 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge<SOG_k>: One LLM Token for Explicit Graph Structural Understanding
Feb 02, 2026Large language models show great potential in unstructured data understanding, but still face significant challenges with graphs due to their structural hallucination. Existing approaches mainly either verbalize graphs into natural language, which leads to excessive token consumption and scattered attention, or transform graphs into trainable continuous embeddings (i.e., soft prompt), but exhibit severe misalignment with original text tokens. To solve this problem, we propose to incorporate one special token <SOG_k> to fully represent the Structure Of Graph within a unified token space, facilitating explicit topology input and structural information sharing. Specifically, we propose a topology-aware structural tokenizer that maps each graph topology into a highly selective single token. Afterwards, we construct a set of hybrid structure Question-Answering corpora to align new structural tokens with existing text tokens. With this approach, <SOG_k> empowers LLMs to understand, generate, and reason in a concise and accurate manner. Extensive experiments on five graph-level benchmarks demonstrate the superiority of our method, achieving a performance improvement of 9.9% to 41.4% compared to the baselines while exhibiting interpretability and consistency. Furthermore, our method provides a flexible extension to node-level tasks, enabling both global and local structural understanding. The codebase is publicly available at https://github.com/Jingyao-Wu/SOG.
Improving LLM Reasoning with Homophily-aware Structural and Semantic Text-Attributed Graph Compression
Jan 13, 2026Large language models (LLMs) have demonstrated promising capabilities in Text-Attributed Graph (TAG) understanding. Recent studies typically focus on verbalizing the graph structures via handcrafted prompts, feeding the target node and its neighborhood context into LLMs. However, constrained by the context window, existing methods mainly resort to random sampling, often implemented via dropping node/edge randomly, which inevitably introduces noise and cause reasoning instability. We argue that graphs inherently contain rich structural and semantic information, and that their effective exploitation can unlock potential gains in LLMs reasoning performance. To this end, we propose Homophily-aware Structural and Semantic Compression for LLMs (HS2C), a framework centered on exploiting graph homophily. Structurally, guided by the principle of Structural Entropy minimization, we perform a global hierarchical partition that decodes the graph's essential topology. This partition identifies naturally cohesive, homophilic communities, while discarding stochastic connectivity noise. Semantically, we deliver the detected structural homophily to the LLM, empowering it to perform differentiated semantic aggregation based on predefined community type. This process compresses redundant background contexts into concise community-level consensus, selectively preserving semantically homophilic information aligned with the target nodes. Extensive experiments on 10 node-level benchmarks across LLMs of varying sizes and families demonstrate that, by feeding LLMs with structurally and semantically compressed inputs, HS2C simultaneously enhances the compression rate and downstream inference accuracy, validating its superiority and scalability. Extensions to 7 diverse graph-level benchmarks further consolidate HS2C's task generalizability.
FedBook: A Unified Federated Graph Foundation Codebook with Intra-domain and Inter-domain Knowledge Modeling
Oct 09, 2025Foundation models have shown remarkable cross-domain generalization in language and vision, inspiring the development of graph foundation models (GFMs). However, existing GFMs typically assume centralized access to multi-domain graphs, which is often infeasible due to privacy and institutional constraints. Federated Graph Foundation Models (FedGFMs) address this limitation, but their effectiveness fundamentally hinges on constructing a robust global codebook that achieves intra-domain coherence by consolidating mutually reinforcing semantics within each domain, while also maintaining inter-domain diversity by retaining heterogeneous knowledge across domains. To this end, we propose FedBook, a unified federated graph foundation codebook that systematically aggregates clients' local codebooks during server-side federated pre-training. FedBook follows a two-phase process: (1) Intra-domain Collaboration, where low-frequency tokens are refined by referencing more semantically reliable high-frequency tokens across clients to enhance domain-specific coherence; and (2) Inter-domain Integration, where client contributions are weighted by the semantic distinctiveness of their codebooks during the aggregation of the global GFM, thereby preserving cross-domain diversity. Extensive experiments on 8 benchmarks across multiple domains and tasks demonstrate that FedBook consistently outperforms 21 baselines, including isolated supervised learning, FL/FGL, federated adaptations of centralized GFMs, and FedGFM techniques.
Unaligned RGB Guided Hyperspectral Image Super-Resolution with Spatial-Spectral Concordance
May 04, 2025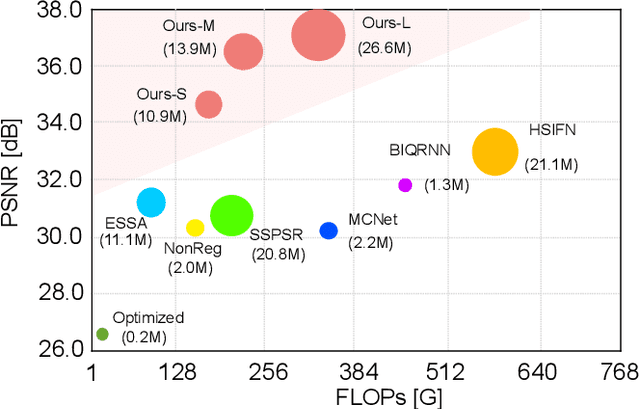
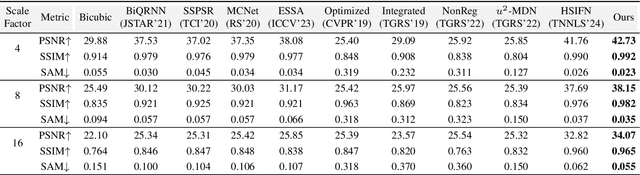

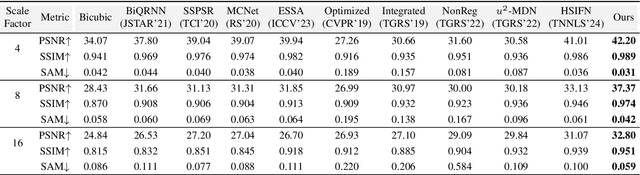
Hyperspectral images super-resolution aims to improve the spatial resolution, yet its performance is often limited at high-resolution ratios. The recent adoption of high-resolution reference images for super-resolution is driven by the poor spatial detail found in low-resolution HSIs, presenting it as a favorable method. However, these approaches cannot effectively utilize information from the reference image, due to the inaccuracy of alignment and its inadequate interaction between alignment and fusion modules. In this paper, we introduce a Spatial-Spectral Concordance Hyperspectral Super-Resolution (SSC-HSR) framework for unaligned reference RGB guided HSI SR to address the issues of inaccurate alignment and poor interactivity of the previous approaches. Specifically, to ensure spatial concordance, i.e., align images more accurately across resolutions and refine textures, we construct a Two-Stage Image Alignment with a synthetic generation pipeline in the image alignment module, where the fine-tuned optical flow model can produce a more accurate optical flow in the first stage and warp model can refine damaged textures in the second stage. To enhance the interaction between alignment and fusion modules and ensure spectral concordance during reconstruction, we propose a Feature Aggregation module and an Attention Fusion module. In the feature aggregation module, we introduce an Iterative Deformable Feature Aggregation block to achieve significant feature matching and texture aggregation with the fusion multi-scale results guidance, iteratively generating learnable offset. Besides, we introduce two basic spectral-wise attention blocks in the attention fusion module to model the inter-spectra interactions. Extensive experiments on three natural or remote-sensing datasets show that our method outperforms state-of-the-art approaches on both quantitative and qualitative evaluations.
Bayesian Cross-Modal Alignment Learning for Few-Shot Out-of-Distribution Generalization
Apr 22, 2025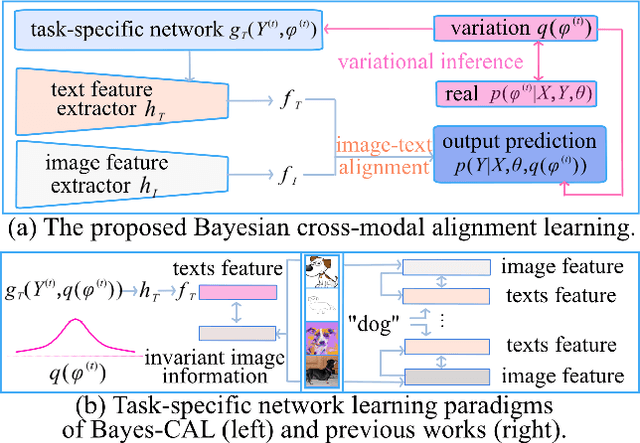
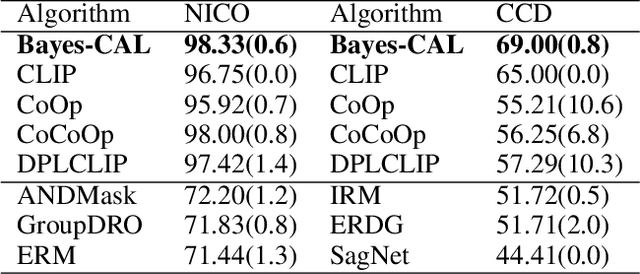
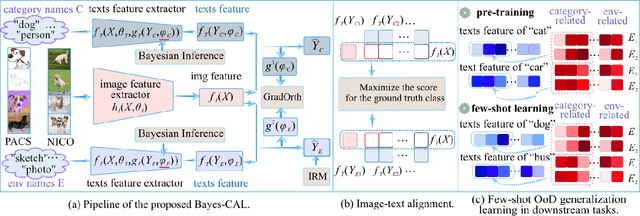
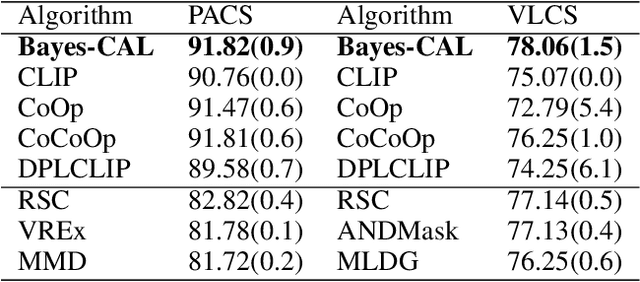
Recent advances in large pre-trained models showed promising results in few-shot learning. However, their generalization ability on two-dimensional Out-of-Distribution (OoD) data, i.e., correlation shift and diversity shift, has not been thoroughly investigated. Researches have shown that even with a significant amount of training data, few methods can achieve better performance than the standard empirical risk minimization method (ERM) in OoD generalization. This few-shot OoD generalization dilemma emerges as a challenging direction in deep neural network generalization research, where the performance suffers from overfitting on few-shot examples and OoD generalization errors. In this paper, leveraging a broader supervision source, we explore a novel Bayesian cross-modal image-text alignment learning method (Bayes-CAL) to address this issue. Specifically, the model is designed as only text representations are fine-tuned via a Bayesian modelling approach with gradient orthogonalization loss and invariant risk minimization (IRM) loss. The Bayesian approach is essentially introduced to avoid overfitting the base classes observed during training and improve generalization to broader unseen classes. The dedicated loss is introduced to achieve better image-text alignment by disentangling the causal and non-casual parts of image features. Numerical experiments demonstrate that Bayes-CAL achieved state-of-the-art OoD generalization performances on two-dimensional distribution shifts. Moreover, compared with CLIP-like models, Bayes-CAL yields more stable generalization performances on unseen classes. Our code is available at https://github.com/LinLLLL/BayesCAL.
Towards Unbiased Federated Graph Learning: Label and Topology Perspectives
Apr 14, 2025Federated Graph Learning (FGL) enables privacy-preserving, distributed training of graph neural networks without sharing raw data. Among its approaches, subgraph-FL has become the dominant paradigm, with most work focused on improving overall node classification accuracy. However, these methods often overlook fairness due to the complexity of node features, labels, and graph structures. In particular, they perform poorly on nodes with disadvantaged properties, such as being in the minority class within subgraphs or having heterophilous connections (neighbors with dissimilar labels or misleading features). This reveals a critical issue: high accuracy can mask degraded performance on structurally or semantically marginalized nodes. To address this, we advocate for two fairness goals: (1) improving representation of minority class nodes for class-wise fairness and (2) mitigating topological bias from heterophilous connections for topology-aware fairness. We propose FairFGL, a novel framework that enhances fairness through fine-grained graph mining and collaborative learning. On the client side, the History-Preserving Module prevents overfitting to dominant local classes, while the Majority Alignment Module refines representations of heterophilous majority-class nodes. The Gradient Modification Module transfers minority-class knowledge from structurally favorable clients to improve fairness. On the server side, FairFGL uploads only the most influenced subset of parameters to reduce communication costs and better reflect local distributions. A cluster-based aggregation strategy reconciles conflicting updates and curbs global majority dominance . Extensive evaluations on eight benchmarks show FairFGL significantly improves minority-group performance , achieving up to a 22.62 percent Macro-F1 gain while enhancing convergence over state-of-the-art baselines.
InfoBound: A Provable Information-Bounds Inspired Framework for Both OoD Generalization and OoD Detection
Apr 13, 2025In real-world scenarios, distribution shifts give rise to the importance of two problems: out-of-distribution (OoD) generalization, which focuses on models' generalization ability against covariate shifts (i.e., the changes of environments), and OoD detection, which aims to be aware of semantic shifts (i.e., test-time unseen classes). Real-world testing environments often involve a combination of both covariate and semantic shifts. While numerous methods have been proposed to address these critical issues, only a few works tackled them simultaneously. Moreover, prior works often improve one problem but sacrifice the other. To overcome these limitations, we delve into boosting OoD detection and OoD generalization from the perspective of information theory, which can be easily applied to existing models and different tasks. Building upon the theoretical bounds for mutual information and conditional entropy, we provide a unified approach, composed of Mutual Information Minimization (MI-Min) and Conditional Entropy Maximizing (CE-Max). Extensive experiments and comprehensive evaluations on multi-label image classification and object detection have demonstrated the superiority of our method. It successfully mitigates trade-offs between the two challenges compared to competitive baselines.
Federated Prototype Graph Learning
Apr 13, 2025In recent years, Federated Graph Learning (FGL) has gained significant attention for its distributed training capabilities in graph-based machine intelligence applications, mitigating data silos while offering a new perspective for privacy-preserve large-scale graph learning. However, multi-level FGL heterogeneity presents various client-server collaboration challenges: (1) Model-level: The variation in clients for expected performance and scalability necessitates the deployment of heterogeneous models. Unfortunately, most FGL methods rigidly demand identical client models due to the direct model weight aggregation on the server. (2) Data-level: The intricate nature of graphs, marked by the entanglement of node profiles and topology, poses an optimization dilemma. This implies that models obtained by federated training struggle to achieve superior performance. (3) Communication-level: Some FGL methods attempt to increase message sharing among clients or between clients and the server to improve training, which inevitably leads to high communication costs. In this paper, we propose FedPG as a general prototype-guided optimization method for the above multi-level FGL heterogeneity. Specifically, on the client side, we integrate multi-level topology-aware prototypes to capture local graph semantics. Subsequently, on the server side, leveraging the uploaded prototypes, we employ topology-guided contrastive learning and personalized technology to tailor global prototypes for each client, broadcasting them to improve local training. Experiments demonstrate that FedPG outperforms SOTA baselines by an average of 3.57\% in accuracy while reducing communication costs by 168x.
Less is More: Masking Elements in Image Condition Features Avoids Content Leakages in Style Transfer Diffusion Models
Feb 11, 2025Given a style-reference image as the additional image condition, text-to-image diffusion models have demonstrated impressive capabilities in generating images that possess the content of text prompts while adopting the visual style of the reference image. However, current state-of-the-art methods often struggle to disentangle content and style from style-reference images, leading to issues such as content leakages. To address this issue, we propose a masking-based method that efficiently decouples content from style without the need of tuning any model parameters. By simply masking specific elements in the style reference's image features, we uncover a critical yet under-explored principle: guiding with appropriately-selected fewer conditions (e.g., dropping several image feature elements) can efficiently avoid unwanted content flowing into the diffusion models, enhancing the style transfer performances of text-to-image diffusion models. In this paper, we validate this finding both theoretically and experimentally. Extensive experiments across various styles demonstrate the effectiveness of our masking-based method and support our theoretical results.
Synergistic Development of Perovskite Memristors and Algorithms for Robust Analog Computing
Dec 03, 2024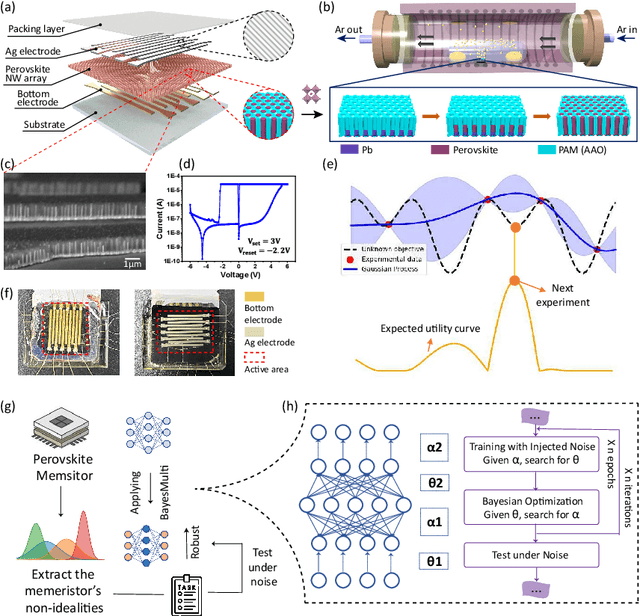

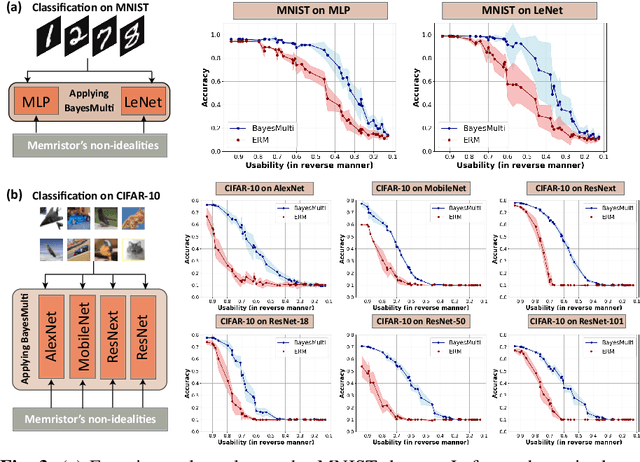
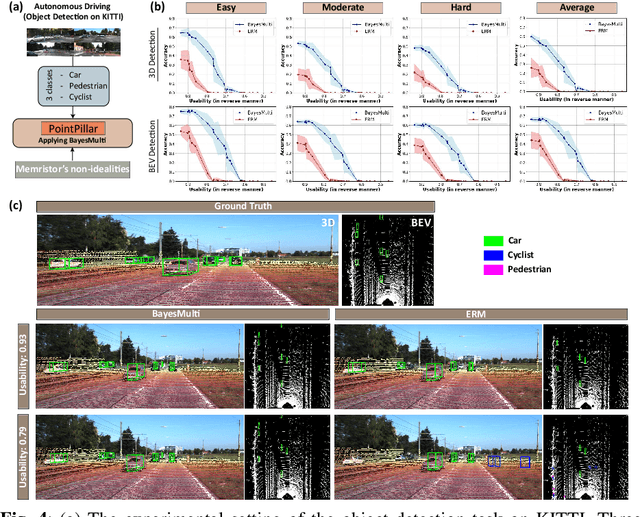
Analog computing using non-volatile memristors has emerged as a promising solution for energy-efficient deep learning. New materials, like perovskites-based memristors are recently attractive due to their cost-effectiveness, energy efficiency and flexibility. Yet, challenges in material diversity and immature fabrications require extensive experimentation for device development. Moreover, significant non-idealities in these memristors often impede them for computing. Here, we propose a synergistic methodology to concurrently optimize perovskite memristor fabrication and develop robust analog DNNs that effectively address the inherent non-idealities of these memristors. Employing Bayesian optimization (BO) with a focus on usability, we efficiently identify optimal materials and fabrication conditions for perovskite memristors. Meanwhile, we developed "BayesMulti", a DNN training strategy utilizing BO-guided noise injection to improve the resistance of analog DNNs to memristor imperfections. Our approach theoretically ensures that within a certain range of parameter perturbations due to memristor non-idealities, the prediction outcomes remain consistent. Our integrated approach enables use of analog computing in much deeper and wider networks, which significantly outperforms existing methods in diverse tasks like image classification, autonomous driving, species identification, and large vision-language models, achieving up to 100-fold improvements. We further validate our methodology on a 10$\times$10 optimized perovskite memristor crossbar, demonstrating high accuracy in a classification task and low energy consumption. This study offers a versatile solution for efficient optimization of various analog computing systems, encompassing both devices and algorithms.