 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImitate Before Detect: Aligning Machine Stylistic Preference for Machine-Revised Text Detection
Dec 22, 2024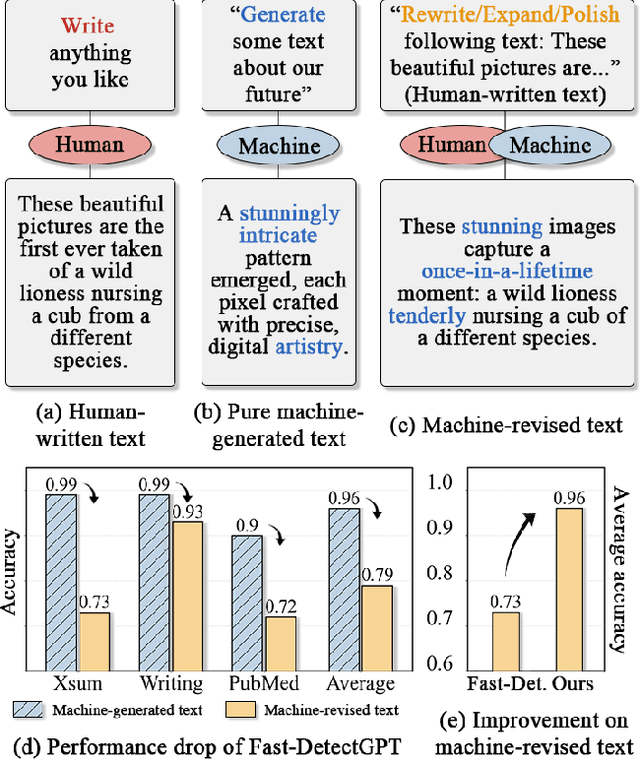
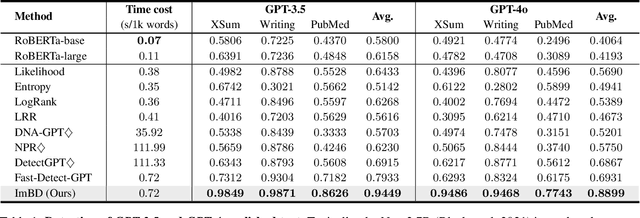
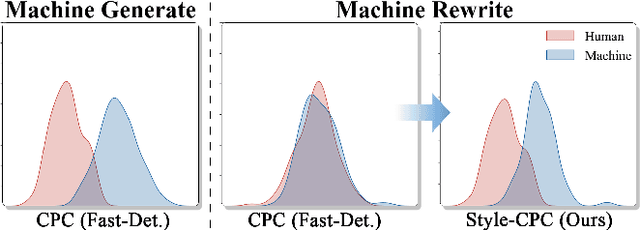
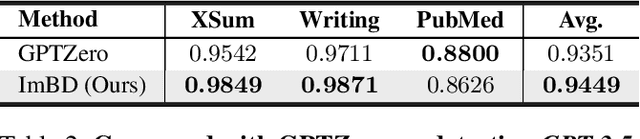
Large Language Models (LLMs) have revolutionized text generation, making detecting machine-generated text increasingly challenging. Although past methods have achieved good performance on detecting pure machine-generated text, those detectors have poor performance on distinguishing machine-revised text (rewriting, expansion, and polishing), which can have only minor changes from its original human prompt. As the content of text may originate from human prompts, detecting machine-revised text often involves identifying distinctive machine styles, e.g., worded favored by LLMs. However, existing methods struggle to detect machine-style phrasing hidden within the content contributed by humans. We propose the "Imitate Before Detect" (ImBD) approach, which first imitates the machine-style token distribution, and then compares the distribution of the text to be tested with the machine-style distribution to determine whether the text has been machine-revised. To this end, we introduce style preference optimization (SPO), which aligns a scoring LLM model to the preference of text styles generated by machines. The aligned scoring model is then used to calculate the style-conditional probability curvature (Style-CPC), quantifying the log probability difference between the original and conditionally sampled texts for effective detection. We conduct extensive comparisons across various scenarios, encompassing text revisions by six LLMs, four distinct text domains, and three machine revision types. Compared to existing state-of-the-art methods, our method yields a 13% increase in AUC for detecting text revised by open-source LLMs, and improves performance by 5% and 19% for detecting GPT-3.5 and GPT-4o revised text, respectively. Notably, our method surpasses the commercially trained GPT-Zero with just $1,000$ samples and five minutes of SPO, demonstrating its efficiency and effectiveness.
SELA: Tree-Search Enhanced LLM Agents for Automated Machine Learning
Oct 22, 2024



Automated Machine Learning (AutoML) approaches encompass traditional methods that optimize fixed pipelines for model selection and ensembling, as well as newer LLM-based frameworks that autonomously build pipelines. While LLM-based agents have shown promise in automating machine learning tasks, they often generate low-diversity and suboptimal code, even after multiple iterations. To overcome these limitations, we introduce Tree-Search Enhanced LLM Agents (SELA), an innovative agent-based system that leverages Monte Carlo Tree Search (MCTS) to optimize the AutoML process. By representing pipeline configurations as trees, our framework enables agents to conduct experiments intelligently and iteratively refine their strategies, facilitating a more effective exploration of the machine learning solution space. This novel approach allows SELA to discover optimal pathways based on experimental feedback, improving the overall quality of the solutions. In an extensive evaluation across 20 machine learning datasets, we compare the performance of traditional and agent-based AutoML methods, demonstrating that SELA achieves a win rate of 65% to 80% against each baseline across all datasets. These results underscore the significant potential of agent-based strategies in AutoML, offering a fresh perspective on tackling complex machine learning challenges.