 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDepth Anything in $360^\circ$: Towards Scale Invariance in the Wild
Dec 28, 2025Panoramic depth estimation provides a comprehensive solution for capturing complete $360^\circ$ environmental structural information, offering significant benefits for robotics and AR/VR applications. However, while extensively studied in indoor settings, its zero-shot generalization to open-world domains lags far behind perspective images, which benefit from abundant training data. This disparity makes transferring capabilities from the perspective domain an attractive solution. To bridge this gap, we present Depth Anything in $360^\circ$ (DA360), a panoramic-adapted version of Depth Anything V2. Our key innovation involves learning a shift parameter from the ViT backbone, transforming the model's scale- and shift-invariant output into a scale-invariant estimate that directly yields well-formed 3D point clouds. This is complemented by integrating circular padding into the DPT decoder to eliminate seam artifacts, ensuring spatially coherent depth maps that respect spherical continuity. Evaluated on standard indoor benchmarks and our newly curated outdoor dataset, Metropolis, DA360 shows substantial gains over its base model, achieving over 50\% and 10\% relative depth error reduction on indoor and outdoor benchmarks, respectively. Furthermore, DA360 significantly outperforms robust panoramic depth estimation methods, achieving about 30\% relative error improvement compared to PanDA across all three test datasets and establishing new state-of-the-art performance for zero-shot panoramic depth estimation.
Self-Supervised Enhancement for Depth from a Lightweight ToF Sensor with Monocular Images
Jun 16, 2025



Depth map enhancement using paired high-resolution RGB images offers a cost-effective solution for improving low-resolution depth data from lightweight ToF sensors. Nevertheless, naively adopting a depth estimation pipeline to fuse the two modalities requires groundtruth depth maps for supervision. To address this, we propose a self-supervised learning framework, SelfToF, which generates detailed and scale-aware depth maps. Starting from an image-based self-supervised depth estimation pipeline, we add low-resolution depth as inputs, design a new depth consistency loss, propose a scale-recovery module, and finally obtain a large performance boost. Furthermore, since the ToF signal sparsity varies in real-world applications, we upgrade SelfToF to SelfToF* with submanifold convolution and guided feature fusion. Consequently, SelfToF* maintain robust performance across varying sparsity levels in ToF data. Overall, our proposed method is both efficient and effective, as verified by extensive experiments on the NYU and ScanNet datasets. The code will be made public.
The Fourth Monocular Depth Estimation Challenge
Apr 24, 2025


This paper presents the results of the fourth edition of the Monocular Depth Estimation Challenge (MDEC), which focuses on zero-shot generalization to the SYNS-Patches benchmark, a dataset featuring challenging environments in both natural and indoor settings. In this edition, we revised the evaluation protocol to use least-squares alignment with two degrees of freedom to support disparity and affine-invariant predictions. We also revised the baselines and included popular off-the-shelf methods: Depth Anything v2 and Marigold. The challenge received a total of 24 submissions that outperformed the baselines on the test set; 10 of these included a report describing their approach, with most leading methods relying on affine-invariant predictions. The challenge winners improved the 3D F-Score over the previous edition's best result, raising it from 22.58% to 23.05%.
DEFOM-Stereo: Depth Foundation Model Based Stereo Matching
Jan 16, 2025



Stereo matching is a key technique for metric depth estimation in computer vision and robotics. Real-world challenges like occlusion and non-texture hinder accurate disparity estimation from binocular matching cues. Recently, monocular relative depth estimation has shown remarkable generalization using vision foundation models. Thus, to facilitate robust stereo matching with monocular depth cues, we incorporate a robust monocular relative depth model into the recurrent stereo-matching framework, building a new framework for depth foundation model-based stereo-matching, DEFOM-Stereo. In the feature extraction stage, we construct the combined context and matching feature encoder by integrating features from conventional CNNs and DEFOM. In the update stage, we use the depth predicted by DEFOM to initialize the recurrent disparity and introduce a scale update module to refine the disparity at the correct scale. DEFOM-Stereo is verified to have comparable performance on the Scene Flow dataset with state-of-the-art (SOTA) methods and notably shows much stronger zero-shot generalization. Moreover, DEFOM-Stereo achieves SOTA performance on the KITTI 2012, KITTI 2015, Middlebury, and ETH3D benchmarks, ranking 1st on many metrics. In the joint evaluation under the robust vision challenge, our model simultaneously outperforms previous models on the individual benchmarks. Both results demonstrate the outstanding capabilities of the proposed model.
CFPNet: Improving Lightweight ToF Depth Completion via Cross-zone Feature Propagation
Nov 07, 2024


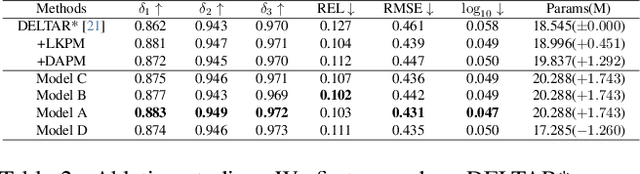
Depth completion using lightweight time-of-flight (ToF) depth sensors is attractive due to their low cost. However, lightweight ToF sensors usually have a limited field of view (FOV) compared with cameras. Thus, only pixels in the zone area of the image can be associated with depth signals. Previous methods fail to propagate depth features from the zone area to the outside-zone area effectively, thus suffering from degraded depth completion performance outside the zone. To this end, this paper proposes the CFPNet to achieve cross-zone feature propagation from the zone area to the outside-zone area with two novel modules. The first is a direct-attention-based propagation module (DAPM), which enforces direct cross-zone feature acquisition. The second is a large-kernel-based propagation module (LKPM), which realizes cross-zone feature propagation by utilizing convolution layers with kernel sizes up to 31. CFPNet achieves state-of-the-art (SOTA) depth completion performance by combining these two modules properly, as verified by extensive experimental results on the ZJU-L5 dataset. The code will be made public.
Towards Cross-View-Consistent Self-Supervised Surround Depth Estimation
Jul 04, 2024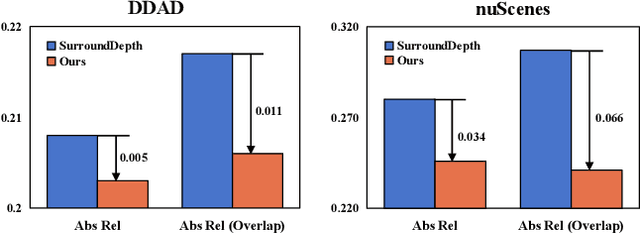
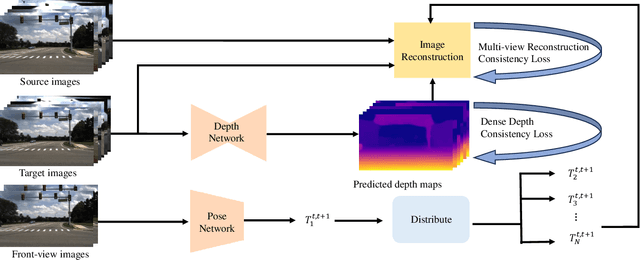
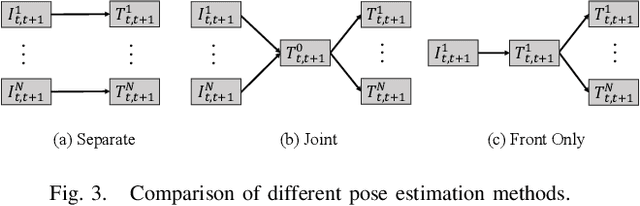

Depth estimation is a cornerstone for autonomous driving, yet acquiring per-pixel depth ground truth for supervised learning is challenging. Self-Supervised Surround Depth Estimation (SSSDE) from consecutive images offers an economical alternative. While previous SSSDE methods have proposed different mechanisms to fuse information across images, few of them explicitly consider the cross-view constraints, leading to inferior performance, particularly in overlapping regions. This paper proposes an efficient and consistent pose estimation design and two loss functions to enhance cross-view consistency for SSSDE. For pose estimation, we propose to use only front-view images to reduce training memory and sustain pose estimation consistency. The first loss function is the dense depth consistency loss, which penalizes the difference between predicted depths in overlapping regions. The second one is the multi-view reconstruction consistency loss, which aims to maintain consistency between reconstruction from spatial and spatial-temporal contexts. Additionally, we introduce a novel flipping augmentation to improve the performance further. Our techniques enable a simple neural model to achieve state-of-the-art performance on the DDAD and nuScenes datasets. Last but not least, our proposed techniques can be easily applied to other methods. The code will be made public.
RomniStereo: Recurrent Omnidirectional Stereo Matching
Jan 26, 2024



Omnidirectional stereo matching (OSM) is an essential and reliable means for $360^{\circ}$ depth sensing. However, following earlier works on conventional stereo matching, prior state-of-the-art (SOTA) methods rely on a 3D encoder-decoder block to regularize the cost volume, causing the whole system complicated and sub-optimal results. Recently, the Recurrent All-pairs Field Transforms (RAFT) based approach employs the recurrent update in 2D and has efficiently improved image-matching tasks, ie, optical flow, and stereo matching. To bridge the gap between OSM and RAFT, we mainly propose an opposite adaptive weighting scheme to seamlessly transform the outputs of spherical sweeping of OSM into the required inputs for the recurrent update, thus creating a recurrent omnidirectional stereo matching (RomniStereo) algorithm. Furthermore, we introduce two techniques, ie, grid embedding and adaptive context feature generation, which also contribute to RomniStereo's performance. Our best model improves the average MAE metric by 40.7\% over the previous SOTA baseline across five datasets. When visualizing the results, our models demonstrate clear advantages on both synthetic and realistic examples. The code is available at \url{https://github.com/HalleyJiang/RomniStereo}.
An Improved RaftStereo Trained with A Mixed Dataset for the Robust Vision Challenge 2022
Oct 23, 2022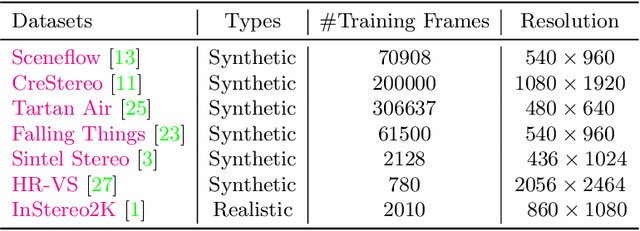
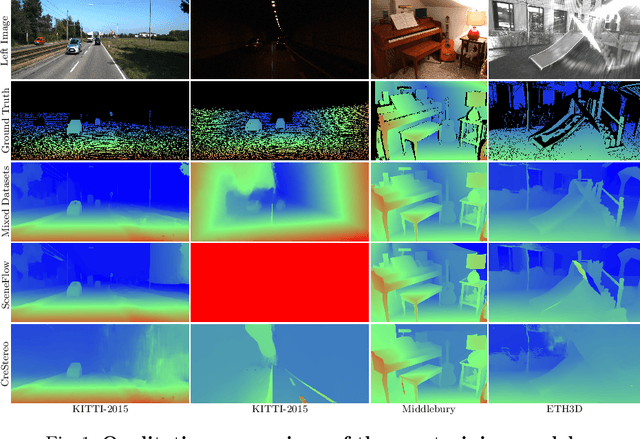


Stereo-matching is a fundamental problem in computer vision. Despite recent progress by deep learning, improving the robustness is ineluctable when deploying stereo-matching models to real-world applications. Different from the common practices, i.e., developing an elaborate model to achieve robustness, we argue that collecting multiple available datasets for training is a cheaper way to increase generalization ability. Specifically, this report presents an improved RaftStereo trained with a mixed dataset of seven public datasets for the robust vision challenge (denoted as iRaftStereo_RVC). When evaluated on the training sets of Middlebury, KITTI-2015, and ETH3D, the model outperforms its counterparts trained with only one dataset, such as the popular Sceneflow. After fine-tuning the pre-trained model on the three datasets of the challenge, it ranks at 2nd place on the stereo leaderboard, demonstrating the benefits of mixed dataset pre-training.
Data-free Dense Depth Distillation
Aug 26, 2022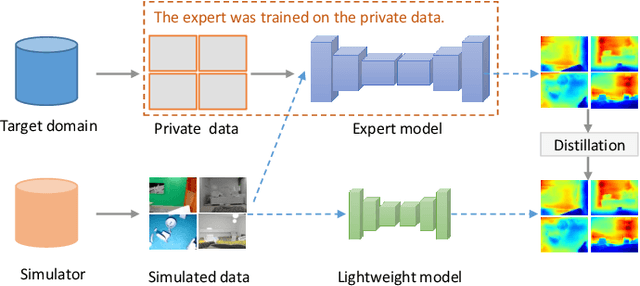
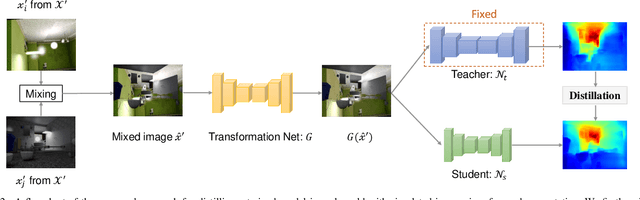

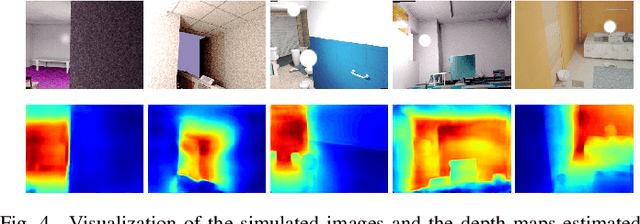
We study data-free knowledge distillation (KD) for monocular depth estimation (MDE), which learns a lightweight network for real-world depth perception by compressing from a trained expert model under the teacher-student framework while lacking training data in the target domain. Owing to the essential difference between dense regression and image recognition, previous methods of data-free KD are not applicable to MDE. To strengthen the applicability in the real world, in this paper, we seek to apply KD with out-of-distribution simulated images. The major challenges are i) lacking prior information about object distribution of the original training data; ii) the domain shift between the real world and the simulation. To cope with the first difficulty, we apply object-wise image mixing to generate new training samples for maximally covering distributed patterns of objects in the target domain. To tackle the second difficulty, we propose to utilize a transformation network that efficiently learns to fit the simulated data to the feature distribution of the teacher model. We evaluate the proposed approach for various depth estimation models and two different datasets. As a result, our method outperforms the baseline KD by a good margin and even achieves slightly better performance with as few as $1/6$ images, demonstrating a clear superiority.
PLNet: Plane and Line Priors for Unsupervised Indoor Depth Estimation
Oct 12, 2021
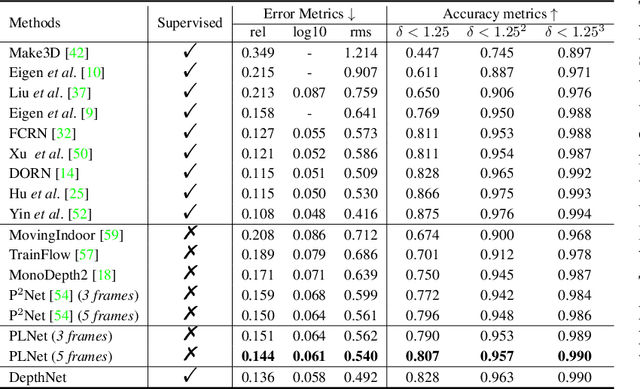
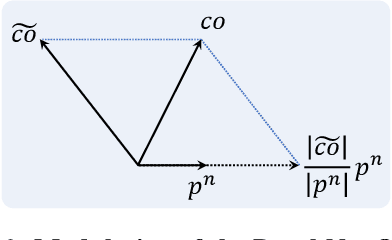

Unsupervised learning of depth from indoor monocular videos is challenging as the artificial environment contains many textureless regions. Fortunately, the indoor scenes are full of specific structures, such as planes and lines, which should help guide unsupervised depth learning. This paper proposes PLNet that leverages the plane and line priors to enhance the depth estimation. We first represent the scene geometry using local planar coefficients and impose the smoothness constraint on the representation. Moreover, we enforce the planar and linear consistency by randomly selecting some sets of points that are probably coplanar or collinear to construct simple and effective consistency losses. To verify the proposed method's effectiveness, we further propose to evaluate the flatness and straightness of the predicted point cloud on the reliable planar and linear regions. The regularity of these regions indicates quality indoor reconstruction. Experiments on NYU Depth V2 and ScanNet show that PLNet outperforms existing methods. The code is available at \url{https://github.com/HalleyJiang/PLNet}.