 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePoint Contrastive Prediction with Semantic Clustering for Self-Supervised Learning on Point Cloud Videos
Aug 18, 2023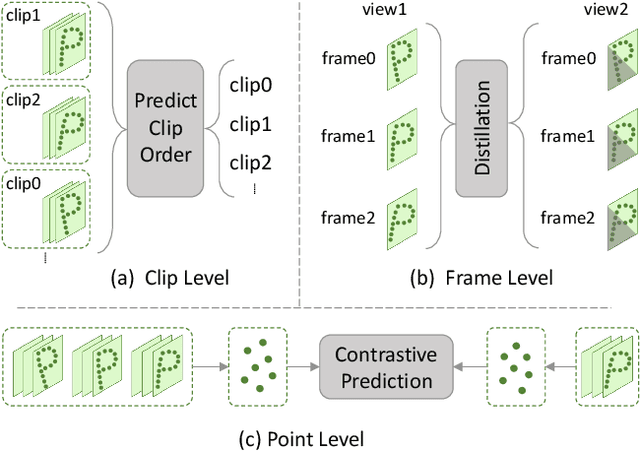
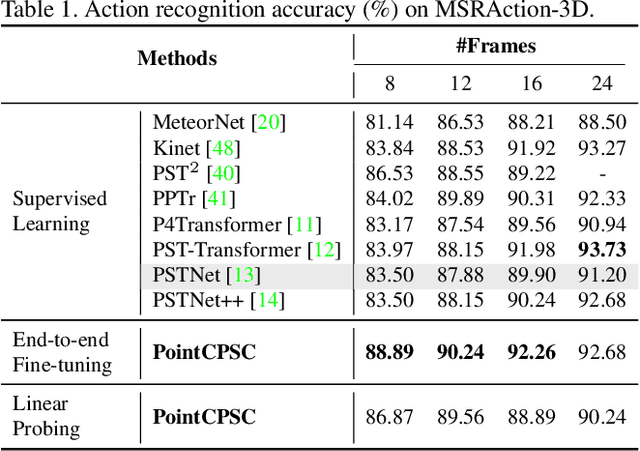
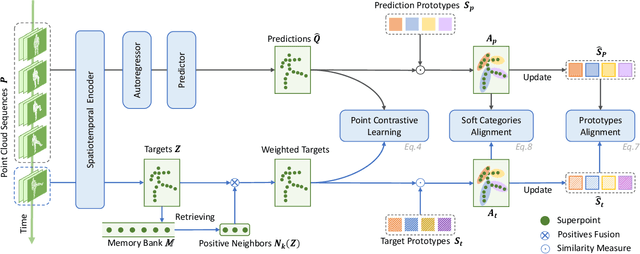
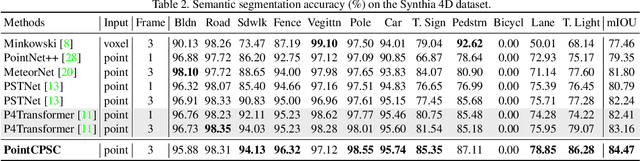
We propose a unified point cloud video self-supervised learning framework for object-centric and scene-centric data. Previous methods commonly conduct representation learning at the clip or frame level and cannot well capture fine-grained semantics. Instead of contrasting the representations of clips or frames, in this paper, we propose a unified self-supervised framework by conducting contrastive learning at the point level. Moreover, we introduce a new pretext task by achieving semantic alignment of superpoints, which further facilitates the representations to capture semantic cues at multiple scales. In addition, due to the high redundancy in the temporal dimension of dynamic point clouds, directly conducting contrastive learning at the point level usually leads to massive undesired negatives and insufficient modeling of positive representations. To remedy this, we propose a selection strategy to retain proper negatives and make use of high-similarity samples from other instances as positive supplements. Extensive experiments show that our method outperforms supervised counterparts on a wide range of downstream tasks and demonstrates the superior transferability of the learned representations.
Exploring the Physical World Adversarial Robustness of Vehicle Detection
Aug 07, 2023



Adversarial attacks can compromise the robustness of real-world detection models. However, evaluating these models under real-world conditions poses challenges due to resource-intensive experiments. Virtual simulations offer an alternative, but the absence of standardized benchmarks hampers progress. Addressing this, we propose an innovative instant-level data generation pipeline using the CARLA simulator. Through this pipeline, we establish the Discrete and Continuous Instant-level (DCI) dataset, enabling comprehensive experiments involving three detection models and three physical adversarial attacks. Our findings highlight diverse model performances under adversarial conditions. Yolo v6 demonstrates remarkable resilience, experiencing just a marginal 6.59% average drop in average precision (AP). In contrast, the ASA attack yields a substantial 14.51% average AP reduction, twice the effect of other algorithms. We also note that static scenes yield higher recognition AP values, and outcomes remain relatively consistent across varying weather conditions. Intriguingly, our study suggests that advancements in adversarial attack algorithms may be approaching its ``limitation''.In summary, our work underscores the significance of adversarial attacks in real-world contexts and introduces the DCI dataset as a versatile benchmark. Our findings provide valuable insights for enhancing the robustness of detection models and offer guidance for future research endeavors in the realm of adversarial attacks.
Contrastive Predictive Autoencoders for Dynamic Point Cloud Self-Supervised Learning
May 22, 2023We present a new self-supervised paradigm on point cloud sequence understanding. Inspired by the discriminative and generative self-supervised methods, we design two tasks, namely point cloud sequence based Contrastive Prediction and Reconstruction (CPR), to collaboratively learn more comprehensive spatiotemporal representations. Specifically, dense point cloud segments are first input into an encoder to extract embeddings. All but the last ones are then aggregated by a context-aware autoregressor to make predictions for the last target segment. Towards the goal of modeling multi-granularity structures, local and global contrastive learning are performed between predictions and targets. To further improve the generalization of representations, the predictions are also utilized to reconstruct raw point cloud sequences by a decoder, where point cloud colorization is employed to discriminate against different frames. By combining classic contrast and reconstruction paradigms, it makes the learned representations with both global discrimination and local perception. We conduct experiments on four point cloud sequence benchmarks, and report the results on action recognition and gesture recognition under multiple experimental settings. The performances are comparable with supervised methods and show powerful transferability.
A Survey of Knowledge Enhanced Pre-trained Models
Oct 01, 2021
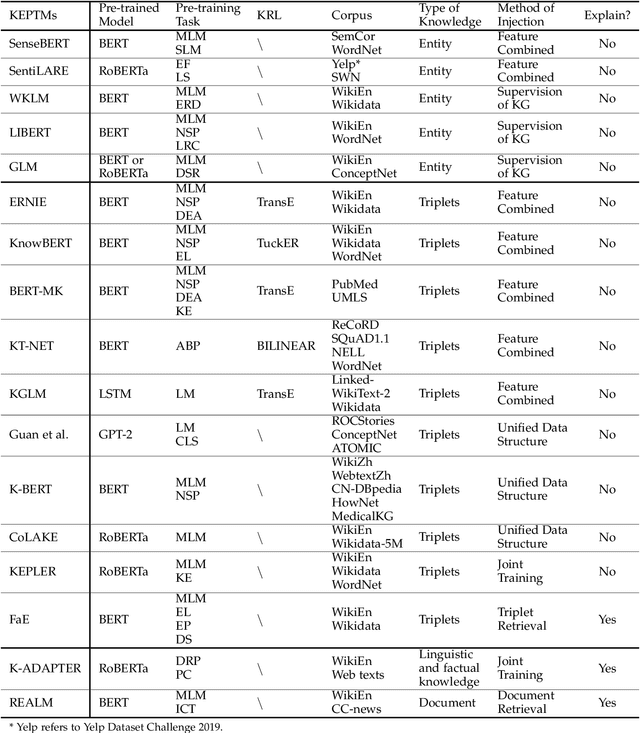

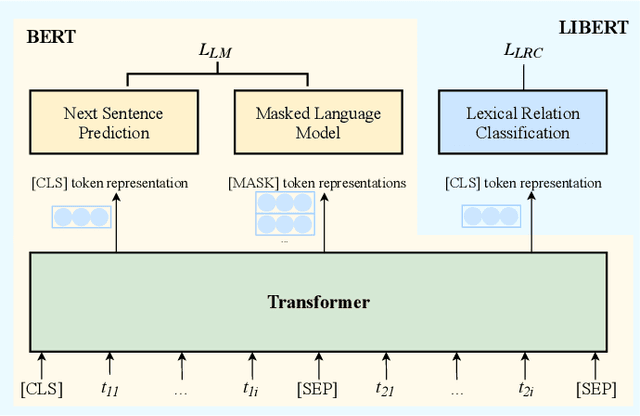
Pre-trained models learn contextualized word representations on large-scale text corpus through a self-supervised learning method, which has achieved promising performance after fine-tuning. These models, however, suffer from poor robustness and lack of interpretability. Pre-trained models with knowledge injection, which we call knowledge enhanced pre-trained models (KEPTMs), possess deep understanding and logical reasoning and introduce interpretability to some extent. In this survey, we provide a comprehensive overview of KEPTMs for natural language processing. We first introduce the progress of pre-trained models and knowledge representation learning. Then we systematically categorize existing KEPTMs from three different perspectives. Finally, we outline some potential directions of KEPTMs for future research.
NAS-TC: Neural Architecture Search on Temporal Convolutions for Complex Action Recognition
Mar 17, 2021
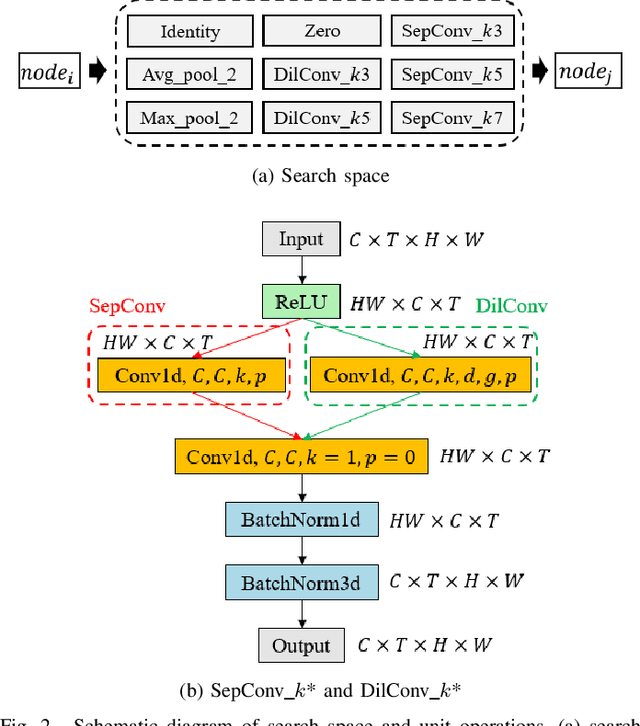
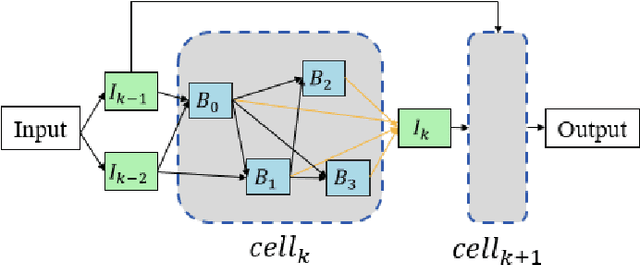
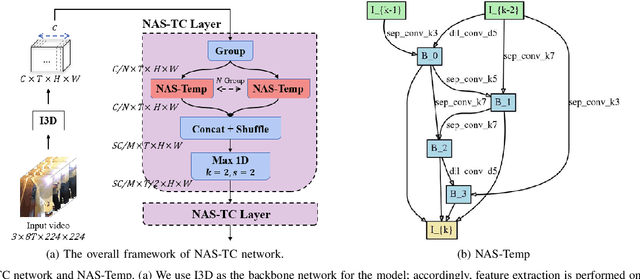
In the field of complex action recognition in videos, the quality of the designed model plays a crucial role in the final performance. However, artificially designed network structures often rely heavily on the researchers' knowledge and experience. Accordingly, because of the automated design of its network structure, Neural architecture search (NAS) has achieved great success in the image processing field and attracted substantial research attention in recent years. Although some NAS methods have reduced the number of GPU search days required to single digits in the image field, directly using 3D convolution to extend NAS to the video field is still likely to produce a surge in computing volume. To address this challenge, we propose a new processing framework called Neural Architecture Search- Temporal Convolutional (NAS-TC). Our proposed framework is divided into two phases. In the first phase, the classical CNN network is used as the backbone network to complete the computationally intensive feature extraction task. In the second stage, a simple stitching search to the cell is used to complete the relatively lightweight long-range temporal-dependent information extraction. This ensures our method will have more reasonable parameter assignments and can handle minute-level videos. Finally, we conduct sufficient experiments on multiple benchmark datasets and obtain competitive recognition accuracy.
A Comprehensive Evaluation Framework for Deep Model Robustness
Jan 24, 2021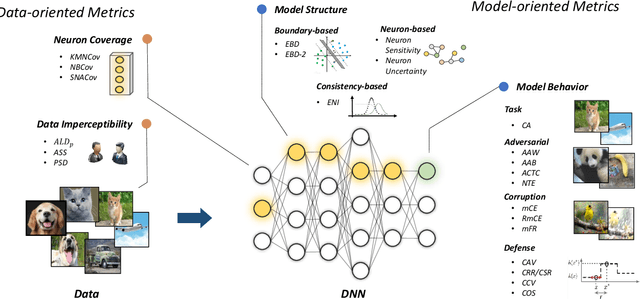
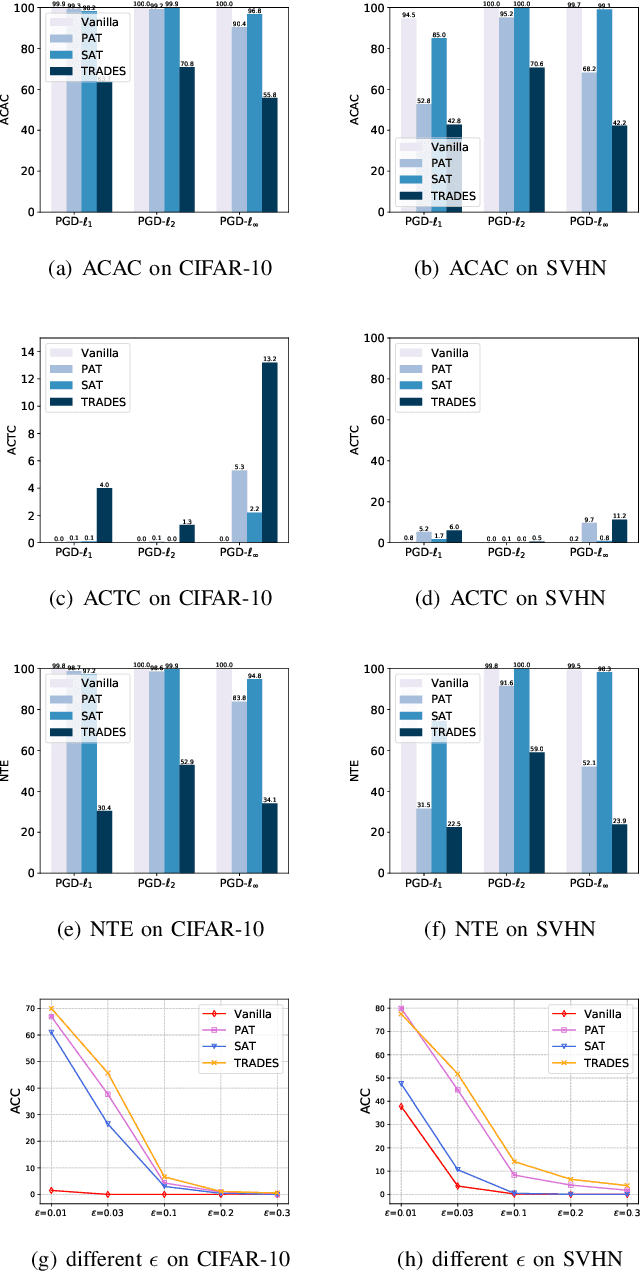
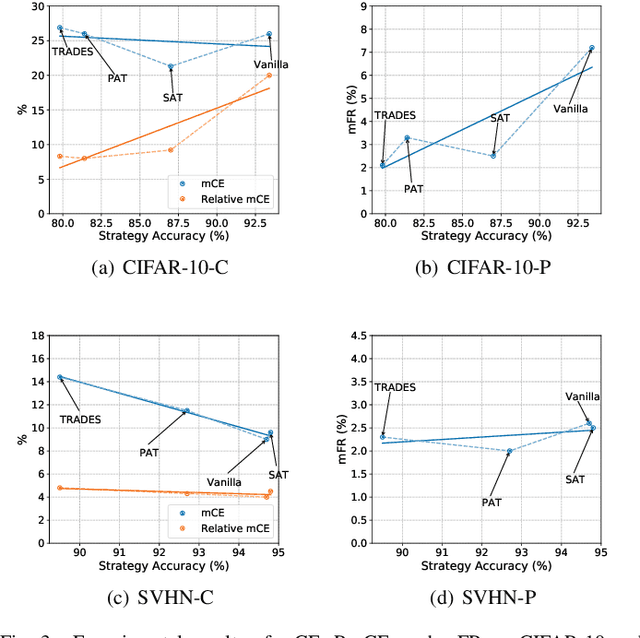
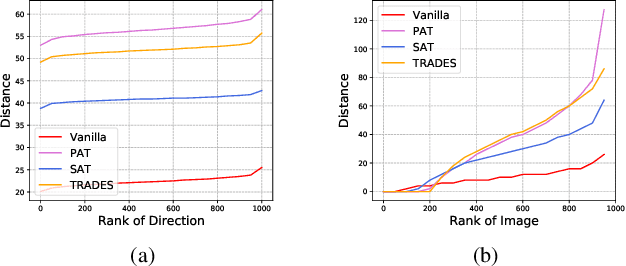
Deep neural networks (DNNs) have achieved remarkable performance across a wide area of applications. However, they are vulnerable to adversarial examples, which motivates the adversarial defense. By adopting simple evaluation metrics, most of the current defenses only conduct incomplete evaluations, which are far from providing comprehensive understandings of the limitations of these defenses. Thus, most proposed defenses are quickly shown to be attacked successfully, which result in the "arm race" phenomenon between attack and defense. To mitigate this problem, we establish a model robustness evaluation framework containing a comprehensive, rigorous, and coherent set of evaluation metrics, which could fully evaluate model robustness and provide deep insights into building robust models. With 23 evaluation metrics in total, our framework primarily focuses on the two key factors of adversarial learning (\ie, data and model). Through neuron coverage and data imperceptibility, we use data-oriented metrics to measure the integrity of test examples; by delving into model structure and behavior, we exploit model-oriented metrics to further evaluate robustness in the adversarial setting. To fully demonstrate the effectiveness of our framework, we conduct large-scale experiments on multiple datasets including CIFAR-10 and SVHN using different models and defenses with our open-source platform AISafety. Overall, our paper aims to provide a comprehensive evaluation framework which could demonstrate detailed inspections of the model robustness, and we hope that our paper can inspire further improvement to the model robustness.
Robust Facial Landmark Detection by Cross-order Cross-semantic Deep Network
Nov 16, 2020

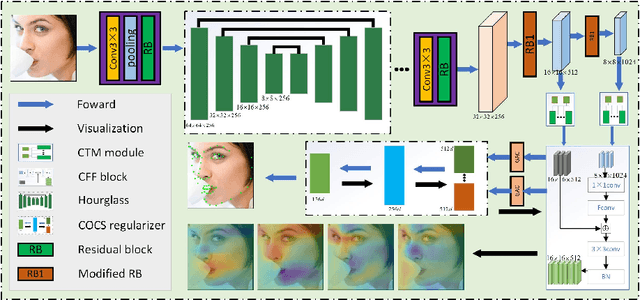

Recently, convolutional neural networks (CNNs)-based facial landmark detection methods have achieved great success. However, most of existing CNN-based facial landmark detection methods have not attempted to activate multiple correlated facial parts and learn different semantic features from them that they can not accurately model the relationships among the local details and can not fully explore more discriminative and fine semantic features, thus they suffer from partial occlusions and large pose variations. To address these problems, we propose a cross-order cross-semantic deep network (CCDN) to boost the semantic features learning for robust facial landmark detection. Specifically, a cross-order two-squeeze multi-excitation (CTM) module is proposed to introduce the cross-order channel correlations for more discriminative representations learning and multiple attention-specific part activation. Moreover, a novel cross-order cross-semantic (COCS) regularizer is designed to drive the network to learn cross-order cross-semantic features from different activation for facial landmark detection. It is interesting to show that by integrating the CTM module and COCS regularizer, the proposed CCDN can effectively activate and learn more fine and complementary cross-order cross-semantic features to improve the accuracy of facial landmark detection under extremely challenging scenarios. Experimental results on challenging benchmark datasets demonstrate the superiority of our CCDN over state-of-the-art facial landmark detection methods.
VIFB: A Visible and Infrared Image Fusion Benchmark
Feb 09, 2020



Visible and infrared image fusion is one of the most important areas in image processing due to its numerous applications. While much progress has been made in recent years with efforts on developing fusion algorithms, there is a lack of code library and benchmark which can gauge the state-of-the-art. In this paper, after briefly reviewing recent advances of visible and infrared image fusion, we present a visible and infrared image fusion benchmark (VIFB) which consists of 21 image pairs, a code library of 20 fusion algorithms and 13 evaluation metrics. We also carry out large scale experiments within the benchmark to understand the performance of these algorithms. By analyzing qualitative and quantitative results, we identify effective algorithms for robust image fusion and give some observations on the status and future prospects of this field. The benchmark, including dataset, code library, evaluation metrics, and results is available upon request.