 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models for Multi-Task Generative Modeling
Jul 24, 2024
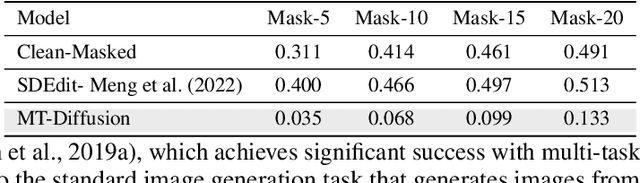
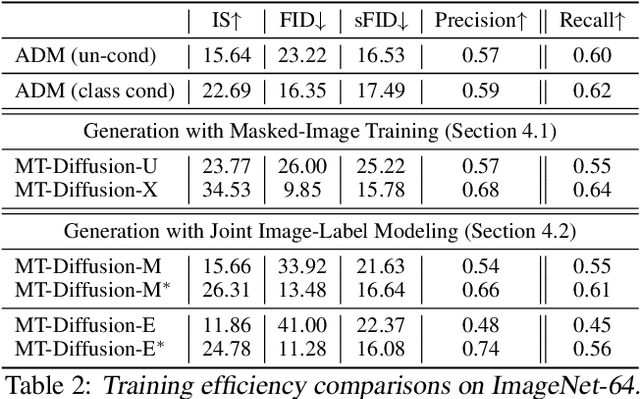
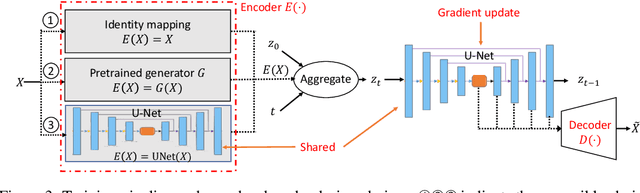
Diffusion-based generative modeling has been achieving state-of-the-art results on various generation tasks. Most diffusion models, however, are limited to a single-generation modeling. Can we generalize diffusion models with the ability of multi-modal generative training for more generalizable modeling? In this paper, we propose a principled way to define a diffusion model by constructing a unified multi-modal diffusion model in a common diffusion space. We define the forward diffusion process to be driven by an information aggregation from multiple types of task-data, e.g., images for a generation task and labels for a classification task. In the reverse process, we enforce information sharing by parameterizing a shared backbone denoising network with additional modality-specific decoder heads. Such a structure can simultaneously learn to generate different types of multi-modal data with a multi-task loss, which is derived from a new multi-modal variational lower bound that generalizes the standard diffusion model. We propose several multimodal generation settings to verify our framework, including image transition, masked-image training, joint image-label and joint image-representation generative modeling. Extensive experimental results on ImageNet indicate the effectiveness of our framework for various multi-modal generative modeling, which we believe is an important research direction worthy of more future explorations.
VidLA: Video-Language Alignment at Scale
Mar 21, 2024In this paper, we propose VidLA, an approach for video-language alignment at scale. There are two major limitations of previous video-language alignment approaches. First, they do not capture both short-range and long-range temporal dependencies and typically employ complex hierarchical deep network architectures that are hard to integrate with existing pretrained image-text foundation models. To effectively address this limitation, we instead keep the network architecture simple and use a set of data tokens that operate at different temporal resolutions in a hierarchical manner, accounting for the temporally hierarchical nature of videos. By employing a simple two-tower architecture, we are able to initialize our video-language model with pretrained image-text foundation models, thereby boosting the final performance. Second, existing video-language alignment works struggle due to the lack of semantically aligned large-scale training data. To overcome it, we leverage recent LLMs to curate the largest video-language dataset to date with better visual grounding. Furthermore, unlike existing video-text datasets which only contain short clips, our dataset is enriched with video clips of varying durations to aid our temporally hierarchical data tokens in extracting better representations at varying temporal scales. Overall, empirical results show that our proposed approach surpasses state-of-the-art methods on multiple retrieval benchmarks, especially on longer videos, and performs competitively on classification benchmarks.