 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDropoutGS: Dropping Out Gaussians for Better Sparse-view Rendering
Apr 13, 2025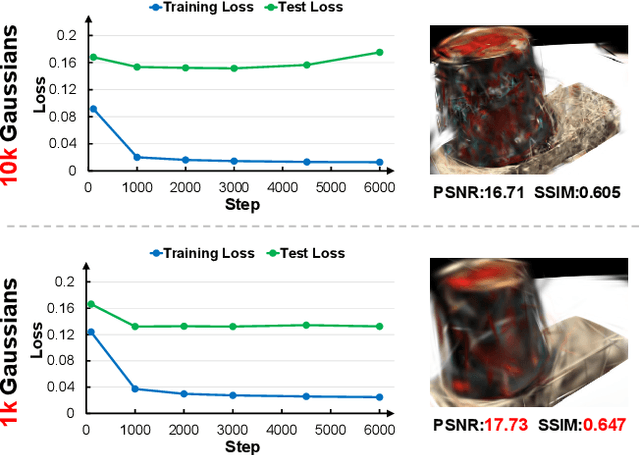
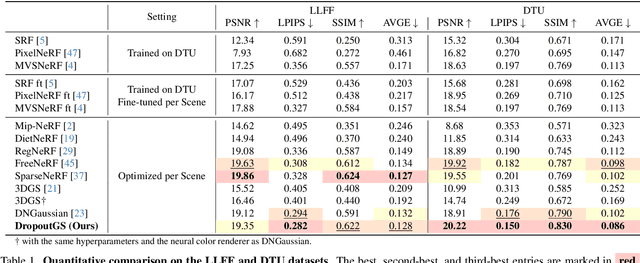

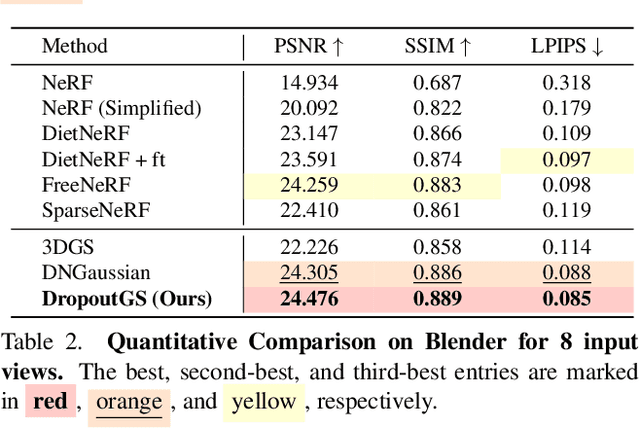
Although 3D Gaussian Splatting (3DGS) has demonstrated promising results in novel view synthesis, its performance degrades dramatically with sparse inputs and generates undesirable artifacts. As the number of training views decreases, the novel view synthesis task degrades to a highly under-determined problem such that existing methods suffer from the notorious overfitting issue. Interestingly, we observe that models with fewer Gaussian primitives exhibit less overfitting under sparse inputs. Inspired by this observation, we propose a Random Dropout Regularization (RDR) to exploit the advantages of low-complexity models to alleviate overfitting. In addition, to remedy the lack of high-frequency details for these models, an Edge-guided Splitting Strategy (ESS) is developed. With these two techniques, our method (termed DropoutGS) provides a simple yet effective plug-in approach to improve the generalization performance of existing 3DGS methods. Extensive experiments show that our DropoutGS produces state-of-the-art performance under sparse views on benchmark datasets including Blender, LLFF, and DTU. The project page is at: https://xuyx55.github.io/DropoutGS/.
Layout2Scene: 3D Semantic Layout Guided Scene Generation via Geometry and Appearance Diffusion Priors
Jan 05, 20253D scene generation conditioned on text prompts has significantly progressed due to the development of 2D diffusion generation models. However, the textual description of 3D scenes is inherently inaccurate and lacks fine-grained control during training, leading to implausible scene generation. As an intuitive and feasible solution, the 3D layout allows for precise specification of object locations within the scene. To this end, we present a text-to-scene generation method (namely, Layout2Scene) using additional semantic layout as the prompt to inject precise control of 3D object positions. Specifically, we first introduce a scene hybrid representation to decouple objects and backgrounds, which is initialized via a pre-trained text-to-3D model. Then, we propose a two-stage scheme to optimize the geometry and appearance of the initialized scene separately. To fully leverage 2D diffusion priors in geometry and appearance generation, we introduce a semantic-guided geometry diffusion model and a semantic-geometry guided diffusion model which are finetuned on a scene dataset. Extensive experiments demonstrate that our method can generate more plausible and realistic scenes as compared to state-of-the-art approaches. Furthermore, the generated scene allows for flexible yet precise editing, thereby facilitating multiple downstream applications.
Point Cloud Unsupervised Pre-training via 3D Gaussian Splatting
Nov 27, 2024



Pre-training on large-scale unlabeled datasets contribute to the model achieving powerful performance on 3D vision tasks, especially when annotations are limited. However, existing rendering-based self-supervised frameworks are computationally demanding and memory-intensive during pre-training due to the inherent nature of volume rendering. In this paper, we propose an efficient framework named GS$^3$ to learn point cloud representation, which seamlessly integrates fast 3D Gaussian Splatting into the rendering-based framework. The core idea behind our framework is to pre-train the point cloud encoder by comparing rendered RGB images with real RGB images, as only Gaussian points enriched with learned rich geometric and appearance information can produce high-quality renderings. Specifically, we back-project the input RGB-D images into 3D space and use a point cloud encoder to extract point-wise features. Then, we predict 3D Gaussian points of the scene from the learned point cloud features and uses a tile-based rasterizer for image rendering. Finally, the pre-trained point cloud encoder can be fine-tuned to adapt to various downstream 3D tasks, including high-level perception tasks such as 3D segmentation and detection, as well as low-level tasks such as 3D scene reconstruction. Extensive experiments on downstream tasks demonstrate the strong transferability of the pre-trained point cloud encoder and the effectiveness of our self-supervised learning framework. In addition, our GS$^3$ framework is highly efficient, achieving approximately 9$\times$ pre-training speedup and less than 0.25$\times$ memory cost compared to the previous rendering-based framework Ponder.
Sketch2NeRF: Multi-view Sketch-guided Text-to-3D Generation
Jan 27, 2024Recently, text-to-3D approaches have achieved high-fidelity 3D content generation using text description. However, the generated objects are stochastic and lack fine-grained control. Sketches provide a cheap approach to introduce such fine-grained control. Nevertheless, it is challenging to achieve flexible control from these sketches due to their abstraction and ambiguity. In this paper, we present a multi-view sketch-guided text-to-3D generation framework (namely, Sketch2NeRF) to add sketch control to 3D generation. Specifically, our method leverages pretrained 2D diffusion models (e.g., Stable Diffusion and ControlNet) to supervise the optimization of a 3D scene represented by a neural radiance field (NeRF). We propose a novel synchronized generation and reconstruction method to effectively optimize the NeRF. In the experiments, we collected two kinds of multi-view sketch datasets to evaluate the proposed method. We demonstrate that our method can synthesize 3D consistent contents with fine-grained sketch control while being high-fidelity to text prompts. Extensive results show that our method achieves state-of-the-art performance in terms of sketch similarity and text alignment.
Bridging the Domain Gap in Satellite Pose Estimation: a Self-Training Approach based on Geometrical Constraints
Dec 23, 2022Recently, unsupervised domain adaptation in satellite pose estimation has gained increasing attention, aiming at alleviating the annotation cost for training deep models. To this end, we propose a self-training framework based on the domain-agnostic geometrical constraints. Specifically, we train a neural network to predict the 2D keypoints of a satellite and then use PnP to estimate the pose. The poses of target samples are regarded as latent variables to formulate the task as a minimization problem. Furthermore, we leverage fine-grained segmentation to tackle the information loss issue caused by abstracting the satellite as sparse keypoints. Finally, we iteratively solve the minimization problem in two steps: pseudo-label generation and network training. Experimental results show that our method adapts well to the target domain. Moreover, our method won the 1st place on the sunlamp task of the second international Satellite Pose Estimation Competition.