 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHardTests: Synthesizing High-Quality Test Cases for LLM Coding
May 30, 2025Verifiers play a crucial role in large language model (LLM) reasoning, needed by post-training techniques such as reinforcement learning. However, reliable verifiers are hard to get for difficult coding problems, because a well-disguised wrong solution may only be detected by carefully human-written edge cases that are difficult to synthesize. To address this issue, we propose HARDTESTGEN, a pipeline for high-quality test synthesis using LLMs. With this pipeline, we curate a comprehensive competitive programming dataset HARDTESTS with 47k problems and synthetic high-quality tests. Compared with existing tests, HARDTESTGEN tests demonstrate precision that is 11.3 percentage points higher and recall that is 17.5 percentage points higher when evaluating LLM-generated code. For harder problems, the improvement in precision can be as large as 40 points. HARDTESTS also proves to be more effective for model training, measured by downstream code generation performance. We will open-source our dataset and synthesis pipeline at https://leililab.github.io/HardTests/.
Multimodal Graph Benchmark
Jun 24, 2024



Associating unstructured data with structured information is crucial for real-world tasks that require relevance search. However, existing graph learning benchmarks often overlook the rich semantic information associate with each node. To bridge such gap, we introduce the Multimodal Graph Benchmark (MM-GRAPH), the first comprehensive multi-modal graph benchmark that incorporates both textual and visual information. MM-GRAPH surpasses previous efforts, which have primarily focused on text-attributed graphs with various connectivity patterns. MM-GRAPH consists of five graph learning datasets of various scales that are appropriate for different learning tasks. Their multimodal node features, enabling a more comprehensive evaluation of graph learning algorithms in real-world scenarios. To facilitate research on multimodal graph learning, we further provide an extensive study on the performance of various graph neural networks in the presence of features from various modalities. MM-GRAPH aims to foster research on multimodal graph learning and drive the development of more advanced and robust graph learning algorithms. By providing a diverse set of datasets and benchmarks, MM-GRAPH enables researchers to evaluate and compare their models in realistic settings, ultimately leading to improved performance on real-world applications that rely on multimodal graph data.
LinkGPT: Teaching Large Language Models To Predict Missing Links
Jun 07, 2024



Large Language Models (LLMs) have shown promising results on various language and vision tasks. Recently, there has been growing interest in applying LLMs to graph-based tasks, particularly on Text-Attributed Graphs (TAGs). However, most studies have focused on node classification, while the use of LLMs for link prediction (LP) remains understudied. In this work, we propose a new task on LLMs, where the objective is to leverage LLMs to predict missing links between nodes in a graph. This task evaluates an LLM's ability to reason over structured data and infer new facts based on learned patterns. This new task poses two key challenges: (1) How to effectively integrate pairwise structural information into the LLMs, which is known to be crucial for LP performance, and (2) how to solve the computational bottleneck when teaching LLMs to perform LP. To address these challenges, we propose LinkGPT, the first end-to-end trained LLM for LP tasks. To effectively enhance the LLM's ability to understand the underlying structure, we design a two-stage instruction tuning approach where the first stage fine-tunes the pairwise encoder, projector, and node projector, and the second stage further fine-tunes the LLMs to predict links. To address the efficiency challenges at inference time, we introduce a retrieval-reranking scheme. Experiments show that LinkGPT can achieve state-of-the-art performance on real-world graphs as well as superior generalization in zero-shot and few-shot learning, surpassing existing benchmarks. At inference time, it can achieve $10\times$ speedup while maintaining high LP accuracy.
GeoGalactica: A Scientific Large Language Model in Geoscience
Dec 31, 2023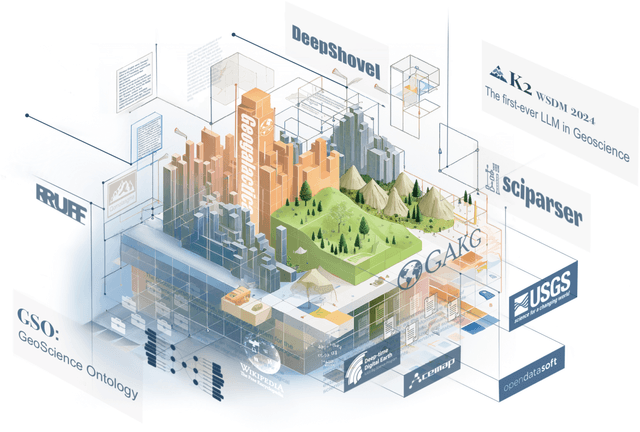

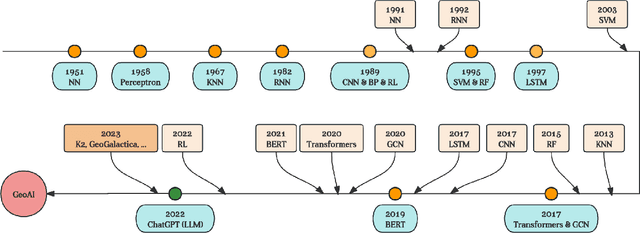
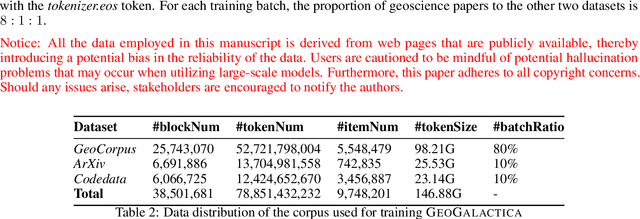
Large language models (LLMs) have achieved huge success for their general knowledge and ability to solve a wide spectrum of tasks in natural language processing (NLP). Due to their impressive abilities, LLMs have shed light on potential inter-discipline applications to foster scientific discoveries of a specific domain by using artificial intelligence (AI for science, AI4S). In the meantime, utilizing NLP techniques in geoscience research and practice is wide and convoluted, contributing from knowledge extraction and document classification to question answering and knowledge discovery. In this work, we take the initial step to leverage LLM for science, through a rather straightforward approach. We try to specialize an LLM into geoscience, by further pre-training the model with a vast amount of texts in geoscience, as well as supervised fine-tuning (SFT) the resulting model with our custom collected instruction tuning dataset. These efforts result in a model GeoGalactica consisting of 30 billion parameters. To our best knowledge, it is the largest language model for the geoscience domain. More specifically, GeoGalactica is from further pre-training of Galactica. We train GeoGalactica over a geoscience-related text corpus containing 65 billion tokens curated from extensive data sources in the big science project Deep-time Digital Earth (DDE), preserving as the largest geoscience-specific text corpus. Then we fine-tune the model with 1 million pairs of instruction-tuning data consisting of questions that demand professional geoscience knowledge to answer. In this technical report, we will illustrate in detail all aspects of GeoGalactica, including data collection, data cleaning, base model selection, pre-training, SFT, and evaluation. We open-source our data curation tools and the checkpoints of GeoGalactica during the first 3/4 of pre-training.
Learning A Foundation Language Model for Geoscience Knowledge Understanding and Utilization
Jun 08, 2023



Large language models (LLMs)have achieved great success in general domains of natural language processing. In this paper, we bring LLMs to the realm of geoscience, with the objective of advancing research and applications in this field. To this end, we present the first-ever LLM in geoscience, K2, alongside a suite of resources developed to further promote LLM research within geoscience. For instance, we have curated the first geoscience instruction tuning dataset, GeoSignal, which aims to align LLM responses to geoscience-related user queries. Additionally, we have established the first geoscience benchmark, GeoBenchmark, to evaluate LLMs in the context of geoscience. In this work, we experiment with a complete recipe to adapt a pretrained general-domain LLM to the geoscience domain. Specifically, we further train the LLaMA-7B model on over 1 million pieces of geoscience literature and utilize GeoSignal's supervised data to fine-tune the model. Moreover, we share a protocol that can efficiently gather domain-specific data and construct domain-supervised data, even in situations where manpower is scarce. Experiments conducted on the GeoBenchmark demonstrate the the effectiveness of our approach and datasets.