 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSELA: Tree-Search Enhanced LLM Agents for Automated Machine Learning
Oct 22, 2024



Automated Machine Learning (AutoML) approaches encompass traditional methods that optimize fixed pipelines for model selection and ensembling, as well as newer LLM-based frameworks that autonomously build pipelines. While LLM-based agents have shown promise in automating machine learning tasks, they often generate low-diversity and suboptimal code, even after multiple iterations. To overcome these limitations, we introduce Tree-Search Enhanced LLM Agents (SELA), an innovative agent-based system that leverages Monte Carlo Tree Search (MCTS) to optimize the AutoML process. By representing pipeline configurations as trees, our framework enables agents to conduct experiments intelligently and iteratively refine their strategies, facilitating a more effective exploration of the machine learning solution space. This novel approach allows SELA to discover optimal pathways based on experimental feedback, improving the overall quality of the solutions. In an extensive evaluation across 20 machine learning datasets, we compare the performance of traditional and agent-based AutoML methods, demonstrating that SELA achieves a win rate of 65% to 80% against each baseline across all datasets. These results underscore the significant potential of agent-based strategies in AutoML, offering a fresh perspective on tackling complex machine learning challenges.
Carbon Price Forecasting with Quantile Regression and Feature Selection
May 05, 2023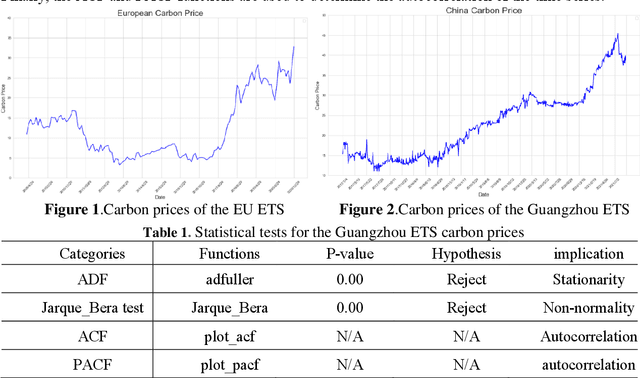
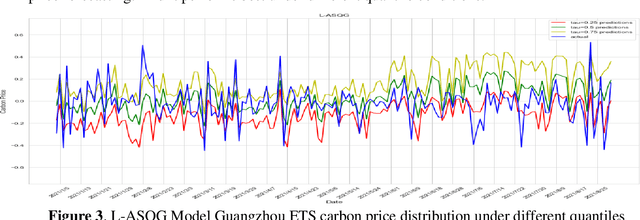
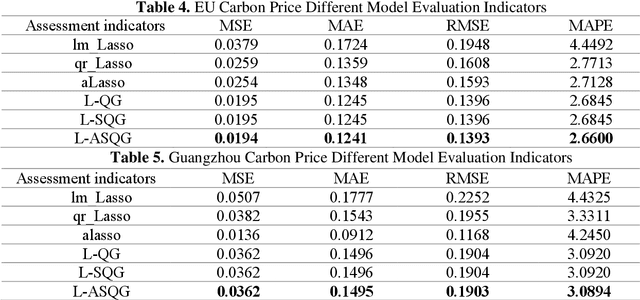
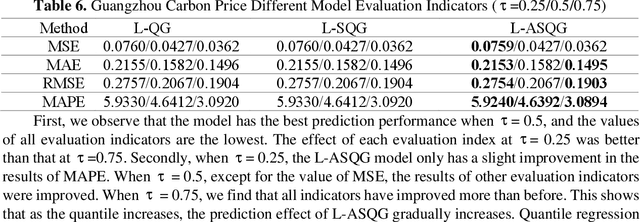
Carbon futures has recently emerged as a novel financial asset in the trading markets such as the European Union and China. Monitoring the trend of the carbon price has become critical for both national policy-making as well as industrial manufacturing planning. However, various geopolitical, social, and economic factors can impose substantial influence on the carbon price. Due to its volatility and non-linearity, predicting accurate carbon prices is generally a difficult task. In this study, we propose to improve carbon price forecasting with several novel practices. First, we collect various influencing factors, including commodity prices, export volumes such as oil and natural gas, and prosperity indices. Then we select the most significant factors and disclose their optimal grouping for explainability. Finally, we use the Sparse Quantile Group Lasso and Adaptive Sparse Quantile Group Lasso for robust price predictions. We demonstrate through extensive experimental studies that our proposed methods outperform existing ones. Also, our quantile predictions provide a complete profile of future prices at different levels, which better describes the distributions of the carbon market.
Towards Applying Powerful Large AI Models in Classroom Teaching: Opportunities, Challenges and Prospects
May 05, 2023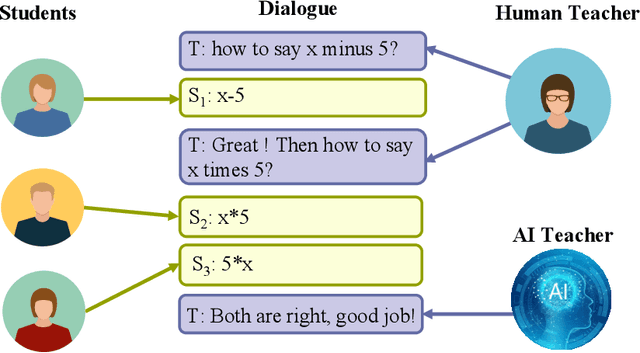
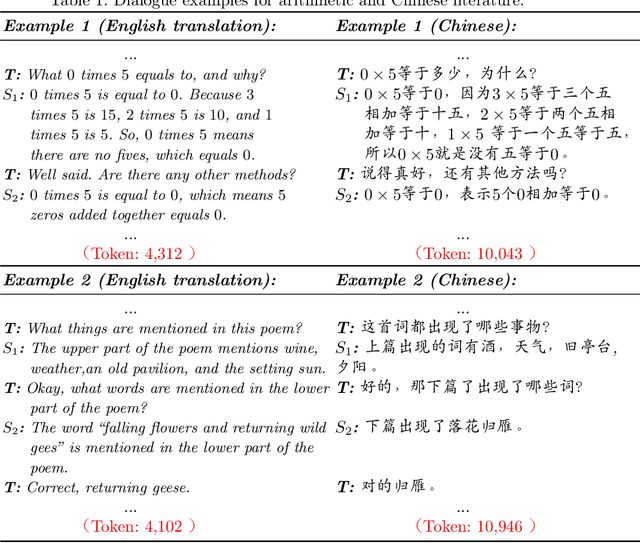
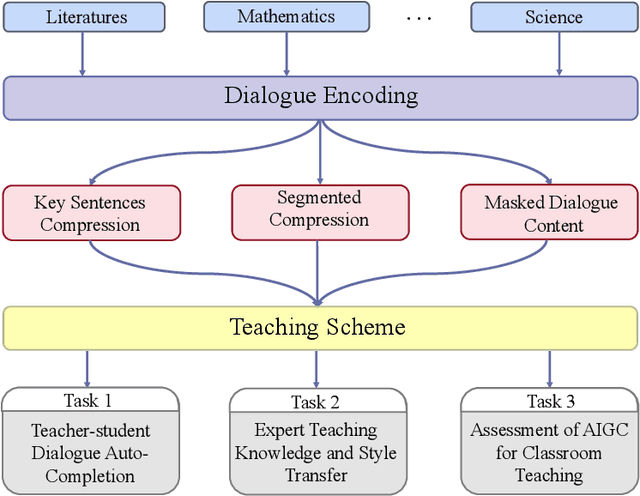
This perspective paper proposes a series of interactive scenarios that utilize Artificial Intelligence (AI) to enhance classroom teaching, such as dialogue auto-completion, knowledge and style transfer, and assessment of AI-generated content. By leveraging recent developments in Large Language Models (LLMs), we explore the potential of AI to augment and enrich teacher-student dialogues and improve the quality of teaching. Our goal is to produce innovative and meaningful conversations between teachers and students, create standards for evaluation, and improve the efficacy of AI-for-Education initiatives. In Section 3, we discuss the challenges of utilizing existing LLMs to effectively complete the educated tasks and present a unified framework for addressing diverse education dataset, processing lengthy conversations, and condensing information to better accomplish more downstream tasks. In Section 4, we summarize the pivoting tasks including Teacher-Student Dialogue Auto-Completion, Expert Teaching Knowledge and Style Transfer, and Assessment of AI-Generated Content (AIGC), providing a clear path for future research. In Section 5, we also explore the use of external and adjustable LLMs to improve the generated content through human-in-the-loop supervision and reinforcement learning. Ultimately, this paper seeks to highlight the potential for AI to aid the field of education and promote its further exploration.
Federated Prompting and Chain-of-Thought Reasoning for Improving LLMs Answering
Apr 27, 2023



We investigate how to enhance answer precision in frequently asked questions posed by distributed users using cloud-based Large Language Models (LLMs). Our study focuses on a typical situations where users ask similar queries that involve identical mathematical reasoning steps and problem-solving procedures. Due to the unsatisfactory accuracy of LLMs' zero-shot prompting with standalone questions, we propose to improve the distributed synonymous questions using Self-Consistency (SC) and Chain-of-Thought (CoT) techniques. Specifically, we first retrieve synonymous questions from a crowd-sourced database and create a federated question pool. We call these federated synonymous questions with the same or different parameters SP-questions or DP-questions, respectively. We refer to our methods as Fed-SP-SC and Fed-DP-CoT, which can generate significantly more accurate answers for all user queries without requiring sophisticated model-tuning. Through extensive experiments, we demonstrate that our proposed methods can significantly enhance question accuracy by fully exploring the synonymous nature of the questions and the consistency of the answers.