil Nadu, India; and annotate the corresponding imagery with key cropping parameters at multiple resolutions (i.e. 3m, 10m and 30m). Our dataset comprises 2,370 season-wise samples from 388 unique plots, having an average size of 0.38 acres, for classifying 21 crop types across 4 districts in the Delta, which amounts to approximately 209,000 satellite images. Out of the 2,370 samples, 351 paddy samples from 145 plots are annotated with multiple crop parameters; such as the variety of paddy, its growing season and productivity in terms of per-acre yields. Ours is also one among the first studies that consider the growing season activities pertinent to crop phenology (spans sowing, transplanting and harvesting dates) as parameters of interest. We benchmark SICKLE on three tasks: crop type, crop phenology (sowing, transplanting, harvesting), and yield prediction
Army of Thieves: Enhancing Black-Box Model Extraction via Ensemble based sample selection
Nov 08, 2023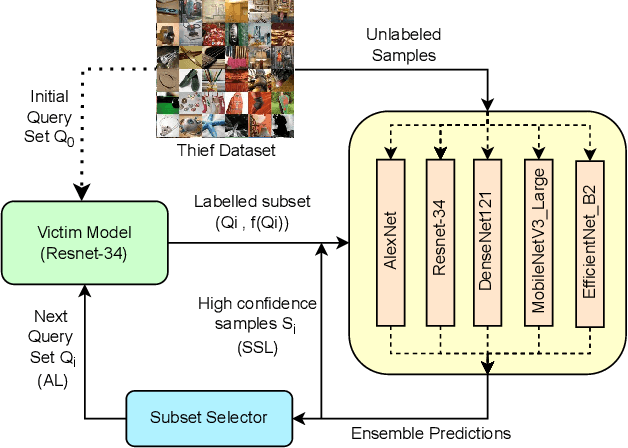
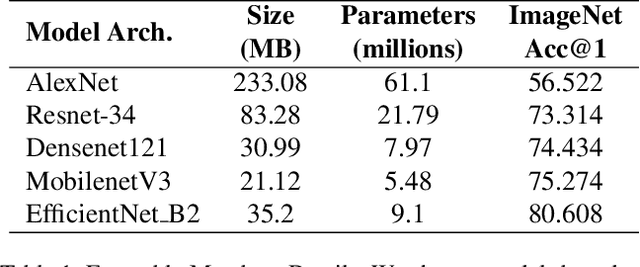

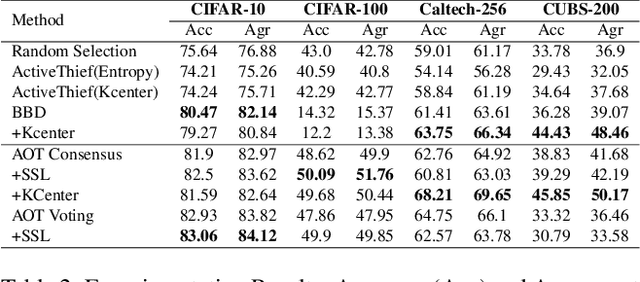
Machine Learning (ML) models become vulnerable to Model Stealing Attacks (MSA) when they are deployed as a service. In such attacks, the deployed model is queried repeatedly to build a labelled dataset. This dataset allows the attacker to train a thief model that mimics the original model. To maximize query efficiency, the attacker has to select the most informative subset of data points from the pool of available data. Existing attack strategies utilize approaches like Active Learning and Semi-Supervised learning to minimize costs. However, in the black-box setting, these approaches may select sub-optimal samples as they train only one thief model. Depending on the thief model's capacity and the data it was pretrained on, the model might even select noisy samples that harm the learning process. In this work, we explore the usage of an ensemble of deep learning models as our thief model. We call our attack Army of Thieves(AOT) as we train multiple models with varying complexities to leverage the crowd's wisdom. Based on the ensemble's collective decision, uncertain samples are selected for querying, while the most confident samples are directly included in the training data. Our approach is the first one to utilize an ensemble of thief models to perform model extraction. We outperform the base approaches of existing state-of-the-art methods by at least 3% and achieve a 21% higher adversarial sample transferability than previous work for models trained on the CIFAR-10 dataset.
Reducing Annotation Effort by Identifying and Labeling Contextually Diverse Classes for Semantic Segmentation Under Domain Shift
Oct 13, 2022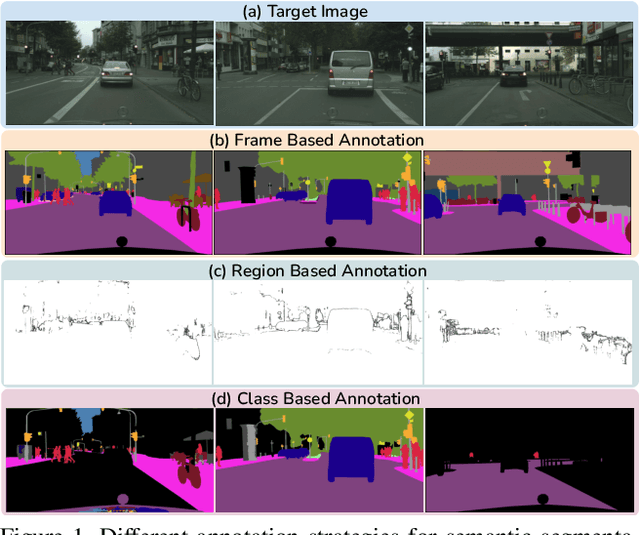
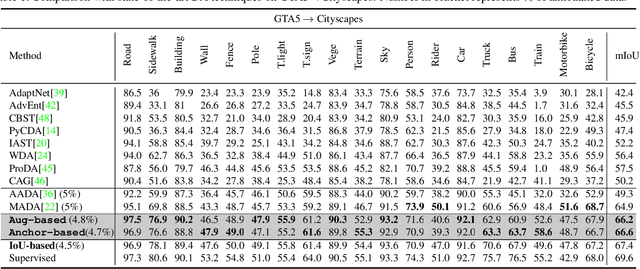
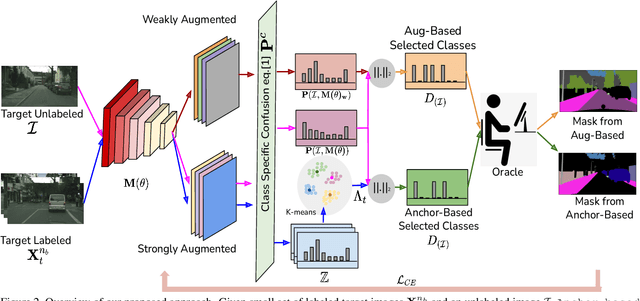
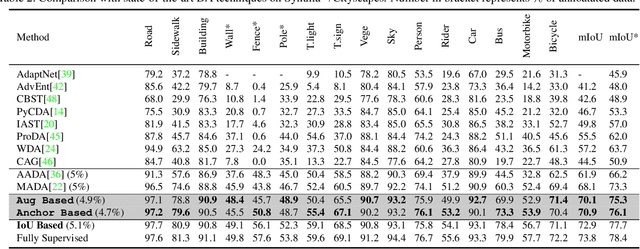
In Active Domain Adaptation (ADA), one uses Active Learning (AL) to select a subset of images from the target domain, which are then annotated and used for supervised domain adaptation (DA). Given the large performance gap between supervised and unsupervised DA techniques, ADA allows for an excellent trade-off between annotation cost and performance. Prior art makes use of measures of uncertainty or disagreement of models to identify `regions' to be annotated by the human oracle. However, these regions frequently comprise of pixels at object boundaries which are hard and tedious to annotate. Hence, even if the fraction of image pixels annotated reduces, the overall annotation time and the resulting cost still remain high. In this work, we propose an ADA strategy, which given a frame, identifies a set of classes that are hardest for the model to predict accurately, thereby recommending semantically meaningful regions to be annotated in a selected frame. We show that these set of `hard' classes are context-dependent and typically vary across frames, and when annotated help the model generalize better. We propose two ADA techniques: the Anchor-based and Augmentation-based approaches to select complementary and diverse regions in the context of the current training set. Our approach achieves 66.6 mIoU on GTA to Cityscapes dataset with an annotation budget of 4.7% in comparison to 64.9 mIoU by MADA using 5% of annotations. Our technique can also be used as a decorator for any existing frame-based AL technique, e.g., we report 1.5% performance improvement for CDAL on Cityscapes using our approach.
High-Resolution Satellite Imagery for Modeling the Impact of Aridification on Crop Production
Sep 25, 2022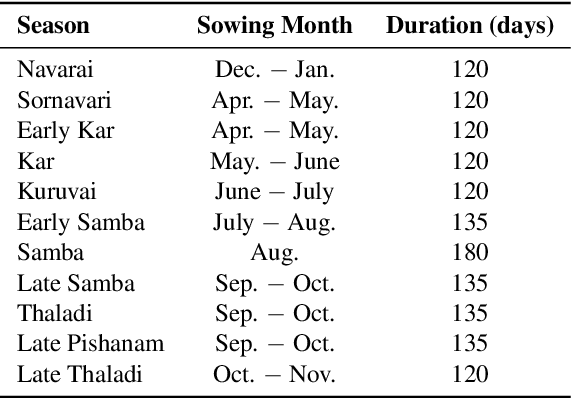
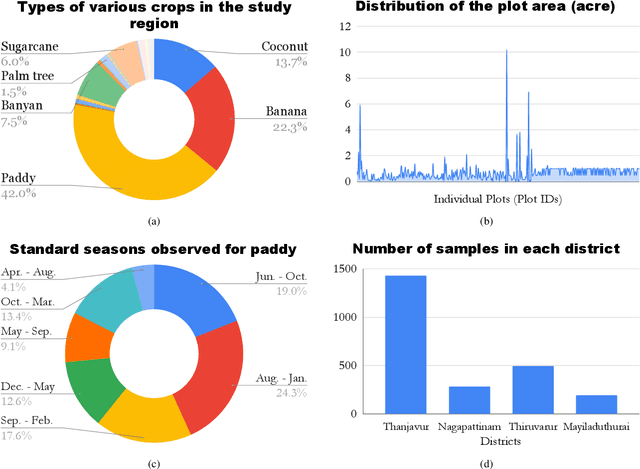

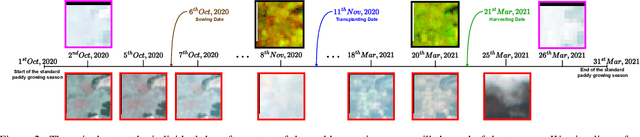
The availability of well-curated datasets has driven the success of Machine Learning (ML) models. Despite the increased access to earth observation data for agriculture, there is a scarcity of curated, labelled datasets, which limits the potential of its use in training ML models for remote sensing (RS) in agriculture. To this end, we introduce a first-of-its-kind dataset, SICKLE, having time-series images at different spatial resolutions from 3 different satellites, annotated with multiple key cropping parameters for paddy cultivation for the Cauvery Delta region in Tamil Nadu, India. The dataset comprises of 2,398 season-wise samples from 388 unique plots distributed across 4 districts of the Delta. The dataset covers multi-spectral, thermal and microwave data between the time period January 2018-March 2021. The paddy samples are annotated with 4 key cropping parameters, i.e. sowing date, transplanting date, harvesting date and crop yield. This is one of the first studies to consider the growing season (using sowing and harvesting dates) as part of a dataset. We also propose a yield prediction strategy that uses time-series data generated based on the observed growing season and the standard seasonal information obtained from Tamil Nadu Agricultural University for the region. The consequent performance improvement highlights the impact of ML techniques that leverage domain knowledge that are consistent with standard practices followed by farmers in a specific region. We benchmark the dataset on 3 separate tasks, namely crop type, phenology date (sowing, transplanting, harvesting) and yield prediction, and develop an end-to-end framework for predicting key crop parameters in a real-world setting.
Learning Hierarchy Aware Features for Reducing Mistake Severity
Jul 26, 2022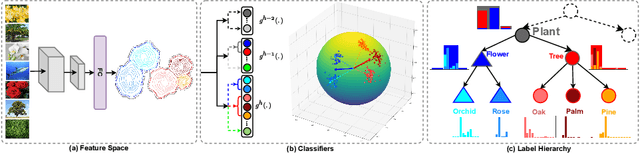

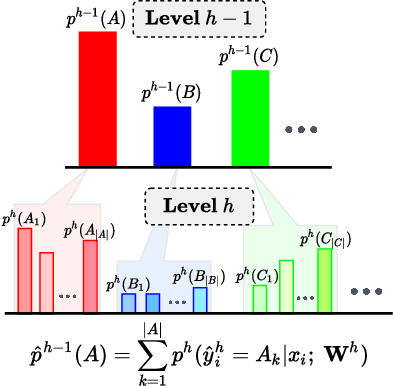
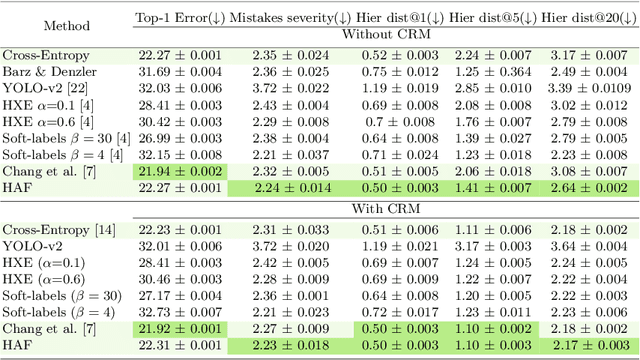
Label hierarchies are often available apriori as part of biological taxonomy or language datasets WordNet. Several works exploit these to learn hierarchy aware features in order to improve the classifier to make semantically meaningful mistakes while maintaining or reducing the overall error. In this paper, we propose a novel approach for learning Hierarchy Aware Features (HAF) that leverages classifiers at each level of the hierarchy that are constrained to generate predictions consistent with the label hierarchy. The classifiers are trained by minimizing a Jensen-Shannon Divergence with target soft labels obtained from the fine-grained classifiers. Additionally, we employ a simple geometric loss that constrains the feature space geometry to capture the semantic structure of the label space. HAF is a training time approach that improves the mistakes while maintaining top-1 error, thereby, addressing the problem of cross-entropy loss that treats all mistakes as equal. We evaluate HAF on three hierarchical datasets and achieve state-of-the-art results on the iNaturalist-19 and CIFAR-100 datasets. The source code is available at https://github.com/07Agarg/HAF
Crop Type Identification for Smallholding Farms: Analyzing Spatial, Temporal and Spectral Resolutions in Satellite Imagery
May 06, 2022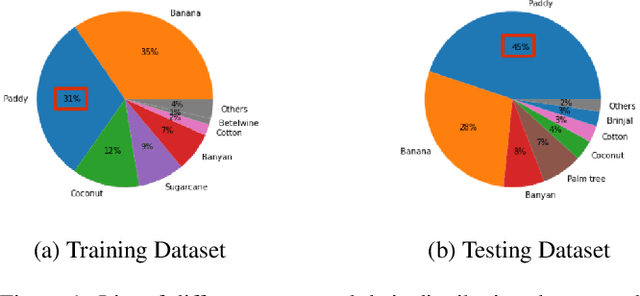
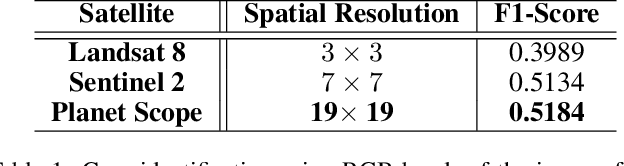
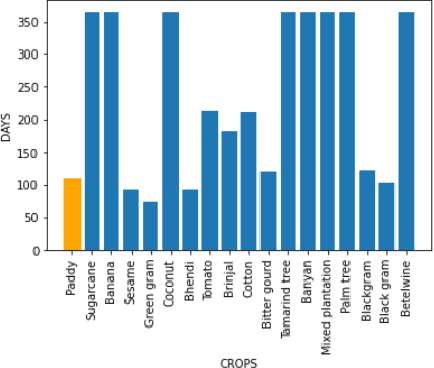
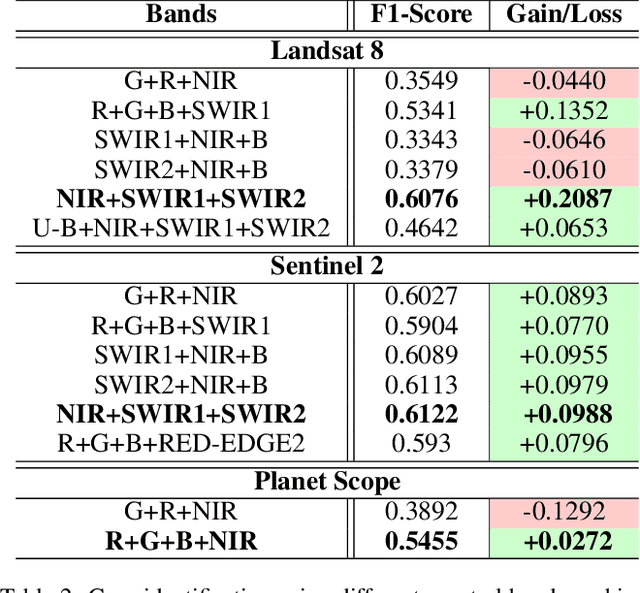
The integration of the modern Machine Learning (ML) models into remote sensing and agriculture has expanded the scope of the application of satellite images in the agriculture domain. In this paper, we present how the accuracy of crop type identification improves as we move from medium-spatiotemporal-resolution (MSTR) to high-spatiotemporal-resolution (HSTR) satellite images. We further demonstrate that high spectral resolution in satellite imagery can improve prediction performance for low spatial and temporal resolutions (LSTR) images. The F1-score is increased by 7% when using multispectral data of MSTR images as compared to the best results obtained from HSTR images. Similarly, when crop season based time series of multispectral data is used we observe an increase of 1.2% in the F1-score. The outcome motivates further advancements in the field of synthetic band generation.