 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInductive Reasoning for Temporal Knowledge Graphs with Emerging Entities
Apr 11, 2026Reasoning on Temporal Knowledge Graphs (TKGs) is essential for predicting future events and time-aware facts. While existing methods are effective at capturing relational dynamics, their performance is limited by a closed-world assumption, which fails to account for emerging entities not present in the training. Notably, these entities continuously join the network without historical interactions. Empirical study reveals that emerging entities are widespread in TKGs, comprising roughly 25\% of all entities. The absence of historical interactions of these entities leads to significant performance degradation in reasoning tasks. Whereas, we observe that entities with semantic similarities often exhibit comparable interaction histories, suggesting the presence of transferable temporal patterns. Inspired by this insight, we propose TransFIR (Transferable Inductive Reasoning), a novel framework that leverages historical interaction sequences from semantically similar known entities to support inductive reasoning. Specifically, we propose a codebook-based classifier that categorizes emerging entities into latent semantic clusters, allowing them to adopt reasoning patterns from similar entities. Experimental results demonstrate that TransFIR outperforms all baselines in reasoning on emerging entities, achieving an average improvement of 28.6% in Mean Reciprocal Rank (MRR) across multiple datasets. The implementations are available at https://github.com/zhaodazhuang2333/TransFIR.
Efficient Document Parsing via Parallel Token Prediction
Mar 16, 2026Document parsing, as a fundamental yet crucial vision task, is being revolutionized by vision-language models (VLMs). However, the autoregressive (AR) decoding inherent to VLMs creates a significant bottleneck, severely limiting parsing speed. In this paper, we propose Parallel-Token Prediction (PTP), a plugable, model-agnostic and simple-yet-effective method that enables VLMs to generate multiple future tokens in parallel with improved sample efficiency. Specifically, we insert some learnable tokens into the input sequence and design corresponding training objectives to equip the model with parallel decoding capabilities for document parsing. Furthermore, to support effective training, we develop a comprehensive data generation pipeline that efficiently produces large-scale, high-quality document parsing training data for VLMs. Extensive experiments on OmniDocBench and olmOCR-bench demonstrate that our method not only significantly improves decoding speed (1.6x-2.2x) but also reduces model hallucinations and exhibits strong generalization abilities.
CHAINSFORMER: Numerical Reasoning on Knowledge Graphs from a Chain Perspective
Apr 19, 2025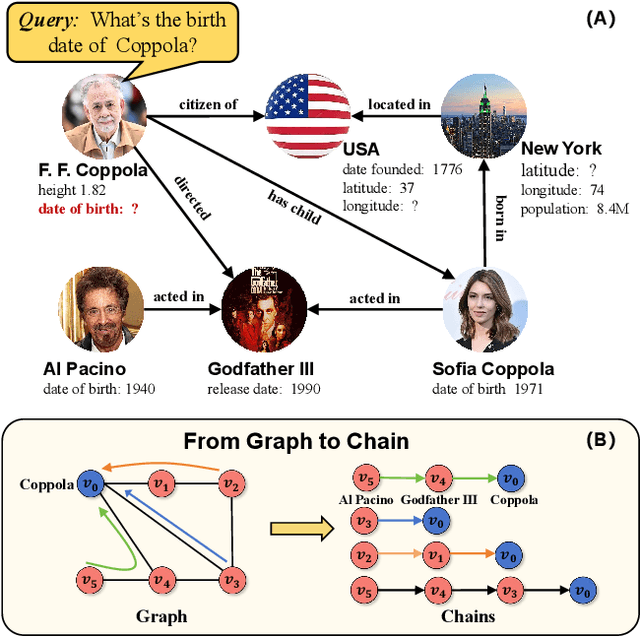
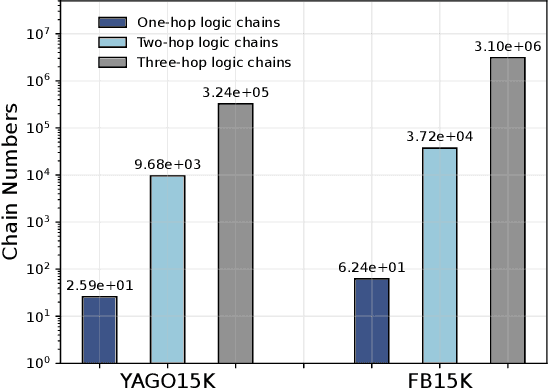
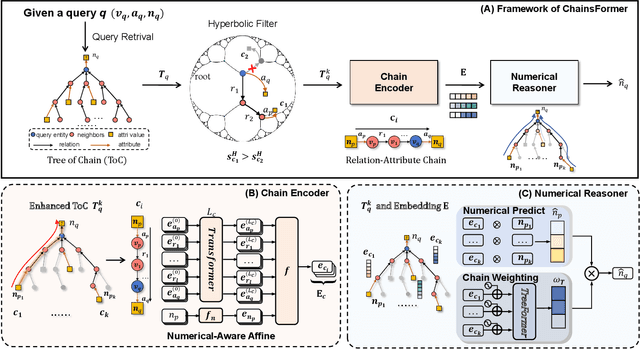
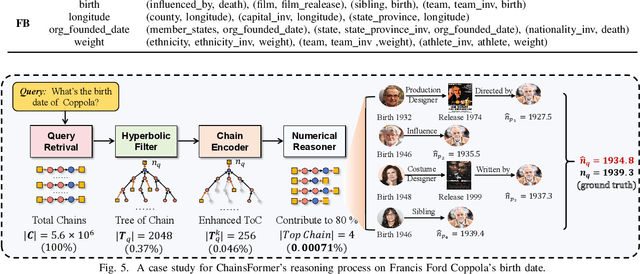
Reasoning over Knowledge Graphs (KGs) plays a pivotal role in knowledge graph completion or question answering systems, providing richer and more accurate triples and attributes. As numerical attributes become increasingly essential in characterizing entities and relations in KGs, the ability to reason over these attributes has gained significant importance. Existing graph-based methods such as Graph Neural Networks (GNNs) and Knowledge Graph Embeddings (KGEs), primarily focus on aggregating homogeneous local neighbors and implicitly embedding diverse triples. However, these approaches often fail to fully leverage the potential of logical paths within the graph, limiting their effectiveness in exploiting the reasoning process. To address these limitations, we propose ChainsFormer, a novel chain-based framework designed to support numerical reasoning. Chainsformer not only explicitly constructs logical chains but also expands the reasoning depth to multiple hops. Specially, we introduces Relation-Attribute Chains (RA-Chains), a specialized logic chain, to model sequential reasoning patterns. ChainsFormer captures the step-by-step nature of multi-hop reasoning along RA-Chains by employing sequential in-context learning. To mitigate the impact of noisy chains, we propose a hyperbolic affinity scoring mechanism that selects relevant logic chains in a variable-resolution space. Furthermore, ChainsFormer incorporates an attention-based numerical reasoner to identify critical reasoning paths, enhancing both reasoning accuracy and transparency. Experimental results demonstrate that ChainsFormer significantly outperforms state-of-the-art methods, achieving up to a 20.0% improvement in performance. The implementations are available at https://github.com/zhaodazhuang2333/ChainsFormer.
KPIs 2024 Challenge: Advancing Glomerular Segmentation from Patch- to Slide-Level
Feb 11, 2025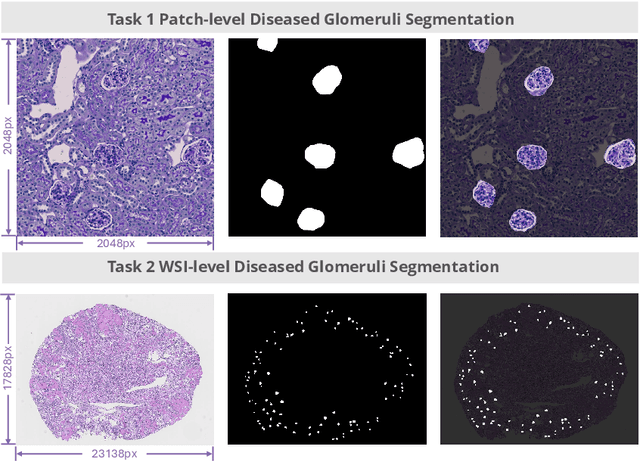

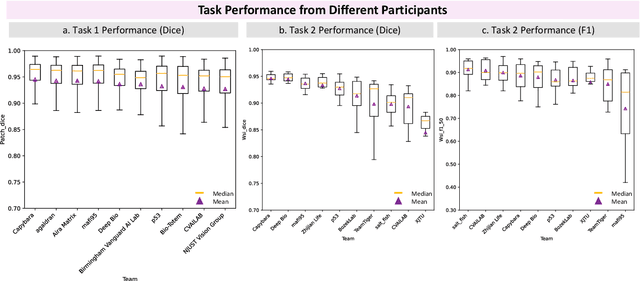

Chronic kidney disease (CKD) is a major global health issue, affecting over 10% of the population and causing significant mortality. While kidney biopsy remains the gold standard for CKD diagnosis and treatment, the lack of comprehensive benchmarks for kidney pathology segmentation hinders progress in the field. To address this, we organized the Kidney Pathology Image Segmentation (KPIs) Challenge, introducing a dataset that incorporates preclinical rodent models of CKD with over 10,000 annotated glomeruli from 60+ Periodic Acid Schiff (PAS)-stained whole slide images. The challenge includes two tasks, patch-level segmentation and whole slide image segmentation and detection, evaluated using the Dice Similarity Coefficient (DSC) and F1-score. By encouraging innovative segmentation methods that adapt to diverse CKD models and tissue conditions, the KPIs Challenge aims to advance kidney pathology analysis, establish new benchmarks, and enable precise, large-scale quantification for disease research and diagnosis.
Hunyuan-Large: An Open-Source MoE Model with 52 Billion Activated Parameters by Tencent
Nov 05, 2024



In this paper, we introduce Hunyuan-Large, which is currently the largest open-source Transformer-based mixture of experts model, with a total of 389 billion parameters and 52 billion activation parameters, capable of handling up to 256K tokens. We conduct a thorough evaluation of Hunyuan-Large's superior performance across various benchmarks including language understanding and generation, logical reasoning, mathematical problem-solving, coding, long-context, and aggregated tasks, where it outperforms LLama3.1-70B and exhibits comparable performance when compared to the significantly larger LLama3.1-405B model. Key practice of Hunyuan-Large include large-scale synthetic data that is orders larger than in previous literature, a mixed expert routing strategy, a key-value cache compression technique, and an expert-specific learning rate strategy. Additionally, we also investigate the scaling laws and learning rate schedule of mixture of experts models, providing valuable insights and guidances for future model development and optimization. The code and checkpoints of Hunyuan-Large are released to facilitate future innovations and applications. Codes: https://github.com/Tencent/Hunyuan-Large Models: https://huggingface.co/tencent/Tencent-Hunyuan-Large
Cross-Organ and Cross-Scanner Adenocarcinoma Segmentation using Rein to Fine-tune Vision Foundation Models
Sep 19, 2024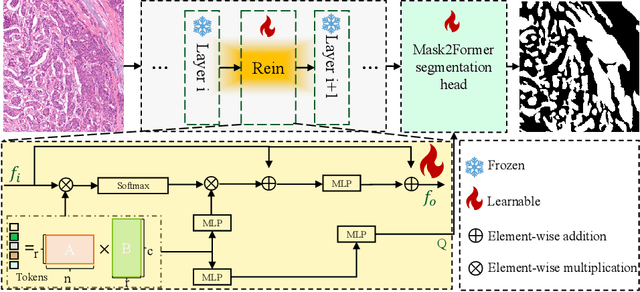

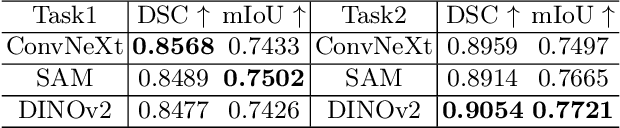

In recent years, significant progress has been made in tumor segmentation within the field of digital pathology. However, variations in organs, tissue preparation methods, and image acquisition processes can lead to domain discrepancies among digital pathology images. To address this problem, in this paper, we use Rein, a fine-tuning method, to parametrically and efficiently fine-tune various vision foundation models (VFMs) for MICCAI 2024 Cross-Organ and Cross-Scanner Adenocarcinoma Segmentation (COSAS2024). The core of Rein consists of a set of learnable tokens, which are directly linked to instances, improving functionality at the instance level in each layer. In the data environment of the COSAS2024 Challenge, extensive experiments demonstrate that Rein fine-tuned the VFMs to achieve satisfactory results. Specifically, we used Rein to fine-tune ConvNeXt and DINOv2. Our team used the former to achieve scores of 0.7719 and 0.7557 on the preliminary test phase and final test phase in task1, respectively, while the latter achieved scores of 0.8848 and 0.8192 on the preliminary test phase and final test phase in task2. Code is available at GitHub.
OXYGENERATOR: Reconstructing Global Ocean Deoxygenation Over a Century with Deep Learning
May 12, 2024



Accurately reconstructing the global ocean deoxygenation over a century is crucial for assessing and protecting marine ecosystem. Existing expert-dominated numerical simulations fail to catch up with the dynamic variation caused by global warming and human activities. Besides, due to the high-cost data collection, the historical observations are severely sparse, leading to big challenge for precise reconstruction. In this work, we propose OxyGenerator, the first deep learning based model, to reconstruct the global ocean deoxygenation from 1920 to 2023. Specifically, to address the heterogeneity across large temporal and spatial scales, we propose zoning-varying graph message-passing to capture the complex oceanographic correlations between missing values and sparse observations. Additionally, to further calibrate the uncertainty, we incorporate inductive bias from dissolved oxygen (DO) variations and chemical effects. Compared with in-situ DO observations, OxyGenerator significantly outperforms CMIP6 numerical simulations, reducing MAPE by 38.77%, demonstrating a promising potential to understand the "breathless ocean" in data-driven manner.
Graph Out-of-Distribution Generalization with Controllable Data Augmentation
Aug 16, 2023


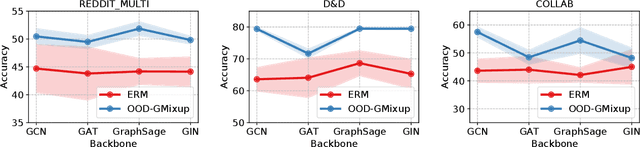
Graph Neural Network (GNN) has demonstrated extraordinary performance in classifying graph properties. However, due to the selection bias of training and testing data (e.g., training on small graphs and testing on large graphs, or training on dense graphs and testing on sparse graphs), distribution deviation is widespread. More importantly, we often observe \emph{hybrid structure distribution shift} of both scale and density, despite of one-sided biased data partition. The spurious correlations over hybrid distribution deviation degrade the performance of previous GNN methods and show large instability among different datasets. To alleviate this problem, we propose \texttt{OOD-GMixup} to jointly manipulate the training distribution with \emph{controllable data augmentation} in metric space. Specifically, we first extract the graph rationales to eliminate the spurious correlations due to irrelevant information. Secondly, we generate virtual samples with perturbation on graph rationale representation domain to obtain potential OOD training samples. Finally, we propose OOD calibration to measure the distribution deviation of virtual samples by leveraging Extreme Value Theory, and further actively control the training distribution by emphasizing the impact of virtual OOD samples. Extensive studies on several real-world datasets on graph classification demonstrate the superiority of our proposed method over state-of-the-art baselines.
A Comprehensive Evaluation Framework for Deep Model Robustness
Jan 24, 2021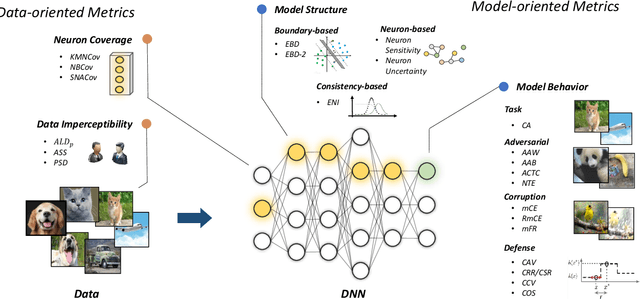
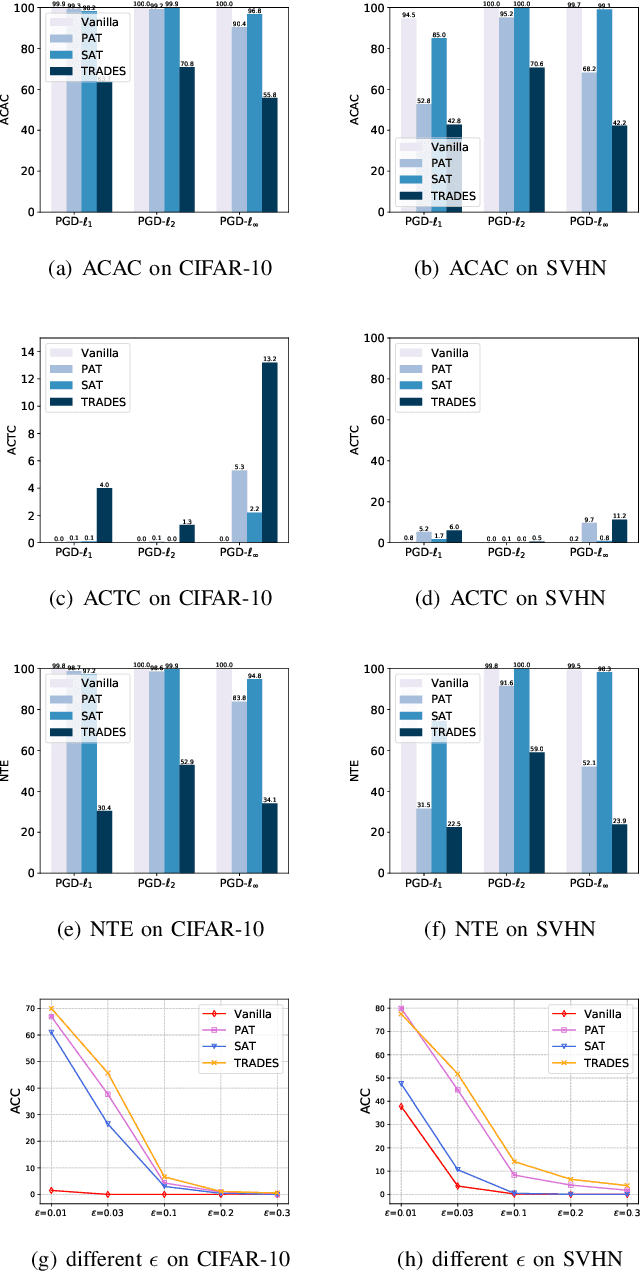
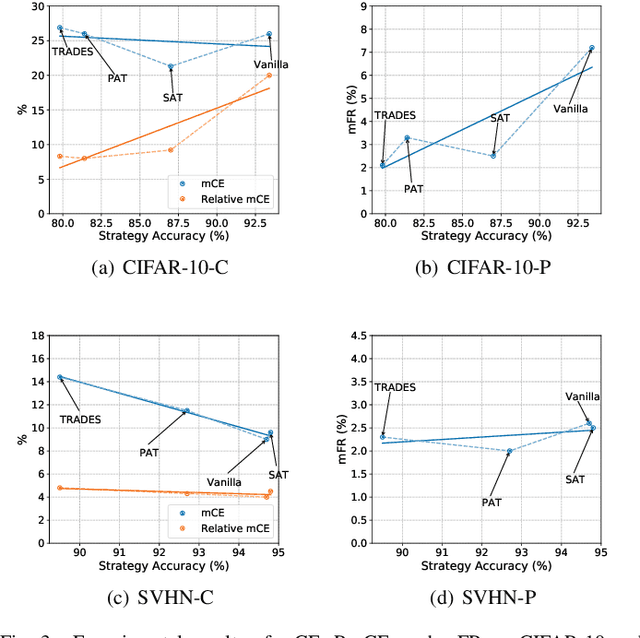
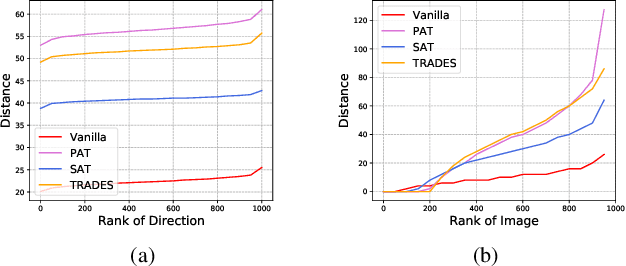
Deep neural networks (DNNs) have achieved remarkable performance across a wide area of applications. However, they are vulnerable to adversarial examples, which motivates the adversarial defense. By adopting simple evaluation metrics, most of the current defenses only conduct incomplete evaluations, which are far from providing comprehensive understandings of the limitations of these defenses. Thus, most proposed defenses are quickly shown to be attacked successfully, which result in the "arm race" phenomenon between attack and defense. To mitigate this problem, we establish a model robustness evaluation framework containing a comprehensive, rigorous, and coherent set of evaluation metrics, which could fully evaluate model robustness and provide deep insights into building robust models. With 23 evaluation metrics in total, our framework primarily focuses on the two key factors of adversarial learning (\ie, data and model). Through neuron coverage and data imperceptibility, we use data-oriented metrics to measure the integrity of test examples; by delving into model structure and behavior, we exploit model-oriented metrics to further evaluate robustness in the adversarial setting. To fully demonstrate the effectiveness of our framework, we conduct large-scale experiments on multiple datasets including CIFAR-10 and SVHN using different models and defenses with our open-source platform AISafety. Overall, our paper aims to provide a comprehensive evaluation framework which could demonstrate detailed inspections of the model robustness, and we hope that our paper can inspire further improvement to the model robustness.