 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to Edge<SOG_k>: One LLM Token for Explicit Graph Structural Understanding
Feb 02, 2026Large language models show great potential in unstructured data understanding, but still face significant challenges with graphs due to their structural hallucination. Existing approaches mainly either verbalize graphs into natural language, which leads to excessive token consumption and scattered attention, or transform graphs into trainable continuous embeddings (i.e., soft prompt), but exhibit severe misalignment with original text tokens. To solve this problem, we propose to incorporate one special token <SOG_k> to fully represent the Structure Of Graph within a unified token space, facilitating explicit topology input and structural information sharing. Specifically, we propose a topology-aware structural tokenizer that maps each graph topology into a highly selective single token. Afterwards, we construct a set of hybrid structure Question-Answering corpora to align new structural tokens with existing text tokens. With this approach, <SOG_k> empowers LLMs to understand, generate, and reason in a concise and accurate manner. Extensive experiments on five graph-level benchmarks demonstrate the superiority of our method, achieving a performance improvement of 9.9% to 41.4% compared to the baselines while exhibiting interpretability and consistency. Furthermore, our method provides a flexible extension to node-level tasks, enabling both global and local structural understanding. The codebase is publicly available at https://github.com/Jingyao-Wu/SOG.
Improving LLM Reasoning with Homophily-aware Structural and Semantic Text-Attributed Graph Compression
Jan 13, 2026Large language models (LLMs) have demonstrated promising capabilities in Text-Attributed Graph (TAG) understanding. Recent studies typically focus on verbalizing the graph structures via handcrafted prompts, feeding the target node and its neighborhood context into LLMs. However, constrained by the context window, existing methods mainly resort to random sampling, often implemented via dropping node/edge randomly, which inevitably introduces noise and cause reasoning instability. We argue that graphs inherently contain rich structural and semantic information, and that their effective exploitation can unlock potential gains in LLMs reasoning performance. To this end, we propose Homophily-aware Structural and Semantic Compression for LLMs (HS2C), a framework centered on exploiting graph homophily. Structurally, guided by the principle of Structural Entropy minimization, we perform a global hierarchical partition that decodes the graph's essential topology. This partition identifies naturally cohesive, homophilic communities, while discarding stochastic connectivity noise. Semantically, we deliver the detected structural homophily to the LLM, empowering it to perform differentiated semantic aggregation based on predefined community type. This process compresses redundant background contexts into concise community-level consensus, selectively preserving semantically homophilic information aligned with the target nodes. Extensive experiments on 10 node-level benchmarks across LLMs of varying sizes and families demonstrate that, by feeding LLMs with structurally and semantically compressed inputs, HS2C simultaneously enhances the compression rate and downstream inference accuracy, validating its superiority and scalability. Extensions to 7 diverse graph-level benchmarks further consolidate HS2C's task generalizability.
CHAINSFORMER: Numerical Reasoning on Knowledge Graphs from a Chain Perspective
Apr 19, 2025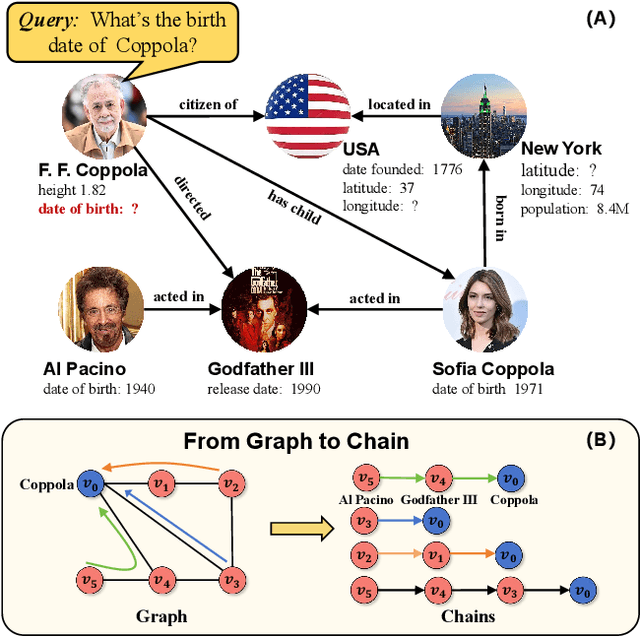
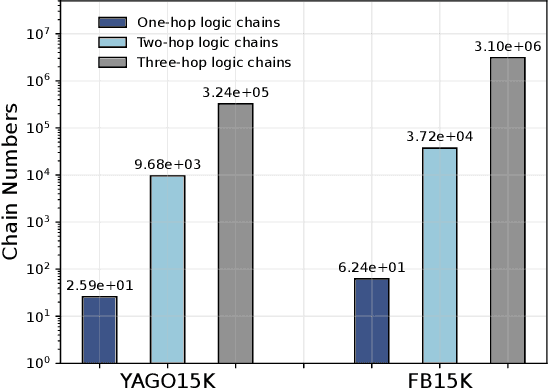
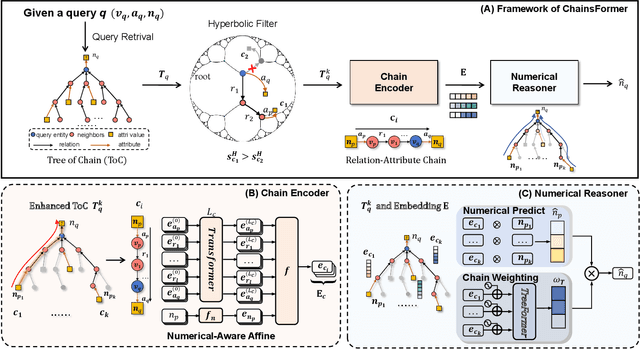
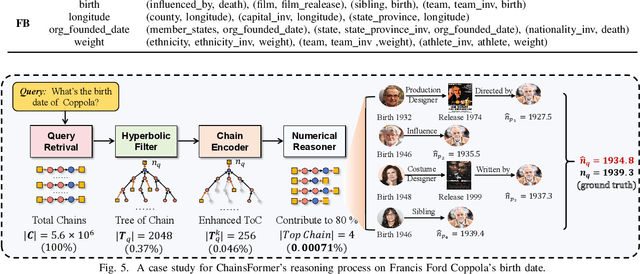
Reasoning over Knowledge Graphs (KGs) plays a pivotal role in knowledge graph completion or question answering systems, providing richer and more accurate triples and attributes. As numerical attributes become increasingly essential in characterizing entities and relations in KGs, the ability to reason over these attributes has gained significant importance. Existing graph-based methods such as Graph Neural Networks (GNNs) and Knowledge Graph Embeddings (KGEs), primarily focus on aggregating homogeneous local neighbors and implicitly embedding diverse triples. However, these approaches often fail to fully leverage the potential of logical paths within the graph, limiting their effectiveness in exploiting the reasoning process. To address these limitations, we propose ChainsFormer, a novel chain-based framework designed to support numerical reasoning. Chainsformer not only explicitly constructs logical chains but also expands the reasoning depth to multiple hops. Specially, we introduces Relation-Attribute Chains (RA-Chains), a specialized logic chain, to model sequential reasoning patterns. ChainsFormer captures the step-by-step nature of multi-hop reasoning along RA-Chains by employing sequential in-context learning. To mitigate the impact of noisy chains, we propose a hyperbolic affinity scoring mechanism that selects relevant logic chains in a variable-resolution space. Furthermore, ChainsFormer incorporates an attention-based numerical reasoner to identify critical reasoning paths, enhancing both reasoning accuracy and transparency. Experimental results demonstrate that ChainsFormer significantly outperforms state-of-the-art methods, achieving up to a 20.0% improvement in performance. The implementations are available at https://github.com/zhaodazhuang2333/ChainsFormer.
AceParse: A Comprehensive Dataset with Diverse Structured Texts for Academic Literature Parsing
Sep 16, 2024With the development of data-centric AI, the focus has shifted from model-driven approaches to improving data quality. Academic literature, as one of the crucial types, is predominantly stored in PDF formats and needs to be parsed into texts before further processing. However, parsing diverse structured texts in academic literature remains challenging due to the lack of datasets that cover various text structures. In this paper, we introduce AceParse, the first comprehensive dataset designed to support the parsing of a wide range of structured texts, including formulas, tables, lists, algorithms, and sentences with embedded mathematical expressions. Based on AceParse, we fine-tuned a multimodal model, named AceParser, which accurately parses various structured texts within academic literature. This model outperforms the previous state-of-the-art by 4.1% in terms of F1 score and by 5% in Jaccard Similarity, demonstrating the potential of multimodal models in academic literature parsing. Our dataset is available at https://github.com/JHW5981/AceParse.
AutoFAIR : Automatic Data FAIRification via Machine Reading
Aug 07, 2024



The explosive growth of data fuels data-driven research, facilitating progress across diverse domains. The FAIR principles emerge as a guiding standard, aiming to enhance the findability, accessibility, interoperability, and reusability of data. However, current efforts primarily focus on manual data FAIRification, which can only handle targeted data and lack efficiency. To address this issue, we propose AutoFAIR, an architecture designed to enhance data FAIRness automately. Firstly, We align each data and metadata operation with specific FAIR indicators to guide machine-executable actions. Then, We utilize Web Reader to automatically extract metadata based on language models, even in the absence of structured data webpage schemas. Subsequently, FAIR Alignment is employed to make metadata comply with FAIR principles by ontology guidance and semantic matching. Finally, by applying AutoFAIR to various data, especially in the field of mountain hazards, we observe significant improvements in findability, accessibility, interoperability, and reusability of data. The FAIRness scores before and after applying AutoFAIR indicate enhanced data value.
OXYGENERATOR: Reconstructing Global Ocean Deoxygenation Over a Century with Deep Learning
May 12, 2024



Accurately reconstructing the global ocean deoxygenation over a century is crucial for assessing and protecting marine ecosystem. Existing expert-dominated numerical simulations fail to catch up with the dynamic variation caused by global warming and human activities. Besides, due to the high-cost data collection, the historical observations are severely sparse, leading to big challenge for precise reconstruction. In this work, we propose OxyGenerator, the first deep learning based model, to reconstruct the global ocean deoxygenation from 1920 to 2023. Specifically, to address the heterogeneity across large temporal and spatial scales, we propose zoning-varying graph message-passing to capture the complex oceanographic correlations between missing values and sparse observations. Additionally, to further calibrate the uncertainty, we incorporate inductive bias from dissolved oxygen (DO) variations and chemical effects. Compared with in-situ DO observations, OxyGenerator significantly outperforms CMIP6 numerical simulations, reducing MAPE by 38.77%, demonstrating a promising potential to understand the "breathless ocean" in data-driven manner.
Temporal Generalization Estimation in Evolving Graphs
Apr 07, 2024



Graph Neural Networks (GNNs) are widely deployed in vast fields, but they often struggle to maintain accurate representations as graphs evolve. We theoretically establish a lower bound, proving that under mild conditions, representation distortion inevitably occurs over time. To estimate the temporal distortion without human annotation after deployment, one naive approach is to pre-train a recurrent model (e.g., RNN) before deployment and use this model afterwards, but the estimation is far from satisfactory. In this paper, we analyze the representation distortion from an information theory perspective, and attribute it primarily to inaccurate feature extraction during evolution. Consequently, we introduce Smart, a straightforward and effective baseline enhanced by an adaptive feature extractor through self-supervised graph reconstruction. In synthetic random graphs, we further refine the former lower bound to show the inevitable distortion over time and empirically observe that Smart achieves good estimation performance. Moreover, we observe that Smart consistently shows outstanding generalization estimation on four real-world evolving graphs. The ablation studies underscore the necessity of graph reconstruction. For example, on OGB-arXiv dataset, the estimation metric MAPE deteriorates from 2.19% to 8.00% without reconstruction.
AceMap: Knowledge Discovery through Academic Graph
Mar 05, 2024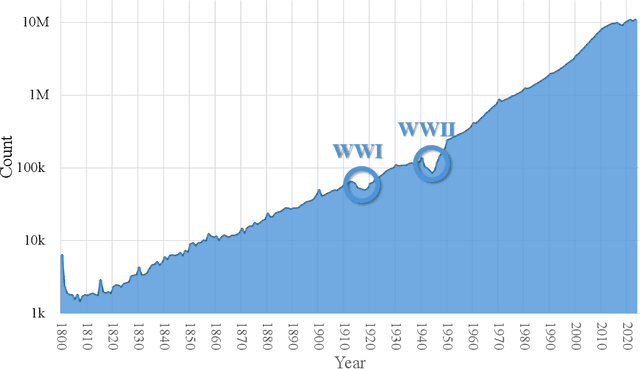
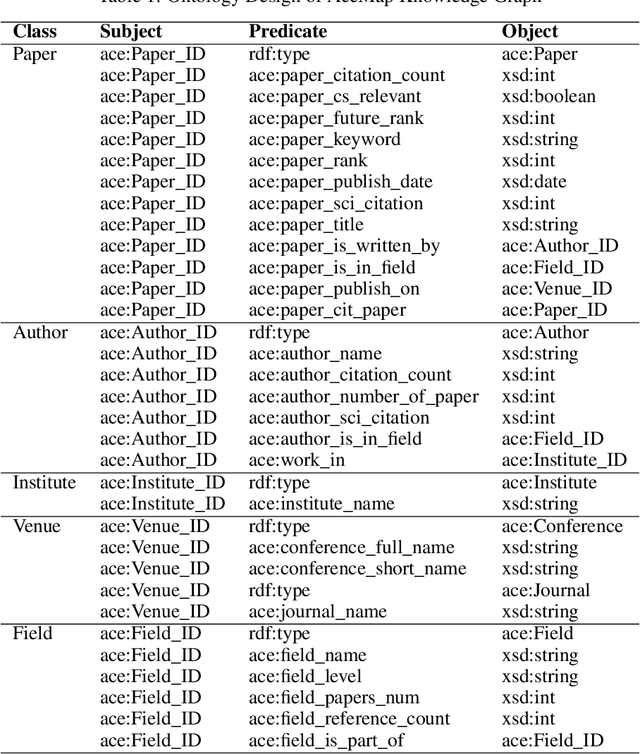
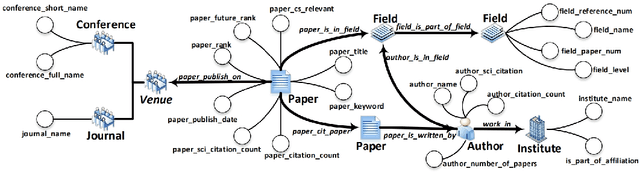
The exponential growth of scientific literature requires effective management and extraction of valuable insights. While existing scientific search engines excel at delivering search results based on relational databases, they often neglect the analysis of collaborations between scientific entities and the evolution of ideas, as well as the in-depth analysis of content within scientific publications. The representation of heterogeneous graphs and the effective measurement, analysis, and mining of such graphs pose significant challenges. To address these challenges, we present AceMap, an academic system designed for knowledge discovery through academic graph. We present advanced database construction techniques to build the comprehensive AceMap database with large-scale academic publications that contain rich visual, textual, and numerical information. AceMap also employs innovative visualization, quantification, and analysis methods to explore associations and logical relationships among academic entities. AceMap introduces large-scale academic network visualization techniques centered on nebular graphs, providing a comprehensive view of academic networks from multiple perspectives. In addition, AceMap proposes a unified metric based on structural entropy to quantitatively measure the knowledge content of different academic entities. Moreover, AceMap provides advanced analysis capabilities, including tracing the evolution of academic ideas through citation relationships and concept co-occurrence, and generating concise summaries informed by this evolutionary process. In addition, AceMap uses machine reading methods to generate potential new ideas at the intersection of different fields. Exploring the integration of large language models and knowledge graphs is a promising direction for future research in idea evolution. Please visit \url{https://www.acemap.info} for further exploration.
Graph Out-of-Distribution Generalization with Controllable Data Augmentation
Aug 16, 2023


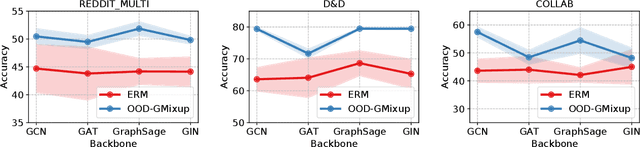
Graph Neural Network (GNN) has demonstrated extraordinary performance in classifying graph properties. However, due to the selection bias of training and testing data (e.g., training on small graphs and testing on large graphs, or training on dense graphs and testing on sparse graphs), distribution deviation is widespread. More importantly, we often observe \emph{hybrid structure distribution shift} of both scale and density, despite of one-sided biased data partition. The spurious correlations over hybrid distribution deviation degrade the performance of previous GNN methods and show large instability among different datasets. To alleviate this problem, we propose \texttt{OOD-GMixup} to jointly manipulate the training distribution with \emph{controllable data augmentation} in metric space. Specifically, we first extract the graph rationales to eliminate the spurious correlations due to irrelevant information. Secondly, we generate virtual samples with perturbation on graph rationale representation domain to obtain potential OOD training samples. Finally, we propose OOD calibration to measure the distribution deviation of virtual samples by leveraging Extreme Value Theory, and further actively control the training distribution by emphasizing the impact of virtual OOD samples. Extensive studies on several real-world datasets on graph classification demonstrate the superiority of our proposed method over state-of-the-art baselines.
Spatio-Temporal Graph Few-Shot Learning with Cross-City Knowledge Transfer
Jun 03, 2022

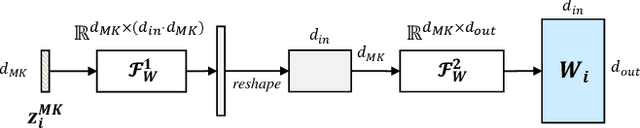

Spatio-temporal graph learning is a key method for urban computing tasks, such as traffic flow, taxi demand and air quality forecasting. Due to the high cost of data collection, some developing cities have few available data, which makes it infeasible to train a well-performed model. To address this challenge, cross-city knowledge transfer has shown its promise, where the model learned from data-sufficient cities is leveraged to benefit the learning process of data-scarce cities. However, the spatio-temporal graphs among different cities show irregular structures and varied features, which limits the feasibility of existing Few-Shot Learning (\emph{FSL}) methods. Therefore, we propose a model-agnostic few-shot learning framework for spatio-temporal graph called ST-GFSL. Specifically, to enhance feature extraction by transfering cross-city knowledge, ST-GFSL proposes to generate non-shared parameters based on node-level meta knowledge. The nodes in target city transfer the knowledge via parameter matching, retrieving from similar spatio-temporal characteristics. Furthermore, we propose to reconstruct the graph structure during meta-learning. The graph reconstruction loss is defined to guide structure-aware learning, avoiding structure deviation among different datasets. We conduct comprehensive experiments on four traffic speed prediction benchmarks and the results demonstrate the effectiveness of ST-GFSL compared with state-of-the-art methods.