 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHIERMATCH: Leveraging Label Hierarchies for Improving Semi-Supervised Learning
Oct 30, 2021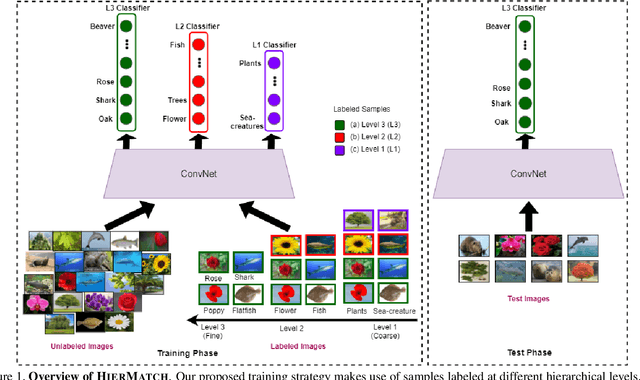
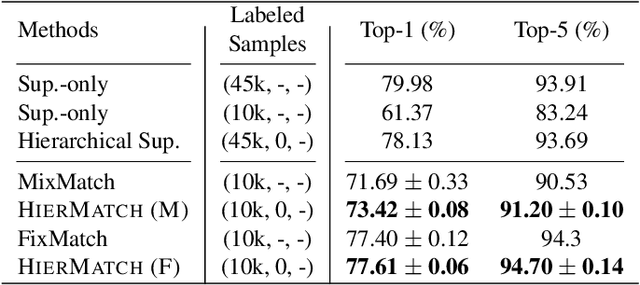
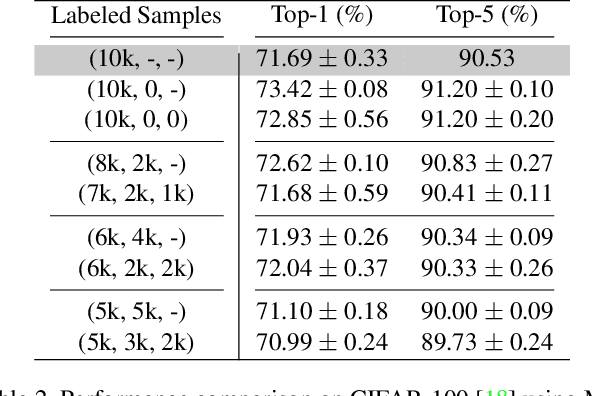
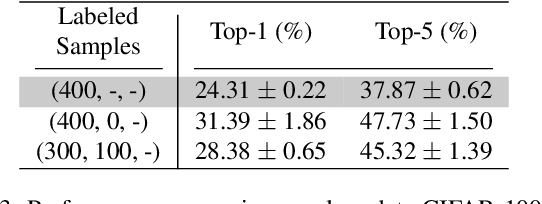
Semi-supervised learning approaches have emerged as an active area of research to combat the challenge of obtaining large amounts of annotated data. Towards the goal of improving the performance of semi-supervised learning methods, we propose a novel framework, HIERMATCH, a semi-supervised approach that leverages hierarchical information to reduce labeling costs and performs as well as a vanilla semi-supervised learning method. Hierarchical information is often available as prior knowledge in the form of coarse labels (e.g., woodpeckers) for images with fine-grained labels (e.g., downy woodpeckers or golden-fronted woodpeckers). However, the use of supervision using coarse category labels to improve semi-supervised techniques has not been explored. In the absence of fine-grained labels, HIERMATCH exploits the label hierarchy and uses coarse class labels as a weak supervisory signal. Additionally, HIERMATCH is a generic-approach to improve any semisupervised learning framework, we demonstrate this using our results on recent state-of-the-art techniques MixMatch and FixMatch. We evaluate the efficacy of HIERMATCH on two benchmark datasets, namely CIFAR-100 and NABirds. HIERMATCH can reduce the usage of fine-grained labels by 50% on CIFAR-100 with only a marginal drop of 0.59% in top-1 accuracy as compared to MixMatch.
Speaker-Conditioned Hierarchical Modeling for Automated Speech Scoring
Aug 30, 2021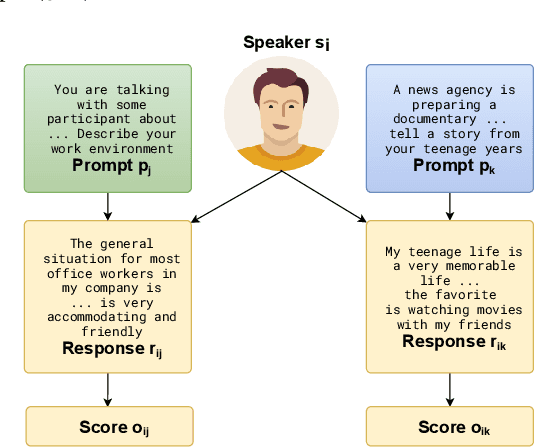
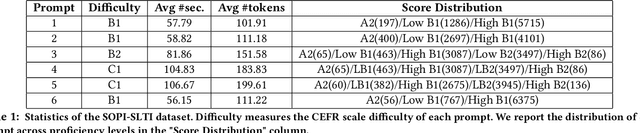
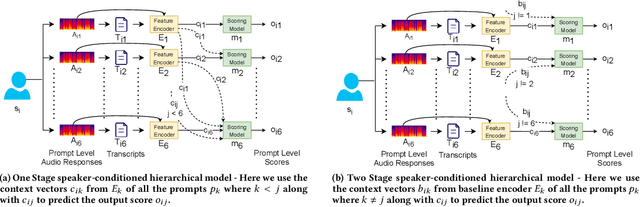

Automatic Speech Scoring (ASS) is the computer-assisted evaluation of a candidate's speaking proficiency in a language. ASS systems face many challenges like open grammar, variable pronunciations, and unstructured or semi-structured content. Recent deep learning approaches have shown some promise in this domain. However, most of these approaches focus on extracting features from a single audio, making them suffer from the lack of speaker-specific context required to model such a complex task. We propose a novel deep learning technique for non-native ASS, called speaker-conditioned hierarchical modeling. In our technique, we take advantage of the fact that oral proficiency tests rate multiple responses for a candidate. We extract context vectors from these responses and feed them as additional speaker-specific context to our network to score a particular response. We compare our technique with strong baselines and find that such modeling improves the model's average performance by 6.92% (maximum = 12.86%, minimum = 4.51%). We further show both quantitative and qualitative insights into the importance of this additional context in solving the problem of ASS.