 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDiffusion Models for Multi-Task Generative Modeling
Jul 24, 2024
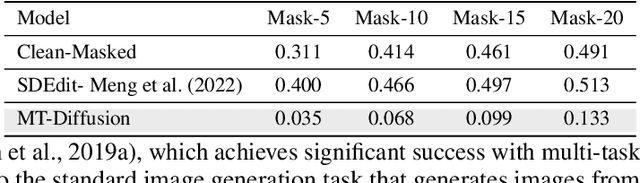
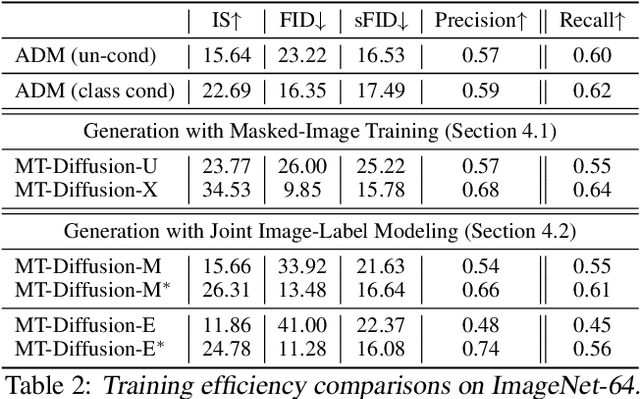
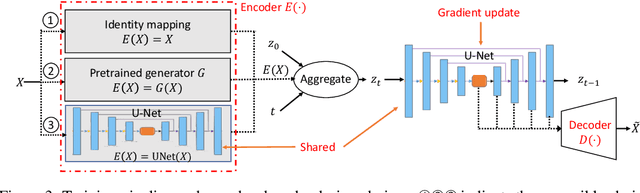
Diffusion-based generative modeling has been achieving state-of-the-art results on various generation tasks. Most diffusion models, however, are limited to a single-generation modeling. Can we generalize diffusion models with the ability of multi-modal generative training for more generalizable modeling? In this paper, we propose a principled way to define a diffusion model by constructing a unified multi-modal diffusion model in a common diffusion space. We define the forward diffusion process to be driven by an information aggregation from multiple types of task-data, e.g., images for a generation task and labels for a classification task. In the reverse process, we enforce information sharing by parameterizing a shared backbone denoising network with additional modality-specific decoder heads. Such a structure can simultaneously learn to generate different types of multi-modal data with a multi-task loss, which is derived from a new multi-modal variational lower bound that generalizes the standard diffusion model. We propose several multimodal generation settings to verify our framework, including image transition, masked-image training, joint image-label and joint image-representation generative modeling. Extensive experimental results on ImageNet indicate the effectiveness of our framework for various multi-modal generative modeling, which we believe is an important research direction worthy of more future explorations.
Deep Transfer Learning for Multi-source Entity Linkage via Domain Adaptation
Oct 27, 2021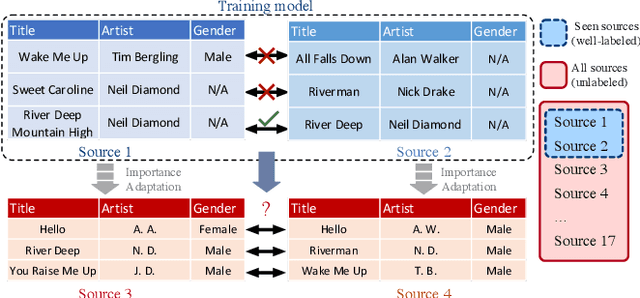

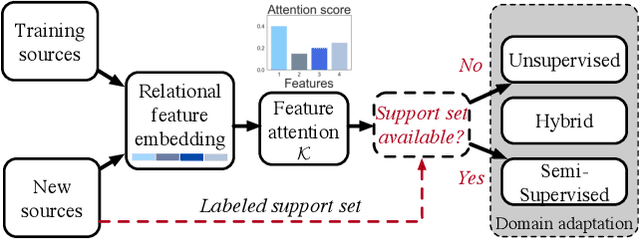
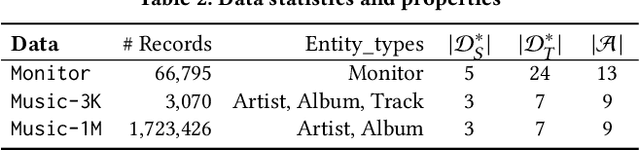
Multi-source entity linkage focuses on integrating knowledge from multiple sources by linking the records that represent the same real world entity. This is critical in high-impact applications such as data cleaning and user stitching. The state-of-the-art entity linkage pipelines mainly depend on supervised learning that requires abundant amounts of training data. However, collecting well-labeled training data becomes expensive when the data from many sources arrives incrementally over time. Moreover, the trained models can easily overfit to specific data sources, and thus fail to generalize to new sources due to significant differences in data and label distributions. To address these challenges, we present AdaMEL, a deep transfer learning framework that learns generic high-level knowledge to perform multi-source entity linkage. AdaMEL models the attribute importance that is used to match entities through an attribute-level self-attention mechanism, and leverages the massive unlabeled data from new data sources through domain adaptation to make it generic and data-source agnostic. In addition, AdaMEL is capable of incorporating an additional set of labeled data to more accurately integrate data sources with different attribute importance. Extensive experiments show that our framework achieves state-of-the-art results with 8.21% improvement on average over methods based on supervised learning. Besides, it is more stable in handling different sets of data sources in less runtime.
CoRI: Collective Relation Integration with Data Augmentation for Open Information Extraction
Jun 01, 2021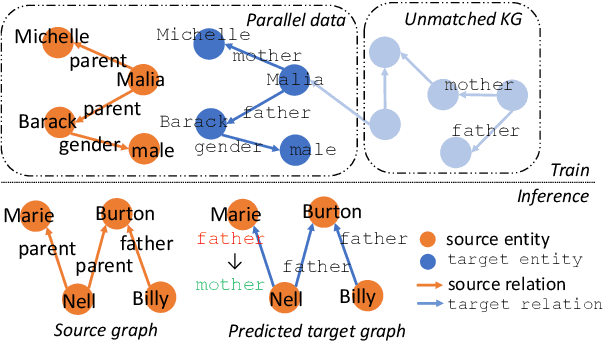
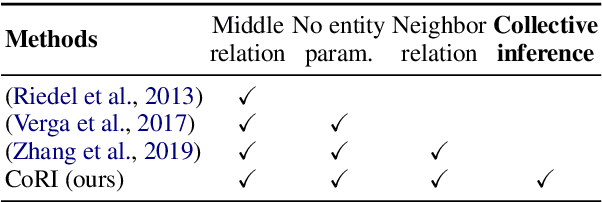
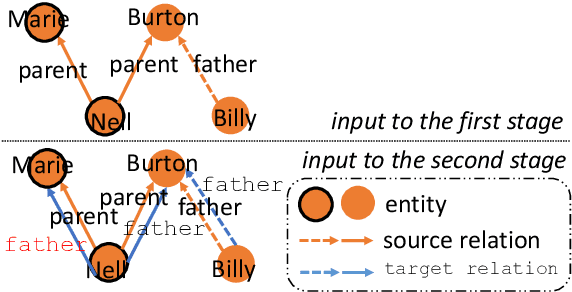
Integrating extracted knowledge from the Web to knowledge graphs (KGs) can facilitate tasks like question answering. We study relation integration that aims to align free-text relations in subject-relation-object extractions to relations in a target KG. To address the challenge that free-text relations are ambiguous, previous methods exploit neighbor entities and relations for additional context. However, the predictions are made independently, which can be mutually inconsistent. We propose a two-stage Collective Relation Integration (CoRI) model, where the first stage independently makes candidate predictions, and the second stage employs a collective model that accesses all candidate predictions to make globally coherent predictions. We further improve the collective model with augmented data from the portion of the target KG that is otherwise unused. Experiment results on two datasets show that CoRI can significantly outperform the baselines, improving AUC from .677 to .748 and from .716 to .780, respectively.
CorDEL: A Contrastive Deep Learning Approach for Entity Linkage
Sep 15, 2020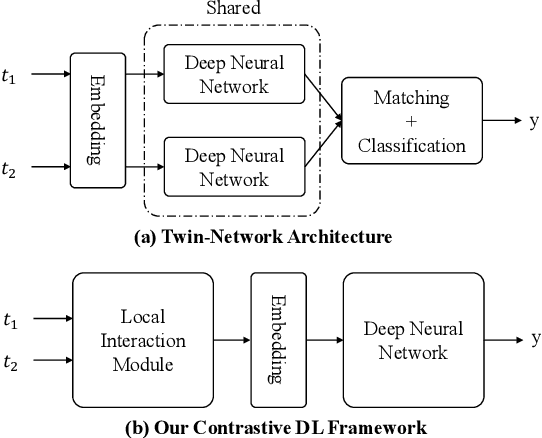
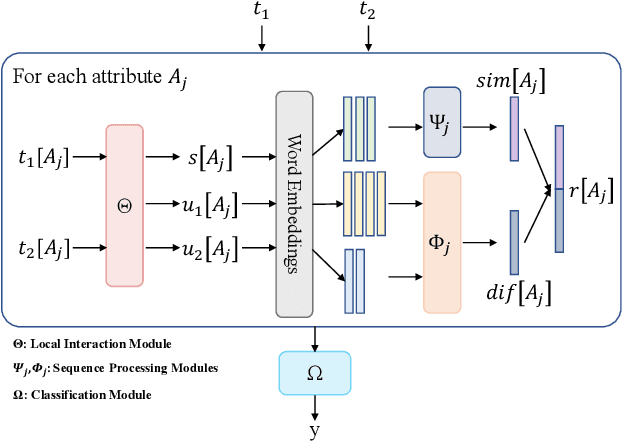
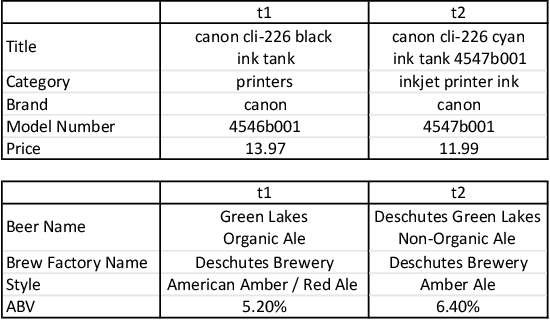
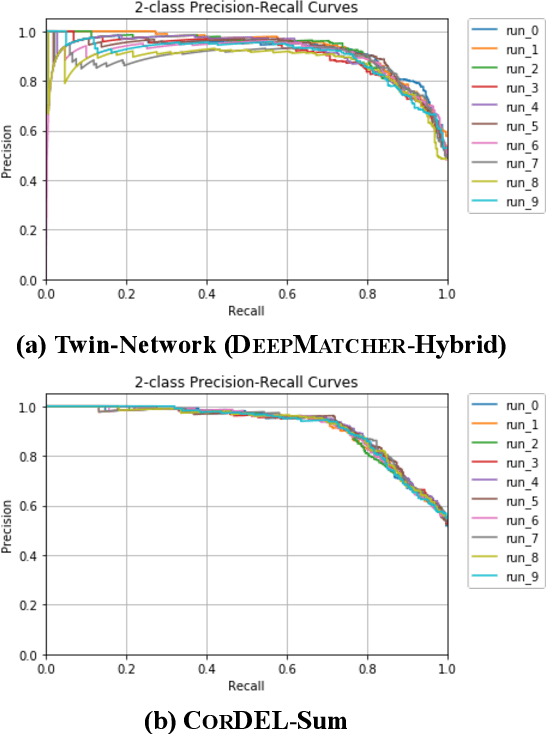
Entity linkage (EL) is a critical problem in data cleaning and integration. In the past several decades, EL has typically been done by rule-based systems or traditional machine learning models with hand-curated features, both of which heavily depend on manual human inputs. With the ever-increasing growth of new data, deep learning (DL) based approaches have been proposed to alleviate the high cost of EL associated with the traditional models. Existing exploration of DL models for EL strictly follows the well-known twin-network architecture. However, we argue that the twin-network architecture is sub-optimal to EL, leading to inherent drawbacks of existing models. In order to address the drawbacks, we propose a novel and generic contrastive DL framework for EL. The proposed framework is able to capture both syntactic and semantic matching signals and pays attention to subtle but critical differences. Based on the framework, we develop a contrastive DL approach for EL, called CorDEL, with three powerful variants. We evaluate CorDEL with extensive experiments conducted on both public benchmark datasets and a real-world dataset. CorDEL outperforms previous state-of-the-art models by 5.2% on public benchmark datasets. Moreover, CorDEL yields a 2.4% improvement over the current best DL model on the real-world dataset, while reducing the number of training parameters by 97.6%.
AutoBlock: A Hands-off Blocking Framework for Entity Matching
Dec 07, 2019
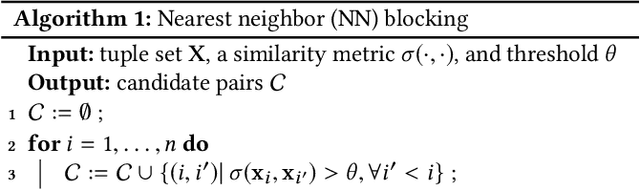
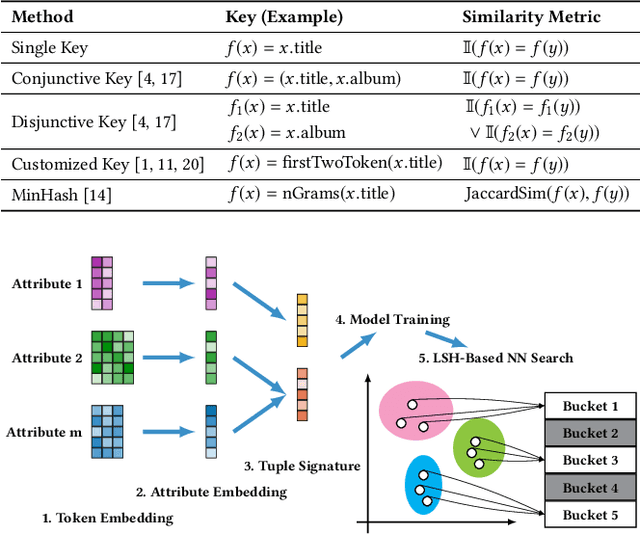

Entity matching seeks to identify data records over one or multiple data sources that refer to the same real-world entity. Virtually every entity matching task on large datasets requires blocking, a step that reduces the number of record pairs to be matched. However, most of the traditional blocking methods are learning-free and key-based, and their successes are largely built on laborious human effort in cleaning data and designing blocking keys. In this paper, we propose AutoBlock, a novel hands-off blocking framework for entity matching, based on similarity-preserving representation learning and nearest neighbor search. Our contributions include: (a) Automation: AutoBlock frees users from laborious data cleaning and blocking key tuning. (b) Scalability: AutoBlock has a sub-quadratic total time complexity and can be easily deployed for millions of records. (c) Effectiveness: AutoBlock outperforms a wide range of competitive baselines on multiple large-scale, real-world datasets, especially when datasets are dirty and/or unstructured.
LinkNBed: Multi-Graph Representation Learning with Entity Linkage
Jul 23, 2018



Knowledge graphs have emerged as an important model for studying complex multi-relational data. This has given rise to the construction of numerous large scale but incomplete knowledge graphs encoding information extracted from various resources. An effective and scalable approach to jointly learn over multiple graphs and eventually construct a unified graph is a crucial next step for the success of knowledge-based inference for many downstream applications. To this end, we propose LinkNBed, a deep relational learning framework that learns entity and relationship representations across multiple graphs. We identify entity linkage across graphs as a vital component to achieve our goal. We design a novel objective that leverage entity linkage and build an efficient multi-task training procedure. Experiments on link prediction and entity linkage demonstrate substantial improvements over the state-of-the-art relational learning approaches.