 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards a Generalizable Bimanual Foundation Policy via Flow-based Video Prediction
May 30, 2025Learning a generalizable bimanual manipulation policy is extremely challenging for embodied agents due to the large action space and the need for coordinated arm movements. Existing approaches rely on Vision-Language-Action (VLA) models to acquire bimanual policies. However, transferring knowledge from single-arm datasets or pre-trained VLA models often fails to generalize effectively, primarily due to the scarcity of bimanual data and the fundamental differences between single-arm and bimanual manipulation. In this paper, we propose a novel bimanual foundation policy by fine-tuning the leading text-to-video models to predict robot trajectories and training a lightweight diffusion policy for action generation. Given the lack of embodied knowledge in text-to-video models, we introduce a two-stage paradigm that fine-tunes independent text-to-flow and flow-to-video models derived from a pre-trained text-to-video model. Specifically, optical flow serves as an intermediate variable, providing a concise representation of subtle movements between images. The text-to-flow model predicts optical flow to concretize the intent of language instructions, and the flow-to-video model leverages this flow for fine-grained video prediction. Our method mitigates the ambiguity of language in single-stage text-to-video prediction and significantly reduces the robot-data requirement by avoiding direct use of low-level actions. In experiments, we collect high-quality manipulation data for real dual-arm robot, and the results of simulation and real-world experiments demonstrate the effectiveness of our method.
Who is Undercover? Guiding LLMs to Explore Multi-Perspective Team Tactic in the Game
Oct 20, 2024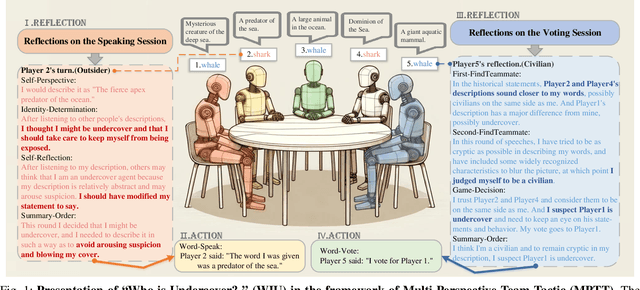

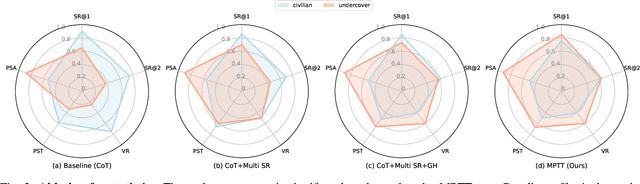

Large Language Models (LLMs) are pivotal AI agents in complex tasks but still face challenges in open decision-making problems within complex scenarios. To address this, we use the language logic game ``Who is Undercover?'' (WIU) as an experimental platform to propose the Multi-Perspective Team Tactic (MPTT) framework. MPTT aims to cultivate LLMs' human-like language expression logic, multi-dimensional thinking, and self-perception in complex scenarios. By alternating speaking and voting sessions, integrating techniques like self-perspective, identity-determination, self-reflection, self-summary and multi-round find-teammates, LLM agents make rational decisions through strategic concealment and communication, fostering human-like trust. Preliminary results show that MPTT, combined with WIU, leverages LLMs' cognitive capabilities to create a decision-making framework that can simulate real society. This framework aids minority groups in communication and expression, promoting fairness and diversity in decision-making. Additionally, our Human-in-the-loop experiments demonstrate that LLMs can learn and align with human behaviors through interactive, indicating their potential for active participation in societal decision-making.
Task-agnostic Pre-training and Task-guided Fine-tuning for Versatile Diffusion Planner
Sep 30, 2024



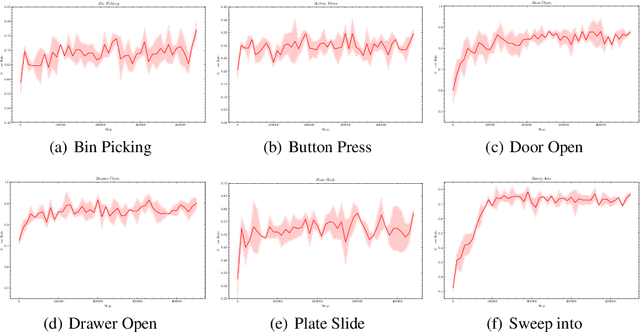
Diffusion models have demonstrated their capabilities in modeling trajectories of multi-tasks. However, existing multi-task planners or policies typically rely on task-specific demonstrations via multi-task imitation, or require task-specific reward labels to facilitate policy optimization via Reinforcement Learning (RL). To address these challenges, we aim to develop a versatile diffusion planner that can leverage large-scale inferior data that contains task-agnostic sub-optimal trajectories, with the ability to fast adapt to specific tasks. In this paper, we propose \textbf{SODP}, a two-stage framework that leverages \textbf{S}ub-\textbf{O}ptimal data to learn a \textbf{D}iffusion \textbf{P}lanner, which is generalizable for various downstream tasks. Specifically, in the pre-training stage, we train a foundation diffusion planner that extracts general planning capabilities by modeling the versatile distribution of multi-task trajectories, which can be sub-optimal and has wide data coverage. Then for downstream tasks, we adopt RL-based fine-tuning with task-specific rewards to fast refine the diffusion planner, which aims to generate action sequences with higher task-specific returns. Experimental results from multi-task domains including Meta-World and Adroit demonstrate that SODP outperforms state-of-the-art methods with only a small amount of data for reward-guided fine-tuning.
Forward KL Regularized Preference Optimization for Aligning Diffusion Policies
Sep 09, 2024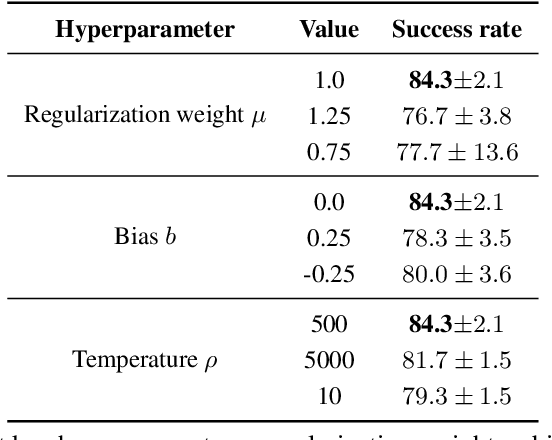
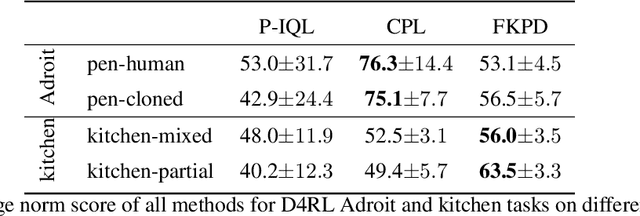
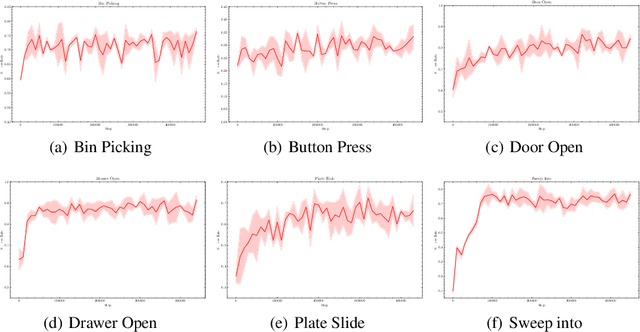
Diffusion models have achieved remarkable success in sequential decision-making by leveraging the highly expressive model capabilities in policy learning. A central problem for learning diffusion policies is to align the policy output with human intents in various tasks. To achieve this, previous methods conduct return-conditioned policy generation or Reinforcement Learning (RL)-based policy optimization, while they both rely on pre-defined reward functions. In this work, we propose a novel framework, Forward KL regularized Preference optimization for aligning Diffusion policies, to align the diffusion policy with preferences directly. We first train a diffusion policy from the offline dataset without considering the preference, and then align the policy to the preference data via direct preference optimization. During the alignment phase, we formulate direct preference learning in a diffusion policy, where the forward KL regularization is employed in preference optimization to avoid generating out-of-distribution actions. We conduct extensive experiments for MetaWorld manipulation and D4RL tasks. The results show our method exhibits superior alignment with preferences and outperforms previous state-of-the-art algorithms.
Sci-CoT: Leveraging Large Language Models for Enhanced Knowledge Distillation in Small Models for Scientific QA
Aug 09, 2023

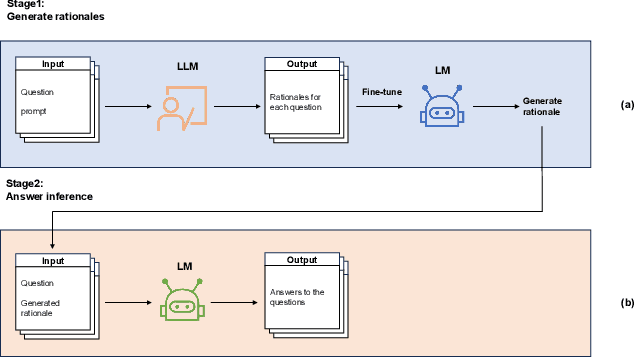
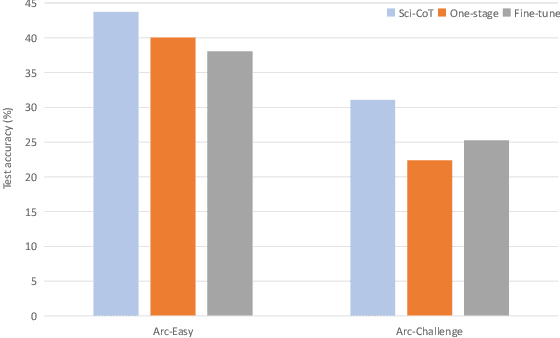
Large Language Models (LLMs) have shown outstanding performance across wide range of downstream tasks. This competency is attributed to their substantial parameter size and pre-training on extensive corpus. Moreover, LLMs have exhibited enhanced reasoning capabilities in tackling complex reasoning tasks, owing to the utilization of a method named ``Chain-of-Thought (CoT) prompting''. This method is designed to generate intermediate reasoning steps that guide the inference of the final answer. However, it is essential to highlight that these advanced reasoning abilities appear to emerge in models with a minimum of 10 billion parameters, thereby limiting its efficacy in situations where computational resources are constrained. In this paper, we investigate the possibility of transferring the reasoning capabilities of LLMs to smaller models via knowledge distillation. Specifically, we propose Sci-CoT, a two-stage framework that separates the processes of generating rationales and inferring answers. This method enables a more efficient use of rationales during the answer inference stage, leading to improved performance on scientific question-answering tasks. Utilizing Sci-CoT, our 80-million parameter model is able to exceed the performance of BLOOM-176B in the ARC-Easy dataset under the few shot setting.
Carbon Price Forecasting with Quantile Regression and Feature Selection
May 05, 2023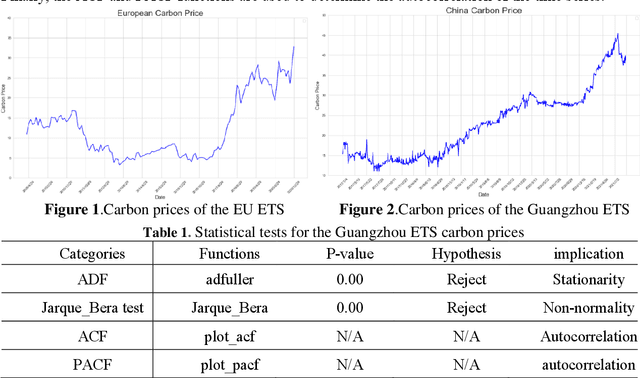
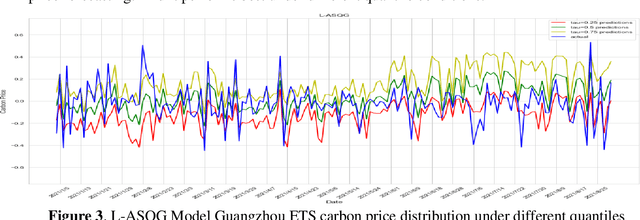
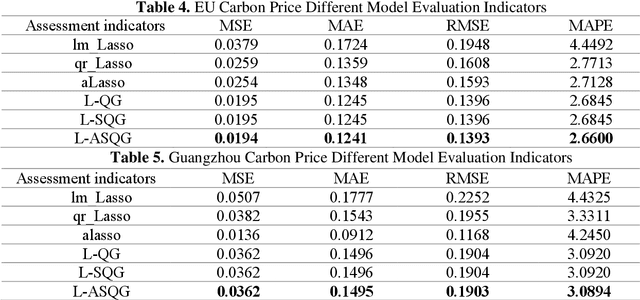
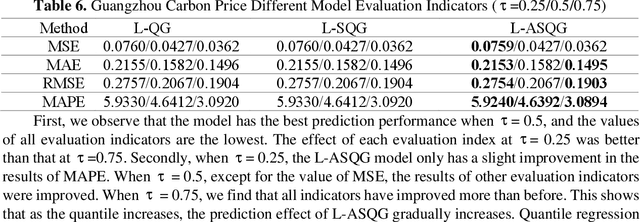
Carbon futures has recently emerged as a novel financial asset in the trading markets such as the European Union and China. Monitoring the trend of the carbon price has become critical for both national policy-making as well as industrial manufacturing planning. However, various geopolitical, social, and economic factors can impose substantial influence on the carbon price. Due to its volatility and non-linearity, predicting accurate carbon prices is generally a difficult task. In this study, we propose to improve carbon price forecasting with several novel practices. First, we collect various influencing factors, including commodity prices, export volumes such as oil and natural gas, and prosperity indices. Then we select the most significant factors and disclose their optimal grouping for explainability. Finally, we use the Sparse Quantile Group Lasso and Adaptive Sparse Quantile Group Lasso for robust price predictions. We demonstrate through extensive experimental studies that our proposed methods outperform existing ones. Also, our quantile predictions provide a complete profile of future prices at different levels, which better describes the distributions of the carbon market.
Towards Applying Powerful Large AI Models in Classroom Teaching: Opportunities, Challenges and Prospects
May 05, 2023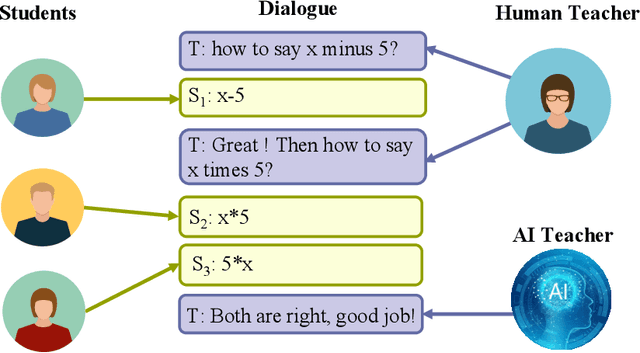
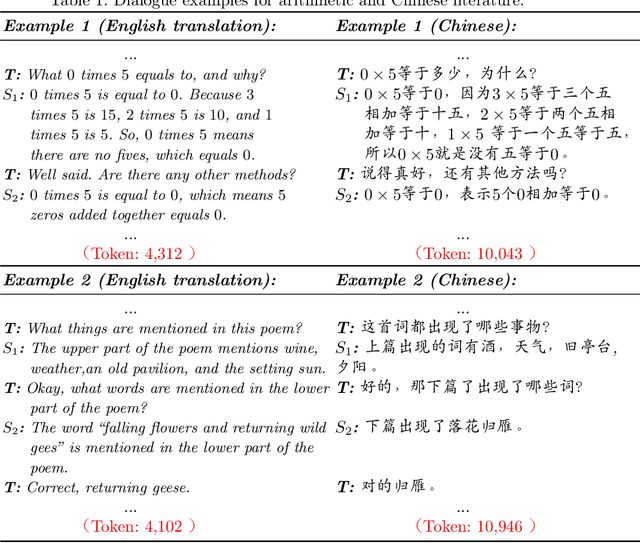
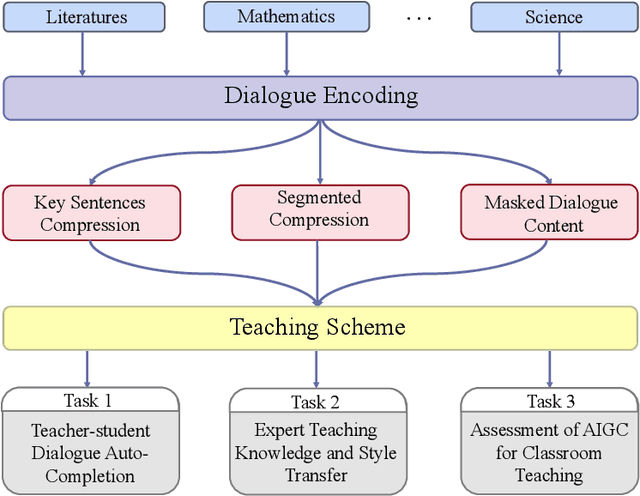
This perspective paper proposes a series of interactive scenarios that utilize Artificial Intelligence (AI) to enhance classroom teaching, such as dialogue auto-completion, knowledge and style transfer, and assessment of AI-generated content. By leveraging recent developments in Large Language Models (LLMs), we explore the potential of AI to augment and enrich teacher-student dialogues and improve the quality of teaching. Our goal is to produce innovative and meaningful conversations between teachers and students, create standards for evaluation, and improve the efficacy of AI-for-Education initiatives. In Section 3, we discuss the challenges of utilizing existing LLMs to effectively complete the educated tasks and present a unified framework for addressing diverse education dataset, processing lengthy conversations, and condensing information to better accomplish more downstream tasks. In Section 4, we summarize the pivoting tasks including Teacher-Student Dialogue Auto-Completion, Expert Teaching Knowledge and Style Transfer, and Assessment of AI-Generated Content (AIGC), providing a clear path for future research. In Section 5, we also explore the use of external and adjustable LLMs to improve the generated content through human-in-the-loop supervision and reinforcement learning. Ultimately, this paper seeks to highlight the potential for AI to aid the field of education and promote its further exploration.
Federated Prompting and Chain-of-Thought Reasoning for Improving LLMs Answering
Apr 27, 2023



We investigate how to enhance answer precision in frequently asked questions posed by distributed users using cloud-based Large Language Models (LLMs). Our study focuses on a typical situations where users ask similar queries that involve identical mathematical reasoning steps and problem-solving procedures. Due to the unsatisfactory accuracy of LLMs' zero-shot prompting with standalone questions, we propose to improve the distributed synonymous questions using Self-Consistency (SC) and Chain-of-Thought (CoT) techniques. Specifically, we first retrieve synonymous questions from a crowd-sourced database and create a federated question pool. We call these federated synonymous questions with the same or different parameters SP-questions or DP-questions, respectively. We refer to our methods as Fed-SP-SC and Fed-DP-CoT, which can generate significantly more accurate answers for all user queries without requiring sophisticated model-tuning. Through extensive experiments, we demonstrate that our proposed methods can significantly enhance question accuracy by fully exploring the synonymous nature of the questions and the consistency of the answers.
Lifelong-MonoDepth: Lifelong Learning for Multi-Domain Monocular Metric Depth Estimation
Mar 09, 2023



In recent years, monocular depth estimation (MDE) has gained significant progress in a data-driven learning fashion. Previous methods can infer depth maps for specific domains based on the paradigm of single-domain or joint-domain training with mixed data. However, they suffer from low scalability to new domains. In reality, target domains often dynamically change or increase, raising the requirement of incremental multi-domain/task learning. In this paper, we seek to enable lifelong learning for MDE, which performs cross-domain depth learning sequentially, to achieve high plasticity on a new domain and maintain good stability on original domains. To overcome significant domain gaps and enable scale-aware depth prediction, we design a lightweight multi-head framework that consists of a domain-shared encoder for feature extraction and domain-specific predictors for metric depth estimation. Moreover, given an input image, we propose an efficient predictor selection approach that automatically identifies the corresponding predictor for depth inference. Through extensive numerical studies, we show that the proposed method can achieve good efficiency, stability, and plasticity, leading the benchmarks by 8% to 15%.
Progressive Self-Distillation for Ground-to-Aerial Perception Knowledge Transfer
Aug 29, 2022
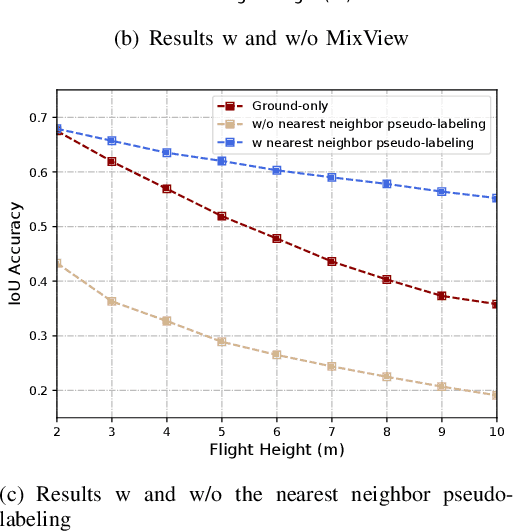
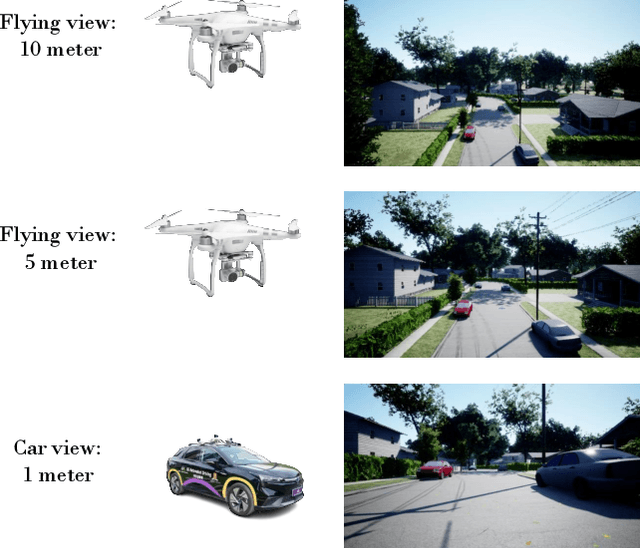
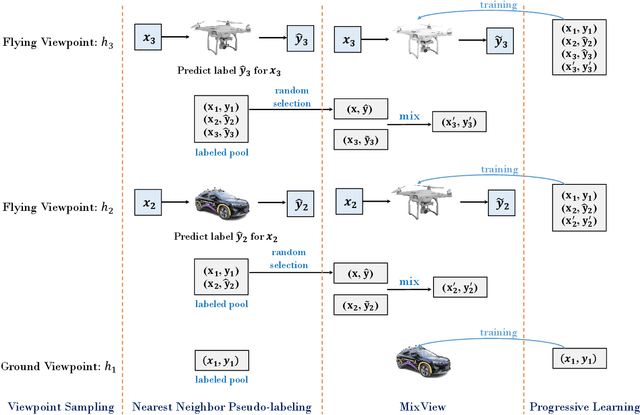
We study a practical yet hasn't been explored problem: how a drone can perceive in an environment from viewpoints of different flight heights. Unlike autonomous driving where the perception is always conducted from a ground viewpoint, a flying drone may flexibly change its flight height due to specific tasks, requiring capability for viewpoint invariant perception. To reduce the effort of annotation of flight data, we consider a ground-to-aerial knowledge distillation method while using only labeled data of ground viewpoint and unlabeled data of flying viewpoints. To this end, we propose a progressive semi-supervised learning framework which has four core components: a dense viewpoint sampling strategy that splits the range of vertical flight height into a set of small pieces with evenly-distributed intervals, and at each height we sample data from that viewpoint; the nearest neighbor pseudo-labeling that infers labels of the nearest neighbor viewpoint with a model learned on the preceding viewpoint; MixView that generates augmented images among different viewpoints to alleviate viewpoint difference; and a progressive distillation strategy to gradually learn until reaching the maximum flying height. We collect a synthesized dataset and a real-world dataset, and we perform extensive experiments to show that our method yields promising results for different flight heights.