 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGRAPHTEXTACK: A Realistic Black-Box Node Injection Attack on LLM-Enhanced GNNs
Nov 16, 2025Text-attributed graphs (TAGs), which combine structural and textual node information, are ubiquitous across many domains. Recent work integrates Large Language Models (LLMs) with Graph Neural Networks (GNNs) to jointly model semantics and structure, resulting in more general and expressive models that achieve state-of-the-art performance on TAG benchmarks. However, this integration introduces dual vulnerabilities: GNNs are sensitive to structural perturbations, while LLM-derived features are vulnerable to prompt injection and adversarial phrasing. While existing adversarial attacks largely perturb structure or text independently, we find that uni-modal attacks cause only modest degradation in LLM-enhanced GNNs. Moreover, many existing attacks assume unrealistic capabilities, such as white-box access or direct modification of graph data. To address these gaps, we propose GRAPHTEXTACK, the first black-box, multi-modal{, poisoning} node injection attack for LLM-enhanced GNNs. GRAPHTEXTACK injects nodes with carefully crafted structure and semantics to degrade model performance, operating under a realistic threat model without relying on model internals or surrogate models. To navigate the combinatorial, non-differentiable search space of connectivity and feature assignments, GRAPHTEXTACK introduces a novel evolutionary optimization framework with a multi-objective fitness function that balances local prediction disruption and global graph influence. Extensive experiments on five datasets and two state-of-the-art LLM-enhanced GNN models show that GRAPHTEXTACK significantly outperforms 12 strong baselines.
Random Search Neural Networks for Efficient and Expressive Graph Learning
Oct 26, 2025Random walk neural networks (RWNNs) have emerged as a promising approach for graph representation learning, leveraging recent advances in sequence models to process random walks. However, under realistic sampling constraints, RWNNs often fail to capture global structure even in small graphs due to incomplete node and edge coverage, limiting their expressivity. To address this, we propose \textit{random search neural networks} (RSNNs), which operate on random searches, each of which guarantees full node coverage. Theoretically, we demonstrate that in sparse graphs, only $O(\log |V|)$ searches are needed to achieve full edge coverage, substantially reducing sampling complexity compared to the $O(|V|)$ walks required by RWNNs (assuming walk lengths scale with graph size). Furthermore, when paired with universal sequence models, RSNNs are universal approximators. We lastly show RSNNs are probabilistically invariant to graph isomorphisms, ensuring their expectation is an isomorphism-invariant graph function. Empirically, RSNNs consistently outperform RWNNs on molecular and protein benchmarks, achieving comparable or superior performance with up to 16$\times$ fewer sampled sequences. Our work bridges theoretical and practical advances in random walk based approaches, offering an efficient and expressive framework for learning on sparse graphs.
On the Role of Weight Decay in Collaborative Filtering: A Popularity Perspective
May 16, 2025Collaborative filtering (CF) enables large-scale recommendation systems by encoding information from historical user-item interactions into dense ID-embedding tables. However, as embedding tables grow, closed-form solutions become impractical, often necessitating the use of mini-batch gradient descent for training. Despite extensive work on designing loss functions to train CF models, we argue that one core component of these pipelines is heavily overlooked: weight decay. Attaining high-performing models typically requires careful tuning of weight decay, regardless of loss, yet its necessity is not well understood. In this work, we question why weight decay is crucial in CF pipelines and how it impacts training. Through theoretical and empirical analysis, we surprisingly uncover that weight decay's primary function is to encode popularity information into the magnitudes of the embedding vectors. Moreover, we find that tuning weight decay acts as a coarse, non-linear knob to influence preference towards popular or unpopular items. Based on these findings, we propose PRISM (Popularity-awaRe Initialization Strategy for embedding Magnitudes), a straightforward yet effective solution to simplify the training of high-performing CF models. PRISM pre-encodes the popularity information typically learned through weight decay, eliminating its necessity. Our experiments show that PRISM improves performance by up to 4.77% and reduces training times by 38.48%, compared to state-of-the-art training strategies. Additionally, we parameterize PRISM to modulate the initialization strength, offering a cost-effective and meaningful strategy to mitigate popularity bias.
Learning Laplacian Positional Encodings for Heterophilous Graphs
Apr 29, 2025In this work, we theoretically demonstrate that current graph positional encodings (PEs) are not beneficial and could potentially hurt performance in tasks involving heterophilous graphs, where nodes that are close tend to have different labels. This limitation is critical as many real-world networks exhibit heterophily, and even highly homophilous graphs can contain local regions of strong heterophily. To address this limitation, we propose Learnable Laplacian Positional Encodings (LLPE), a new PE that leverages the full spectrum of the graph Laplacian, enabling them to capture graph structure on both homophilous and heterophilous graphs. Theoretically, we prove LLPE's ability to approximate a general class of graph distances and demonstrate its generalization properties. Empirically, our evaluation on 12 benchmarks demonstrates that LLPE improves accuracy across a variety of GNNs, including graph transformers, by up to 35% and 14% on synthetic and real-world graphs, respectively. Going forward, our work represents a significant step towards developing PEs that effectively capture complex structures in heterophilous graphs.
Understanding GNNs and Homophily in Dynamic Node Classification
Apr 29, 2025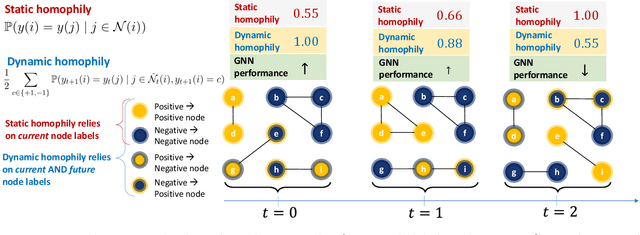

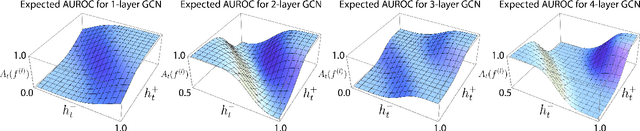

Homophily, as a measure, has been critical to increasing our understanding of graph neural networks (GNNs). However, to date this measure has only been analyzed in the context of static graphs. In our work, we explore homophily in dynamic settings. Focusing on graph convolutional networks (GCNs), we demonstrate theoretically that in dynamic settings, current GCN discriminative performance is characterized by the probability that a node's future label is the same as its neighbors' current labels. Based on this insight, we propose dynamic homophily, a new measure of homophily that applies in the dynamic setting. This new measure correlates with GNN discriminative performance and sheds light on how to potentially design more powerful GNNs for dynamic graphs. Leveraging a variety of dynamic node classification datasets, we demonstrate that popular GNNs are not robust to low dynamic homophily. Going forward, our work represents an important step towards understanding homophily and GNN performance in dynamic node classification.
Beyond Unimodal Boundaries: Generative Recommendation with Multimodal Semantics
Mar 30, 2025Generative recommendation (GR) has become a powerful paradigm in recommendation systems that implicitly links modality and semantics to item representation, in contrast to previous methods that relied on non-semantic item identifiers in autoregressive models. However, previous research has predominantly treated modalities in isolation, typically assuming item content is unimodal (usually text). We argue that this is a significant limitation given the rich, multimodal nature of real-world data and the potential sensitivity of GR models to modality choices and usage. Our work aims to explore the critical problem of Multimodal Generative Recommendation (MGR), highlighting the importance of modality choices in GR nframeworks. We reveal that GR models are particularly sensitive to different modalities and examine the challenges in achieving effective GR when multiple modalities are available. By evaluating design strategies for effectively leveraging multiple modalities, we identify key challenges and introduce MGR-LF++, an enhanced late fusion framework that employs contrastive modality alignment and special tokens to denote different modalities, achieving a performance improvement of over 20% compared to single-modality alternatives.
Unleashing the Power of LLMs as Multi-Modal Encoders for Text and Graph-Structured Data
Oct 15, 2024



Graph-structured information offers rich contextual information that can enhance language models by providing structured relationships and hierarchies, leading to more expressive embeddings for various applications such as retrieval, question answering, and classification. However, existing methods for integrating graph and text embeddings, often based on Multi-layer Perceptrons (MLPs) or shallow transformers, are limited in their ability to fully exploit the heterogeneous nature of these modalities. To overcome this, we propose Janus, a simple yet effective framework that leverages Large Language Models (LLMs) to jointly encode text and graph data. Specifically, Janus employs an MLP adapter to project graph embeddings into the same space as text embeddings, allowing the LLM to process both modalities jointly. Unlike prior work, we also introduce contrastive learning to align the graph and text spaces more effectively, thereby improving the quality of learned joint embeddings. Empirical results across six datasets spanning three tasks, knowledge graph-contextualized question answering, graph-text pair classification, and retrieval, demonstrate that Janus consistently outperforms existing baselines, achieving significant improvements across multiple datasets, with gains of up to 11.4% in QA tasks. These results highlight Janus's effectiveness in integrating graph and text data. Ablation studies further validate the effectiveness of our method.
Unveiling the Impact of Local Homophily on GNN Fairness: In-Depth Analysis and New Benchmarks
Oct 05, 2024
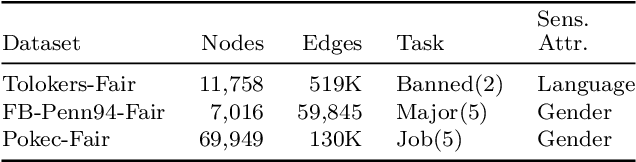
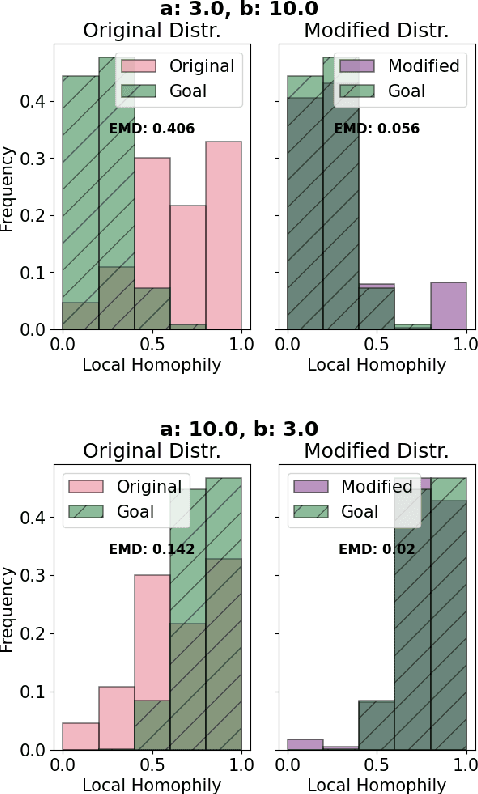
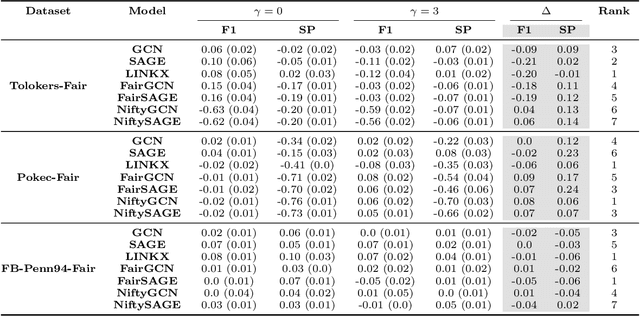
Graph Neural Networks (GNNs) often struggle to generalize when graphs exhibit both homophily (same-class connections) and heterophily (different-class connections). Specifically, GNNs tend to underperform for nodes with local homophily levels that differ significantly from the global homophily level. This issue poses a risk in user-centric applications where underrepresented homophily levels are present. Concurrently, fairness within GNNs has received substantial attention due to the potential amplification of biases via message passing. However, the connection between local homophily and fairness in GNNs remains underexplored. In this work, we move beyond global homophily and explore how local homophily levels can lead to unfair predictions. We begin by formalizing the challenge of fair predictions for underrepresented homophily levels as an out-of-distribution (OOD) problem. We then conduct a theoretical analysis that demonstrates how local homophily levels can alter predictions for differing sensitive attributes. We additionally introduce three new GNN fairness benchmarks, as well as a novel semi-synthetic graph generator, to empirically study the OOD problem. Across extensive analysis we find that two factors can promote unfairness: (a) OOD distance, and (b) heterophilous nodes situated in homophilous graphs. In cases where these two conditions are met, fairness drops by up to 24% on real world datasets, and 30% in semi-synthetic datasets. Together, our theoretical insights, empirical analysis, and algorithmic contributions unveil a previously overlooked source of unfairness rooted in the graph's homophily information.
On the Impact of Feature Heterophily on Link Prediction with Graph Neural Networks
Sep 26, 2024
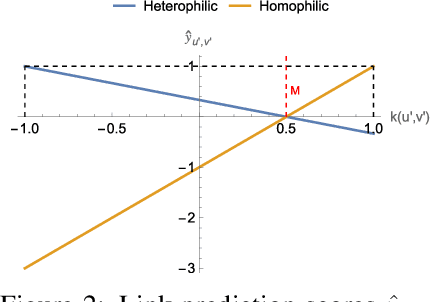
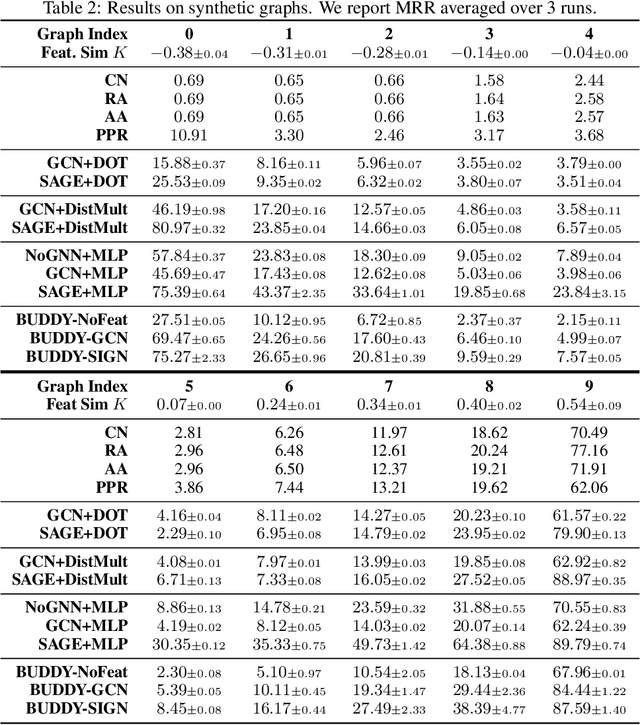
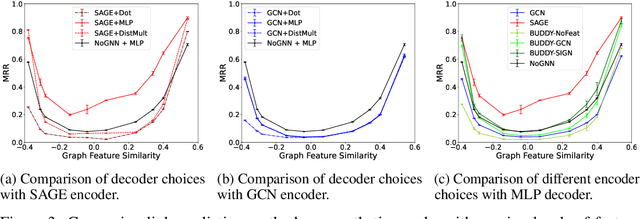
Heterophily, or the tendency of connected nodes in networks to have different class labels or dissimilar features, has been identified as challenging for many Graph Neural Network (GNN) models. While the challenges of applying GNNs for node classification when class labels display strong heterophily are well understood, it is unclear how heterophily affects GNN performance in other important graph learning tasks where class labels are not available. In this work, we focus on the link prediction task and systematically analyze the impact of heterophily in node features on GNN performance. Theoretically, we first introduce formal definitions of homophilic and heterophilic link prediction tasks, and present a theoretical framework that highlights the different optimizations needed for the respective tasks. We then analyze how different link prediction encoders and decoders adapt to varying levels of feature homophily and introduce designs for improved performance. Our empirical analysis on a variety of synthetic and real-world datasets confirms our theoretical insights and highlights the importance of adopting learnable decoders and GNN encoders with ego- and neighbor-embedding separation in message passing for link prediction tasks beyond homophily.
Multimodal Graph Benchmark
Jun 24, 2024



Associating unstructured data with structured information is crucial for real-world tasks that require relevance search. However, existing graph learning benchmarks often overlook the rich semantic information associate with each node. To bridge such gap, we introduce the Multimodal Graph Benchmark (MM-GRAPH), the first comprehensive multi-modal graph benchmark that incorporates both textual and visual information. MM-GRAPH surpasses previous efforts, which have primarily focused on text-attributed graphs with various connectivity patterns. MM-GRAPH consists of five graph learning datasets of various scales that are appropriate for different learning tasks. Their multimodal node features, enabling a more comprehensive evaluation of graph learning algorithms in real-world scenarios. To facilitate research on multimodal graph learning, we further provide an extensive study on the performance of various graph neural networks in the presence of features from various modalities. MM-GRAPH aims to foster research on multimodal graph learning and drive the development of more advanced and robust graph learning algorithms. By providing a diverse set of datasets and benchmarks, MM-GRAPH enables researchers to evaluate and compare their models in realistic settings, ultimately leading to improved performance on real-world applications that rely on multimodal graph data.