 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMasked Spatio-Temporal Structure Prediction for Self-supervised Learning on Point Cloud Videos
Aug 18, 2023Recently, the community has made tremendous progress in developing effective methods for point cloud video understanding that learn from massive amounts of labeled data. However, annotating point cloud videos is usually notoriously expensive. Moreover, training via one or only a few traditional tasks (e.g., classification) may be insufficient to learn subtle details of the spatio-temporal structure existing in point cloud videos. In this paper, we propose a Masked Spatio-Temporal Structure Prediction (MaST-Pre) method to capture the structure of point cloud videos without human annotations. MaST-Pre is based on spatio-temporal point-tube masking and consists of two self-supervised learning tasks. First, by reconstructing masked point tubes, our method is able to capture the appearance information of point cloud videos. Second, to learn motion, we propose a temporal cardinality difference prediction task that estimates the change in the number of points within a point tube. In this way, MaST-Pre is forced to model the spatial and temporal structure in point cloud videos. Extensive experiments on MSRAction-3D, NTU-RGBD, NvGesture, and SHREC'17 demonstrate the effectiveness of the proposed method.
Point Contrastive Prediction with Semantic Clustering for Self-Supervised Learning on Point Cloud Videos
Aug 18, 2023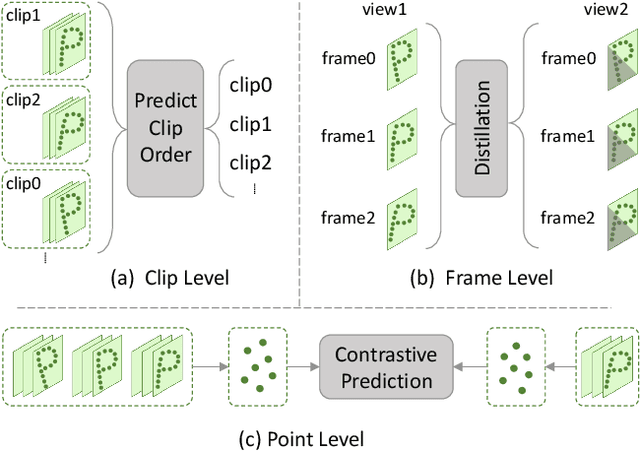
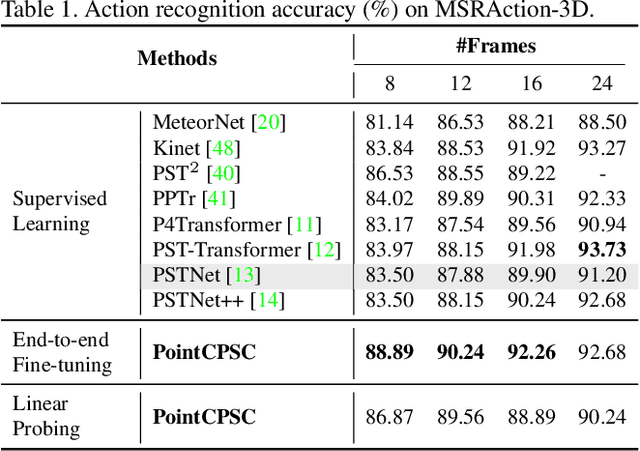
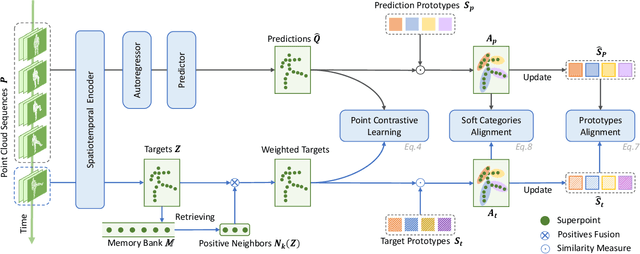
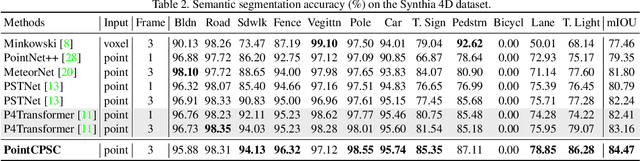
We propose a unified point cloud video self-supervised learning framework for object-centric and scene-centric data. Previous methods commonly conduct representation learning at the clip or frame level and cannot well capture fine-grained semantics. Instead of contrasting the representations of clips or frames, in this paper, we propose a unified self-supervised framework by conducting contrastive learning at the point level. Moreover, we introduce a new pretext task by achieving semantic alignment of superpoints, which further facilitates the representations to capture semantic cues at multiple scales. In addition, due to the high redundancy in the temporal dimension of dynamic point clouds, directly conducting contrastive learning at the point level usually leads to massive undesired negatives and insufficient modeling of positive representations. To remedy this, we propose a selection strategy to retain proper negatives and make use of high-similarity samples from other instances as positive supplements. Extensive experiments show that our method outperforms supervised counterparts on a wide range of downstream tasks and demonstrates the superior transferability of the learned representations.
Contrastive Predictive Autoencoders for Dynamic Point Cloud Self-Supervised Learning
May 22, 2023We present a new self-supervised paradigm on point cloud sequence understanding. Inspired by the discriminative and generative self-supervised methods, we design two tasks, namely point cloud sequence based Contrastive Prediction and Reconstruction (CPR), to collaboratively learn more comprehensive spatiotemporal representations. Specifically, dense point cloud segments are first input into an encoder to extract embeddings. All but the last ones are then aggregated by a context-aware autoregressor to make predictions for the last target segment. Towards the goal of modeling multi-granularity structures, local and global contrastive learning are performed between predictions and targets. To further improve the generalization of representations, the predictions are also utilized to reconstruct raw point cloud sequences by a decoder, where point cloud colorization is employed to discriminate against different frames. By combining classic contrast and reconstruction paradigms, it makes the learned representations with both global discrimination and local perception. We conduct experiments on four point cloud sequence benchmarks, and report the results on action recognition and gesture recognition under multiple experimental settings. The performances are comparable with supervised methods and show powerful transferability.
PointCMP: Contrastive Mask Prediction for Self-supervised Learning on Point Cloud Videos
May 06, 2023Self-supervised learning can extract representations of good quality from solely unlabeled data, which is appealing for point cloud videos due to their high labelling cost. In this paper, we propose a contrastive mask prediction (PointCMP) framework for self-supervised learning on point cloud videos. Specifically, our PointCMP employs a two-branch structure to achieve simultaneous learning of both local and global spatio-temporal information. On top of this two-branch structure, a mutual similarity based augmentation module is developed to synthesize hard samples at the feature level. By masking dominant tokens and erasing principal channels, we generate hard samples to facilitate learning representations with better discrimination and generalization performance. Extensive experiments show that our PointCMP achieves the state-of-the-art performance on benchmark datasets and outperforms existing full-supervised counterparts. Transfer learning results demonstrate the superiority of the learned representations across different datasets and tasks.