 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKV-CoRE: Benchmarking Data-Dependent Low-Rank Compressibility of KV-Caches in LLMs
Feb 05, 2026Large language models rely on kv-caches to avoid redundant computation during autoregressive decoding, but as context length grows, reading and writing the cache can quickly saturate GPU memory bandwidth. Recent work has explored KV-cache compression, yet most approaches neglect the data-dependent nature of kv-caches and their variation across layers. We introduce KV-CoRE KV-cache Compressibility by Rank Evaluation), an SVD-based method for quantifying the data-dependent low-rank compressibility of kv-caches. KV-CoRE computes the optimal low-rank approximation under the Frobenius norm and, being gradient-free and incremental, enables efficient dataset-level, layer-wise evaluation. Using this method, we analyze multiple models and datasets spanning five English domains and sixteen languages, uncovering systematic patterns that link compressibility to model architecture, training data, and language coverage. As part of this analysis, we employ the Normalized Effective Rank as a metric of compressibility and show that it correlates strongly with performance degradation under compression. Our study establishes a principled evaluation framework and the first large-scale benchmark of kv-cache compressibility in LLMs, offering insights for dynamic, data-aware compression and data-centric model development.
KGOT: Unified Knowledge Graph and Optimal Transport Pseudo-Labeling for Molecule-Protein Interaction Prediction
Dec 10, 2025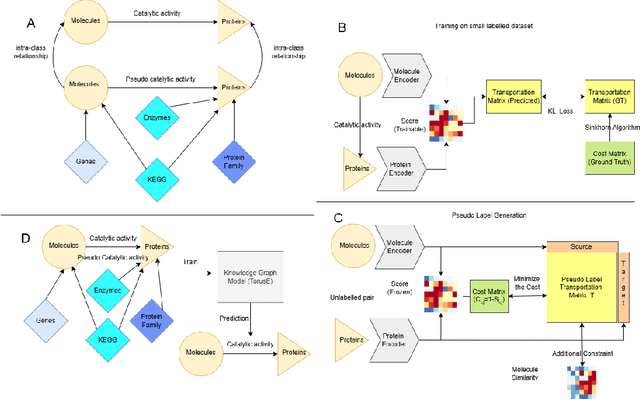
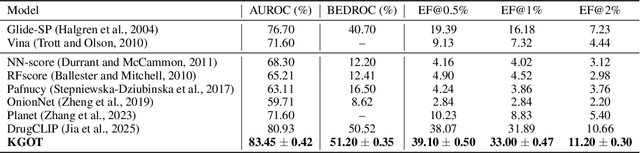
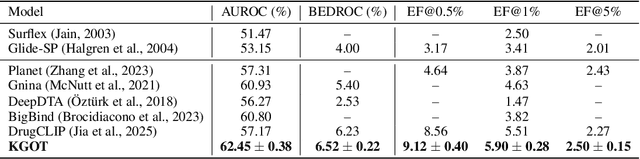
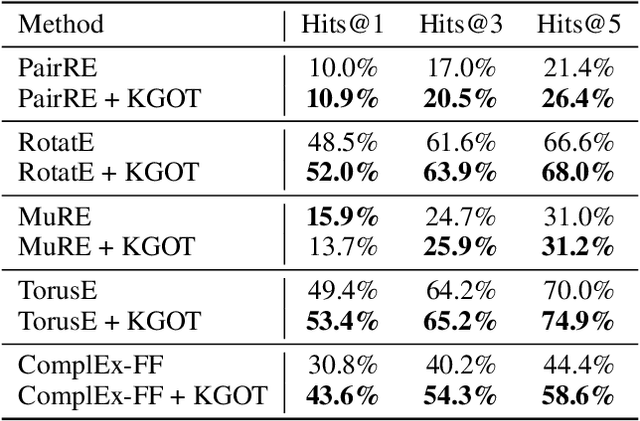
Predicting molecule-protein interactions (MPIs) is a fundamental task in computational biology, with crucial applications in drug discovery and molecular function annotation. However, existing MPI models face two major challenges. First, the scarcity of labeled molecule-protein pairs significantly limits model performance, as available datasets capture only a small fraction of biological relevant interactions. Second, most methods rely solely on molecular and protein features, ignoring broader biological context such as genes, metabolic pathways, and functional annotations that could provide essential complementary information. To address these limitations, our framework first aggregates diverse biological datasets, including molecular, protein, genes and pathway-level interactions, and then develop an optimal transport-based approach to generate high-quality pseudo-labels for unlabeled molecule-protein pairs, leveraging the underlying distribution of known interactions to guide label assignment. By treating pseudo-labeling as a mechanism for bridging disparate biological modalities, our approach enables the effective use of heterogeneous data to enhance MPI prediction. We evaluate our framework on multiple MPI datasets including virtual screening tasks and protein retrieval tasks, demonstrating substantial improvements over state-of-the-art methods in prediction accuracies and zero shot ability across unseen interactions. Beyond MPI prediction, our approach provides a new paradigm for leveraging diverse biological data sources to tackle problems traditionally constrained by single- or bi-modal learning, paving the way for future advances in computational biology and drug discovery.
VisR-Bench: An Empirical Study on Visual Retrieval-Augmented Generation for Multilingual Long Document Understanding
Aug 10, 2025Most organizational data in this world are stored as documents, and visual retrieval plays a crucial role in unlocking the collective intelligence from all these documents. However, existing benchmarks focus on English-only document retrieval or only consider multilingual question-answering on a single-page image. To bridge this gap, we introduce VisR-Bench, a multilingual benchmark designed for question-driven multimodal retrieval in long documents. Our benchmark comprises over 35K high-quality QA pairs across 1.2K documents, enabling fine-grained evaluation of multimodal retrieval. VisR-Bench spans sixteen languages with three question types (figures, text, and tables), offering diverse linguistic and question coverage. Unlike prior datasets, we include queries without explicit answers, preventing models from relying on superficial keyword matching. We evaluate various retrieval models, including text-based methods, multimodal encoders, and MLLMs, providing insights into their strengths and limitations. Our results show that while MLLMs significantly outperform text-based and multimodal encoder models, they still struggle with structured tables and low-resource languages, highlighting key challenges in multilingual visual retrieval.
A High-Quality Text-Rich Image Instruction Tuning Dataset via Hybrid Instruction Generation
Dec 20, 2024Large multimodal models still struggle with text-rich images because of inadequate training data. Self-Instruct provides an annotation-free way for generating instruction data, but its quality is poor, as multimodal alignment remains a hurdle even for the largest models. In this work, we propose LLaVAR-2, to enhance multimodal alignment for text-rich images through hybrid instruction generation between human annotators and large language models. Specifically, it involves detailed image captions from human annotators, followed by the use of these annotations in tailored text prompts for GPT-4o to curate a dataset. It also implements several mechanisms to filter out low-quality data, and the resulting dataset comprises 424k high-quality pairs of instructions. Empirical results show that models fine-tuned on this dataset exhibit impressive enhancements over those trained with self-instruct data.
Enhancing Diffusion Posterior Sampling for Inverse Problems by Integrating Crafted Measurements
Nov 15, 2024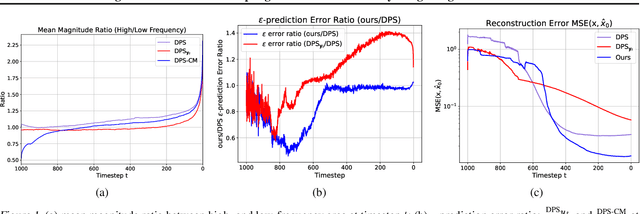



Diffusion models have emerged as a powerful foundation model for visual generation. With an appropriate sampling process, it can effectively serve as a generative prior to solve general inverse problems. Current posterior sampling based methods take the measurement (i.e., degraded image sample) into the posterior sampling to infer the distribution of the target data (i.e., clean image sample). However, in this manner, we show that high-frequency information can be prematurely introduced during the early stages, which could induce larger posterior estimate errors during the restoration sampling. To address this issue, we first reveal that forming the log posterior gradient with the noisy measurement ( i.e., samples from a diffusion forward process) instead of the clean one can benefit the reverse process. Consequently, we propose a novel diffusion posterior sampling method DPS-CM, which incorporates a Crafted Measurement (i.e., samples generated by a reverse denoising process, compared to random sampling with noise in standard methods) to form the posterior estimate. This integration aims to mitigate the misalignment with the diffusion prior caused by cumulative posterior estimate errors. Experimental results demonstrate that our approach significantly improves the overall capacity to solve general and noisy inverse problems, such as Gaussian deblurring, super-resolution, inpainting, nonlinear deblurring, and tasks with Poisson noise, relative to existing approaches.
LoRA-Contextualizing Adaptation of Large Multimodal Models for Long Document Understanding
Nov 02, 2024Large multimodal models (LMMs) have recently shown great progress in text-rich image understanding, yet they still struggle with complex, multi-page, visually-rich documents. Traditional methods using document parsers for retrieval-augmented generation suffer from performance and efficiency limitations, while directly presenting all pages to LMMs leads to inefficiencies, especially with lengthy documents. In this work, we present a novel framework named LoRA-Contextualizing Adaptation of Large multimodal models (LoCAL), which broadens the capabilities of any LMM to support long-document understanding. We demonstrate that LMMs can effectively serve as multimodal retrievers, fetching relevant pages to answer user questions based on these pages. LoCAL is implemented with two specific LMM adapters: one for evidence page retrieval and another for question answering. Empirical results show state-of-the-art performance on public benchmarks, demonstrating the effectiveness of LoCAL.
TextLap: Customizing Language Models for Text-to-Layout Planning
Oct 09, 2024



Automatic generation of graphical layouts is crucial for many real-world applications, including designing posters, flyers, advertisements, and graphical user interfaces. Given the incredible ability of Large language models (LLMs) in both natural language understanding and generation, we believe that we could customize an LLM to help people create compelling graphical layouts starting with only text instructions from the user. We call our method TextLap (text-based layout planning). It uses a curated instruction-based layout planning dataset (InsLap) to customize LLMs as a graphic designer. We demonstrate the effectiveness of TextLap and show that it outperforms strong baselines, including GPT-4 based methods, for image generation and graphical design benchmarks.
MMR: Evaluating Reading Ability of Large Multimodal Models
Aug 26, 2024



Large multimodal models (LMMs) have demonstrated impressive capabilities in understanding various types of image, including text-rich images. Most existing text-rich image benchmarks are simple extraction-based question answering, and many LMMs now easily achieve high scores. This means that current benchmarks fail to accurately reflect performance of different models, and a natural idea is to build a new benchmark to evaluate their complex reasoning and spatial understanding abilities. In this work, we propose the Multi-Modal Reading (MMR) benchmark in 11 diverse tasks to evaluate LMMs for text-rich image understanding. MMR is the first text-rich image benchmark built on human annotations with the help of language models. By evaluating several state-of-the-art LMMs, including GPT-4o, it reveals the limited capabilities of existing LMMs underscoring the value of our benchmark.
LLaVA-Read: Enhancing Reading Ability of Multimodal Language Models
Jul 27, 2024



Large multimodal language models have demonstrated impressive capabilities in understanding and manipulating images. However, many of these models struggle with comprehending intensive textual contents embedded within the images, primarily due to the limited text recognition and layout understanding ability. To understand the sources of these limitations, we perform an exploratory analysis showing the drawbacks of classical visual encoders on visual text understanding. Hence, we present LLaVA-Read, a multimodal large language model that utilizes dual visual encoders along with a visual text encoder. Our model surpasses existing state-of-the-art models in various text-rich image understanding tasks, showcasing enhanced comprehension of textual content within images. Together, our research suggests visual text understanding remains an open challenge and an efficient visual text encoder is crucial for future successful multimodal systems.
Diffusion Models for Multi-Task Generative Modeling
Jul 24, 2024
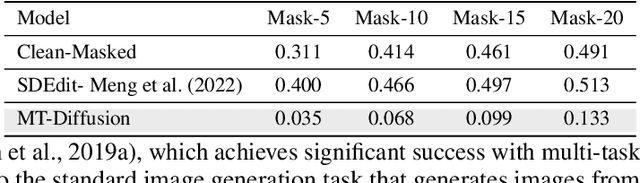
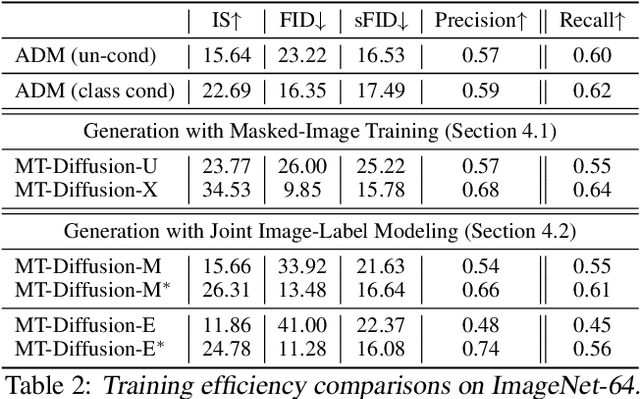
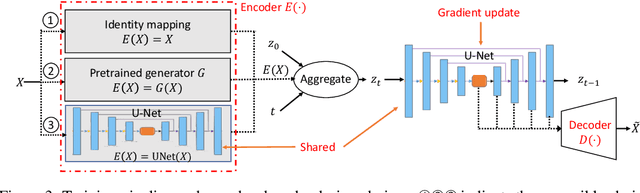
Diffusion-based generative modeling has been achieving state-of-the-art results on various generation tasks. Most diffusion models, however, are limited to a single-generation modeling. Can we generalize diffusion models with the ability of multi-modal generative training for more generalizable modeling? In this paper, we propose a principled way to define a diffusion model by constructing a unified multi-modal diffusion model in a common diffusion space. We define the forward diffusion process to be driven by an information aggregation from multiple types of task-data, e.g., images for a generation task and labels for a classification task. In the reverse process, we enforce information sharing by parameterizing a shared backbone denoising network with additional modality-specific decoder heads. Such a structure can simultaneously learn to generate different types of multi-modal data with a multi-task loss, which is derived from a new multi-modal variational lower bound that generalizes the standard diffusion model. We propose several multimodal generation settings to verify our framework, including image transition, masked-image training, joint image-label and joint image-representation generative modeling. Extensive experimental results on ImageNet indicate the effectiveness of our framework for various multi-modal generative modeling, which we believe is an important research direction worthy of more future explorations.