 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCodecSplat: Ultra-Compact Latent Coding for Feed-Forward 3D Gaussian Splatting
May 25, 2026While feed-forward 3D Gaussian splatting reconstructs renderable Gaussian primitives from sparse context views without per-scene optimization, existing pipelines do not provide a compact scene representation for storage or transmission. A natural solution is to apply existing 3DGS compression methods to the generated Gaussian primitives. However, this approach operates on the final irregular 3D representation and is decoupled from the internal feature-to-Gaussian generation process, which limits compression efficiency. To address this, we introduce CodecSplat, an ultra-compact latent coding framework for feed-forward 3D Gaussian splatting. CodecSplat first encodes an intermediate 2D Gaussian-generation feature into an entropy-coded scene bitstream. At the decoder, the latent feature is reconstructed and used to predict depth and Gaussian parameters, which are then mapped to 3D Gaussian primitives. Note that, by integrating compression into the feed-forward Gaussian generation pipeline, CodecSplat avoids inefficient compression over irregular 3D Gaussian primitives and allows the codec to exploit the structured intermediate feature representation. We instantiate CodecSplat on a feed-forward Gaussian splatting backbone with depth-guided multi-view feature refinement and a hierarchical learned feature codec. On DL3DV and RealEstate10K datasets, CodecSplat achieves 23.56-26.36 dB and 24.76-27.05 dB PSNR with only 20.00-107.77 KiB and 3.37-12.51 KiB per scene, respectively. This is roughly one order of magnitude smaller than compressing feed-forward generated Gaussian primitives, while preserving controllable rate-distortion behavior.
Towards UAV Detection in the Real World: A New Multispectral Dataset UAVNet-MS and a New Method
May 20, 2026The proliferation of unmanned aerial vehicles (UAVs) has created urgent demand for precise UAV monitoring. Existing RGB-based systems rely on spatial cues that degrade at small scales, particularly with high inter-type similarity, target-clutter ambiguity, and low contrast. Multispectral imaging (MSI) encodes material-aware spectral signatures, yet MSI-based fine-grained small-UAV detection remains underexplored due to lack of dedicated datasets. We introduce UAVNet-MS, the first multispectral dataset for fine-grained small-UAV detection, comprising 15,618 temporally synchronized RGB-MSI data cubes (1440x1080) with bounding box annotations. The dataset features challenging small objects (93.7% <= 32^2 pixels, average 18^2 pixels, ~0.02% image area) under low contrast. We propose MFDNet, a dual-stream baseline addressing array-induced parallax and spatial-spectral fusion. Extensive evaluation under RGB-only, MSI-only, and RGB+MSI protocols against 20 detectors shows MFDNet achieves +6.2% AP50 improvement over best RGB-only methods, demonstrating spectral cues provide complementary material evidence beyond spatial cues. This work provides foundational dataset, strong baseline, and benchmark for multispectral UAV monitoring research.
Design Your Ad: Personalized Advertising Image and Text Generation with Unified Autoregressive Models
May 12, 2026Generating realistic and user-preferred advertisements is a key challenge in e-commerce. Existing approaches utilize multiple independent models driven by click-through-rate (CTR) to controllably create attractive image or text advertisements. However, their pipelines lack cross-modal perception and rely on CTR that only reflects average preferences. Therefore, we explore jointly generating personalized image-text advertisements from historical click behaviors. We first design a Unified Advertisement Generative model (Uni-AdGen) that employs a single autoregressive framework to produce both advertising images and texts. By incorporating a foreground perception module and instruction tuning, Uni-AdGen enhances the realism of the generated content. To further personalize advertisements, we equip Uni-AdGen with a coarse-to-fine preference understanding module that effectively captures user interests from noisy multimodal historical behaviors to drive personalized generation. Additionally, we construct the first large-scale Personalized Advertising image-text dataset (PAd1M) and introduce a Product Background Similarity (PBS) metric to facilitate training and evaluation. Extensive experiments show that our method outperforms baselines in general and personalized advertisement generation. Our project is available at https://github.com/JD-GenX/Uni-AdGen.
Triple Spectral Fusion for Sensor-based Human Activity Recognition
May 04, 2026The field of sensor-based human activity recognition (HAR) mainly uses posture, motion and context data of Inertial Measurement Units (IMUs) to identify daily activities. Despite the advancements in learning-based methods, it is challenging to perform information fusion from the temporal perspective due to the complexities in fusing heterogeneous sensor data and establishing long-term context correlations. This paper proposes a novel triple spectral fusion framework tailored for HAR. First, we develop an adaptive complementary filtering technique for noise suppression and organize each IMU's sensors into posture and motion modality nodes. Given that IMU nodes form a dynamic heterogeneous graph, we then apply adaptive filtering within the graph Fourier domain to merge both homogeneous and heterogeneous node information. Furthermore, an adaptive wavelet frequency selection approach is implemented to suppress context redundancy and shorten the length of features. This approach enhances both timestamp-based graph aggregation and the correlation of long-term contexts. Our framework uses adaptive filtering in the Fourier, graph Fourier, and wavelet domains, enabling effective multi-sensor fusion and context correlation. Extensive experiments on ten benchmark datasets demonstrate the superior performance of our framework. Project page: https://github.com/crocodilegogogo/TSF-TPAMI2026.
SMFormer: Empowering Self-supervised Stereo Matching via Foundation Models and Data Augmentation
Apr 11, 2026Recent self-supervised stereo matching methods have made significant progress. They typically rely on the photometric consistency assumption, which presumes corresponding points across views share the same appearance. However, this assumption could be compromised by real-world disturbances, resulting in invalid supervisory signals and a significant accuracy gap compared to supervised methods. To address this issue, we propose SMFormer, a framework integrating more reliable self-supervision guided by the Vision Foundation Model (VFM) and data augmentation. We first incorporate the VFM with the Feature Pyramid Network (FPN), providing a discriminative and robust feature representation against disturbance in various scenarios. We then devise an effective data augmentation mechanism that ensures robustness to various transformations. The data augmentation mechanism explicitly enforces consistency between learned features and those influenced by illumination variations. Additionally, it regularizes the output consistency between disparity predictions of strong augmented samples and those generated from standard samples. Experiments on multiple mainstream benchmarks demonstrate that our SMFormer achieves state-of-the-art (SOTA) performance among self-supervised methods and even competes on par with supervised ones. Remarkably, in the challenging Booster benchmark, SMFormer even outperforms some SOTA supervised methods, such as CFNet.
OmniCamera: A Unified Framework for Multi-task Video Generation with Arbitrary Camera Control
Apr 07, 2026Video fundamentally intertwines two crucial axes: the dynamic content of a scene and the camera motion through which it is observed. However, existing generation models often entangle these factors, limiting independent control. In this work, we introduce OmniCamera, a unified framework designed to explicitly disentangle and command these two dimensions. This compositional approach enables flexible video generation by allowing arbitrary pairings of camera and content conditions, unlocking unprecedented creative control. To overcome the fundamental challenges of modality conflict and data scarcity inherent in such a system, we present two key innovations. First, we construct OmniCAM, a novel hybrid dataset combining curated real-world videos with synthetic data that provides diverse paired examples for robust multi-task learning. Second, we propose a Dual-level Curriculum Co-Training strategy that mitigates modality interference and synergistically learns from diverse data sources. This strategy operates on two levels: first, it progressively introduces control modalities by difficulties (condition-level), and second, trains for precise control on synthetic data before adapting to real data for photorealism (data-level). As a result, OmniCamera achieves state-of-the-art performance, enabling flexible control for complex camera movements while maintaining superior visual quality.
Referring-Aware Visuomotor Policy Learning for Closed-Loop Manipulation
Apr 07, 2026This paper addresses a fundamental problem of visuomotor policy learning for robotic manipulation: how to enhance robustness in out-of-distribution execution errors or dynamically re-routing trajectories, where the model relies solely on the original expert demonstrations for training. We introduce the Referring-Aware Visuomotor Policy (ReV), a closed-loop framework that can adapt to unforeseen circumstances by instantly incorporating sparse referring points provided by a human or a high-level reasoning planner. Specifically, ReV leverages the coupled diffusion heads to preserve standard task execution patterns while seamlessly integrating sparse referring via a trajectory-steering strategy. Upon receiving a specific referring point, the global diffusion head firstly generates a sequence of globally consistent yet temporally sparse action anchors, while identifies the precise temporal position for the referring point within this sequence. Subsequently, the local diffusion head adaptively interpolates adjacent anchors based on the current temporal position for specific tasks. This closed-loop process repeats at every execution step, enabling real-time trajectory replanning in response to dynamic changes in the scene. In practice, rather than relying on elaborate annotations, ReV is trained only by applying targeted perturbations to expert demonstrations. Without any additional data or fine-tuning scheme, ReV achieve higher success rates across challenging simulated and real-world tasks.
Towards Practical Lossless Neural Compression for LiDAR Point Clouds
Mar 26, 2026LiDAR point clouds are fundamental to various applications, yet the extreme sparsity of high-precision geometric details hinders efficient context modeling, thereby limiting the compression speed and performance of existing methods. To address this challenge, we propose a compact representation for efficient predictive lossless coding. Our framework comprises two lightweight modules. First, the Geometry Re-Densification Module iteratively densifies encoded sparse geometry, extracts features at a dense scale, and then sparsifies the features for predictive coding. This module avoids costly computation on highly sparse details while maintaining a lightweight prediction head. Second, the Cross-scale Feature Propagation Module leverages occupancy cues from multiple resolution levels to guide hierarchical feature propagation, enabling information sharing across scales and reducing redundant feature extraction. Additionally, we introduce an integer-only inference pipeline to enable bit-exact cross-platform consistency, which avoids the entropy-coding collapse observed in existing neural compression methods and further accelerates coding. Experiments demonstrate competitive compression performance at real-time speed. Code will be released upon acceptance. Code is available at https://github.com/pengpeng-yu/FastPCC.
Edge-Centric Relational Reasoning for 3D Scene Graph Prediction
Nov 19, 2025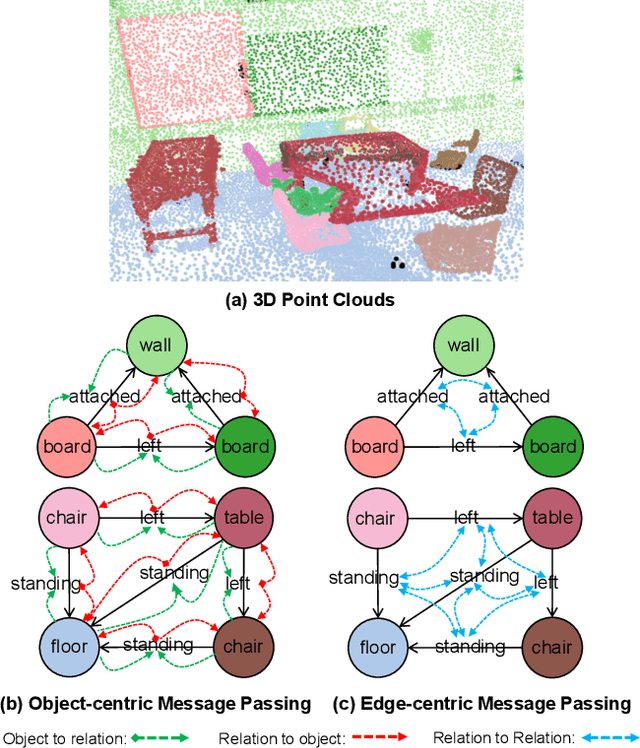
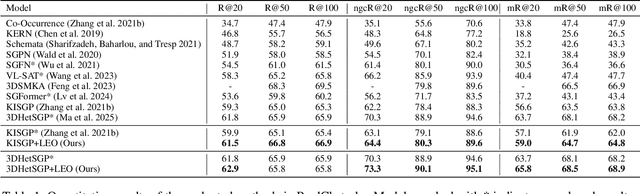
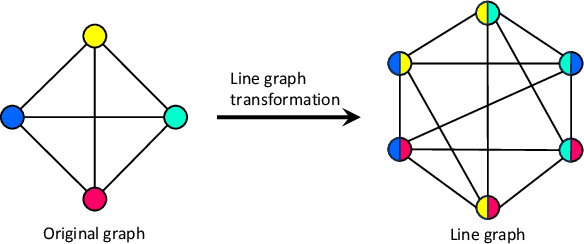
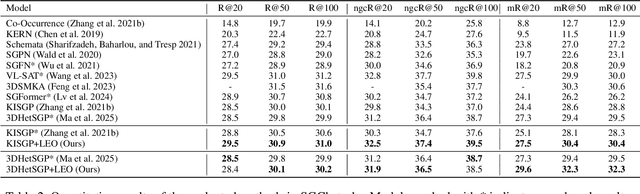
3D scene graph prediction aims to abstract complex 3D environments into structured graphs consisting of objects and their pairwise relationships. Existing approaches typically adopt object-centric graph neural networks, where relation edge features are iteratively updated by aggregating messages from connected object nodes. However, this design inherently restricts relation representations to pairwise object context, making it difficult to capture high-order relational dependencies that are essential for accurate relation prediction. To address this limitation, we propose a Link-guided Edge-centric relational reasoning framework with Object-aware fusion, namely LEO, which enables progressive reasoning from relation-level context to object-level understanding. Specifically, LEO first predicts potential links between object pairs to suppress irrelevant edges, and then transforms the original scene graph into a line graph where each relation is treated as a node. A line graph neural network is applied to perform edge-centric relational reasoning to capture inter-relation context. The enriched relation features are subsequently integrated into the original object-centric graph to enhance object-level reasoning and improve relation prediction. Our framework is model-agnostic and can be integrated with any existing object-centric method. Experiments on the 3DSSG dataset with two competitive baselines show consistent improvements, highlighting the effectiveness of our edge-to-object reasoning paradigm.
CDP: Towards Robust Autoregressive Visuomotor Policy Learning via Causal Diffusion
Jun 17, 2025Diffusion Policy (DP) enables robots to learn complex behaviors by imitating expert demonstrations through action diffusion. However, in practical applications, hardware limitations often degrade data quality, while real-time constraints restrict model inference to instantaneous state and scene observations. These limitations seriously reduce the efficacy of learning from expert demonstrations, resulting in failures in object localization, grasp planning, and long-horizon task execution. To address these challenges, we propose Causal Diffusion Policy (CDP), a novel transformer-based diffusion model that enhances action prediction by conditioning on historical action sequences, thereby enabling more coherent and context-aware visuomotor policy learning. To further mitigate the computational cost associated with autoregressive inference, a caching mechanism is also introduced to store attention key-value pairs from previous timesteps, substantially reducing redundant computations during execution. Extensive experiments in both simulated and real-world environments, spanning diverse 2D and 3D manipulation tasks, demonstrate that CDP uniquely leverages historical action sequences to achieve significantly higher accuracy than existing methods. Moreover, even when faced with degraded input observation quality, CDP maintains remarkable precision by reasoning through temporal continuity, which highlights its practical robustness for robotic control under realistic, imperfect conditions.