 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSketch2NeRF: Multi-view Sketch-guided Text-to-3D Generation
Jan 27, 2024Recently, text-to-3D approaches have achieved high-fidelity 3D content generation using text description. However, the generated objects are stochastic and lack fine-grained control. Sketches provide a cheap approach to introduce such fine-grained control. Nevertheless, it is challenging to achieve flexible control from these sketches due to their abstraction and ambiguity. In this paper, we present a multi-view sketch-guided text-to-3D generation framework (namely, Sketch2NeRF) to add sketch control to 3D generation. Specifically, our method leverages pretrained 2D diffusion models (e.g., Stable Diffusion and ControlNet) to supervise the optimization of a 3D scene represented by a neural radiance field (NeRF). We propose a novel synchronized generation and reconstruction method to effectively optimize the NeRF. In the experiments, we collected two kinds of multi-view sketch datasets to evaluate the proposed method. We demonstrate that our method can synthesize 3D consistent contents with fine-grained sketch control while being high-fidelity to text prompts. Extensive results show that our method achieves state-of-the-art performance in terms of sketch similarity and text alignment.
${S}^{2}$Net: Accurate Panorama Depth Estimation on Spherical Surface
Jan 14, 2023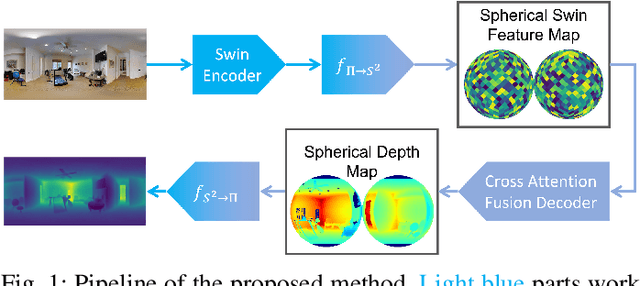

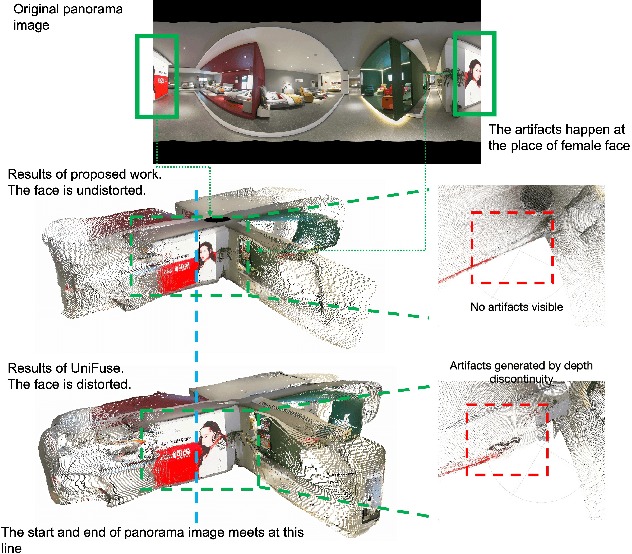
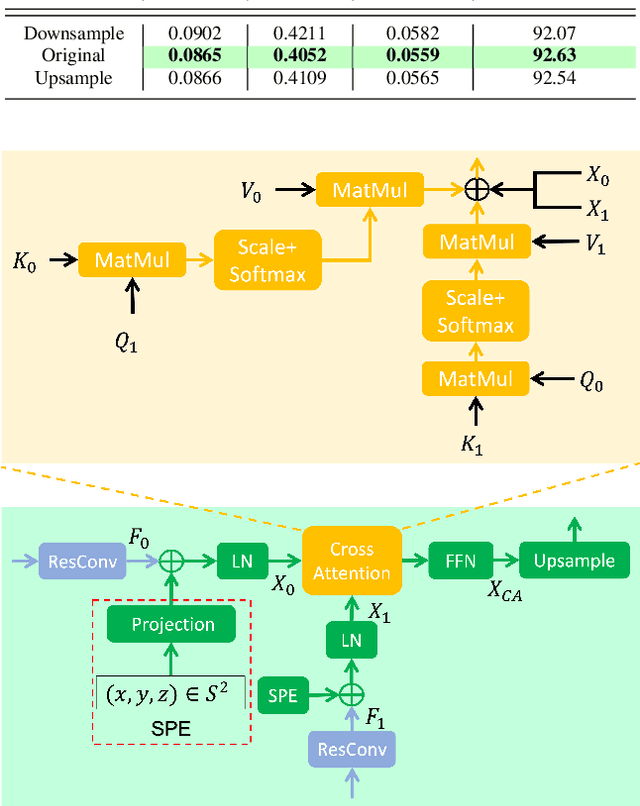
Monocular depth estimation is an ambiguous problem, thus global structural cues play an important role in current data-driven single-view depth estimation methods. Panorama images capture the complete spatial information of their surroundings utilizing the equirectangular projection which introduces large distortion. This requires the depth estimation method to be able to handle the distortion and extract global context information from the image. In this paper, we propose an end-to-end deep network for monocular panorama depth estimation on a unit spherical surface. Specifically, we project the feature maps extracted from equirectangular images onto unit spherical surface sampled by uniformly distributed grids, where the decoder network can aggregate the information from the distortion-reduced feature maps. Meanwhile, we propose a global cross-attention-based fusion module to fuse the feature maps from skip connection and enhance the ability to obtain global context. Experiments are conducted on five panorama depth estimation datasets, and the results demonstrate that the proposed method substantially outperforms previous state-of-the-art methods. All related codes will be open-sourced in the upcoming days.
UniFuse: Unidirectional Fusion for 360$^{\circ}$ Panorama Depth Estimation
Feb 06, 2021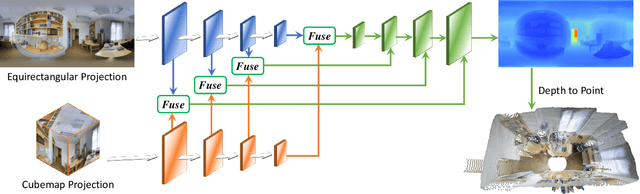
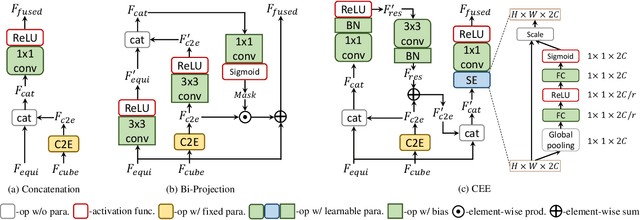
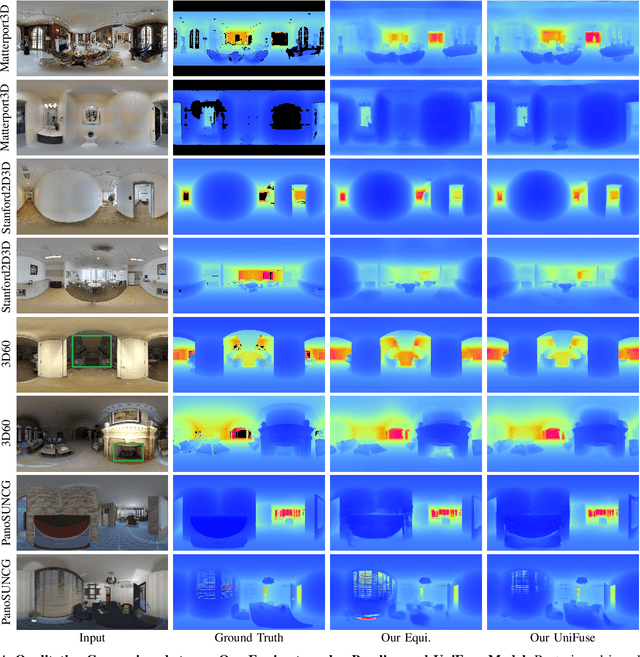
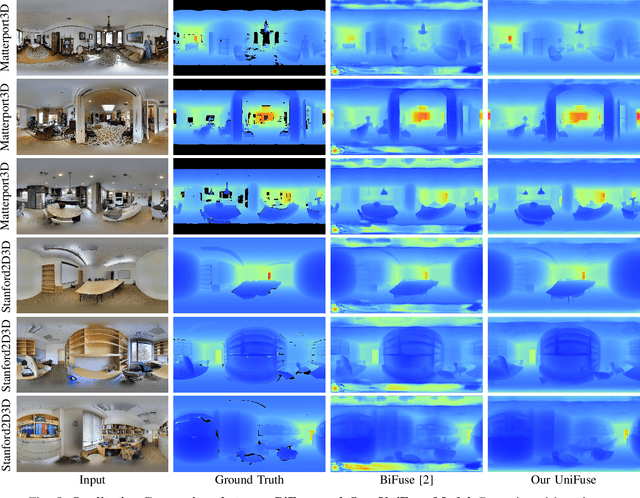
Learning depth from spherical panoramas is becoming a popular research topic because a panorama has a full field-of-view of the environment and provides a relatively complete description of a scene. However, applying well-studied CNNs for perspective images to the standard representation of spherical panoramas, i.e., the equirectangular projection, is suboptimal, as it becomes distorted towards the poles. Another representation is the cubemap projection, which is distortion-free but discontinued on edges and limited in the field-of-view. This paper introduces a new framework to fuse features from the two projections, unidirectionally feeding the cubemap features to the equirectangular features only at the decoding stage. Unlike the recent bidirectional fusion approach operating at both the encoding and decoding stages, our fusion scheme is much more efficient. Besides, we also designed a more effective fusion module for our fusion scheme. Experiments verify the effectiveness of our proposed fusion strategy and module, and our model achieves state-of-the-art performance on four popular datasets. Additional experiments show that our model also has the advantages of model complexity and generalization capability.