 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSongSage: A Large Musical Language Model with Lyric Generative Pre-training
Jan 03, 2026Large language models have achieved significant success in various domains, yet their understanding of lyric-centric knowledge has not been fully explored. In this work, we first introduce PlaylistSense, a dataset to evaluate the playlist understanding capability of language models. PlaylistSense encompasses ten types of user queries derived from common real-world perspectives, challenging LLMs to accurately grasp playlist features and address diverse user intents. Comprehensive evaluations indicate that current general-purpose LLMs still have potential for improvement in playlist understanding. Inspired by this, we introduce SongSage, a large musical language model equipped with diverse lyric-centric intelligence through lyric generative pretraining. SongSage undergoes continual pretraining on LyricBank, a carefully curated corpus of 5.48 billion tokens focused on lyrical content, followed by fine-tuning with LyricBank-SFT, a meticulously crafted instruction set comprising 775k samples across nine core lyric-centric tasks. Experimental results demonstrate that SongSage exhibits a strong understanding of lyric-centric knowledge, excels in rewriting user queries for zero-shot playlist recommendations, generates and continues lyrics effectively, and performs proficiently across seven additional capabilities. Beyond its lyric-centric expertise, SongSage also retains general knowledge comprehension and achieves a competitive MMLU score. We will keep the datasets inaccessible due to copyright restrictions and release the SongSage and training script to ensure reproducibility and support music AI research and applications, the datasets release plan details are provided in the appendix.
DHI: Leveraging Diverse Hallucination Induction for Enhanced Contrastive Factuality Control in Large Language Models
Jan 03, 2026Large language models (LLMs) frequently produce inaccurate or fabricated information, known as "hallucinations," which compromises their reliability. Existing approaches often train an "Evil LLM" to deliberately generate hallucinations on curated datasets, using these induced hallucinations to guide contrastive decoding against a reliable "positive model" for hallucination mitigation. However, this strategy is limited by the narrow diversity of hallucinations induced, as Evil LLMs trained on specific error types tend to reproduce only these particular patterns, thereby restricting their overall effectiveness. To address these limitations, we propose DHI (Diverse Hallucination Induction), a novel training framework that enables the Evil LLM to generate a broader range of hallucination types without relying on pre-annotated hallucination data. DHI employs a modified loss function that down-weights the generation of specific factually correct tokens, encouraging the Evil LLM to produce diverse hallucinations at targeted positions while maintaining overall factual content. Additionally, we introduce a causal attention masking adaptation to reduce the impact of this penalization on the generation of subsequent tokens. During inference, we apply an adaptive rationality constraint that restricts contrastive decoding to tokens where the positive model exhibits high confidence, thereby avoiding unnecessary penalties on factually correct tokens. Extensive empirical results show that DHI achieves significant performance gains over other contrastive decoding-based approaches across multiple hallucination benchmarks.
Ghost in the Transformer: Tracing LLM Lineage with SVD-Fingerprint
Nov 17, 2025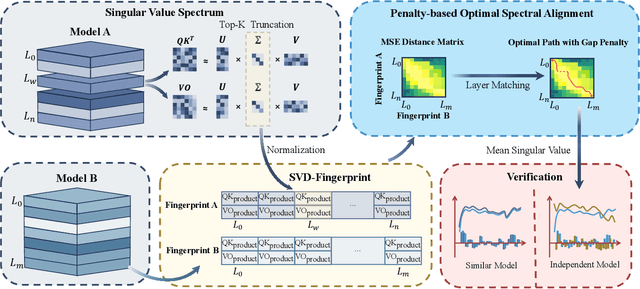
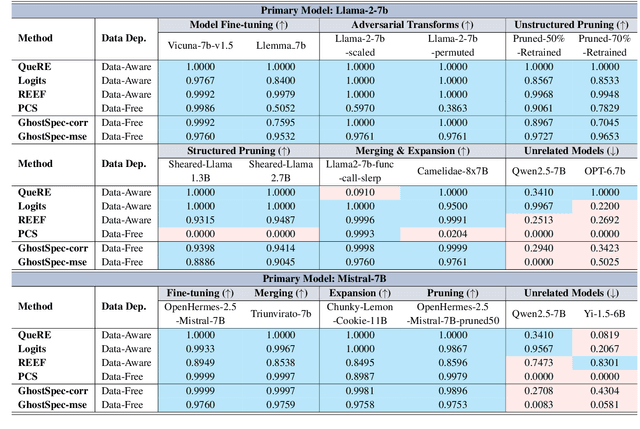
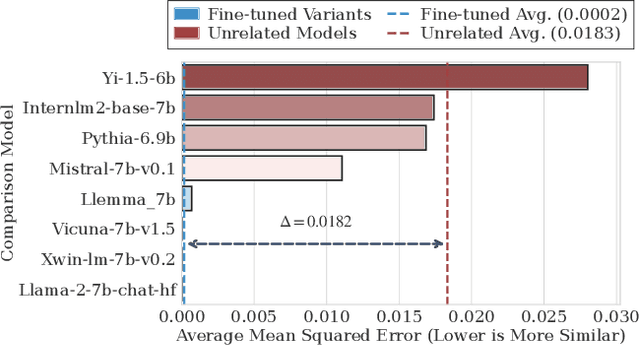
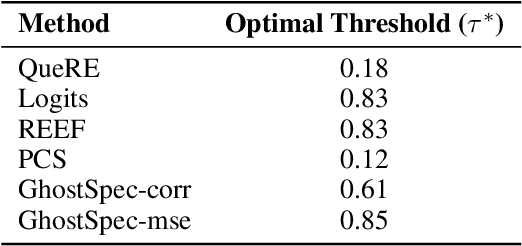
Large Language Models (LLMs) have rapidly advanced and are widely adopted across diverse fields. Due to the substantial computational cost and data requirements of training from scratch, many developers choose to fine-tune or modify existing open-source models. While most adhere to open-source licenses, some falsely claim original training despite clear derivation from public models. This raises pressing concerns about intellectual property protection and highlights the need for reliable methods to verify model provenance. In this paper, we propose GhostSpec, a lightweight yet effective method for verifying LLM lineage without access to training data or modification of model behavior. Our approach constructs compact and robust fingerprints by applying singular value decomposition (SVD) to invariant products of internal attention weight matrices, effectively capturing the structural identity of a model. Unlike watermarking or output-based methods, GhostSpec is fully data-free, non-invasive, and computationally efficient. It demonstrates strong robustness to sequential fine-tuning, pruning, block expansion, and even adversarial transformations. Extensive experiments show that GhostSpec can reliably trace the lineage of transformed models with minimal overhead. By offering a practical solution for model verification and reuse tracking, our method contributes to the protection of intellectual property and fosters a transparent, trustworthy ecosystem for large-scale language models.
End-to-end Contrastive Language-Speech Pretraining Model For Long-form Spoken Question Answering
Nov 12, 2025Significant progress has been made in spoken question answering (SQA) in recent years. However, many existing methods, including large audio language models, struggle with processing long audio. Follow the success of retrieval augmented generation, a speech-related retriever shows promising in help preprocessing long-form speech. But the performance of existing speech-related retrievers is lacking. To address this challenge, we propose CLSR, an end-to-end contrastive language-speech retriever that efficiently extracts question-relevant segments from long audio recordings for downstream SQA task. Unlike conventional speech-text contrastive models, CLSR incorporates an intermediate step that converts acoustic features into text-like representations prior to alignment, thereby more effectively bridging the gap between modalities. Experimental results across four cross-modal retrieval datasets demonstrate that CLSR surpasses both end-to-end speech related retrievers and pipeline approaches combining speech recognition with text retrieval, providing a robust foundation for advancing practical long-form SQA applications.
CoViPAL: Layer-wise Contextualized Visual Token Pruning for Large Vision-Language Models
Aug 24, 2025Large Vision-Language Models (LVLMs) process multimodal inputs consisting of text tokens and vision tokens extracted from images or videos. Due to the rich visual information, a single image can generate thousands of vision tokens, leading to high computational costs during the prefilling stage and significant memory overhead during decoding. Existing methods attempt to prune redundant vision tokens, revealing substantial redundancy in visual representations. However, these methods often struggle in shallow layers due to the lack of sufficient contextual information. We argue that many visual tokens are inherently redundant even in shallow layers and can be safely and effectively pruned with appropriate contextual signals. In this work, we propose CoViPAL, a layer-wise contextualized visual token pruning method that employs a Plug-and-Play Pruning Module (PPM) to predict and remove redundant vision tokens before they are processed by the LVLM. The PPM is lightweight, model-agnostic, and operates independently of the LVLM architecture, ensuring seamless integration with various models. Extensive experiments on multiple benchmarks demonstrate that CoViPAL outperforms training-free pruning methods under equal token budgets and surpasses training-based methods with comparable supervision. CoViPAL offers a scalable and efficient solution to improve inference efficiency in LVLMs without compromising accuracy.
IAM: Efficient Inference through Attention Mapping between Different-scale LLMs
Jul 16, 2025LLMs encounter significant challenges in resource consumption nowadays, especially with long contexts. Despite extensive efforts dedicate to enhancing inference efficiency, these methods primarily exploit internal sparsity within the models, without leveraging external information for optimization. We identify the high similarity of attention matrices across different-scale LLMs, which offers a novel perspective for optimization. We first conduct a comprehensive analysis of how to measure similarity, how to select mapping Layers and whether mapping is consistency. Based on these insights, we introduce the IAM framework, which achieves dual benefits of accelerated attention computation and reduced KV cache usage by performing attention mapping between small and large LLMs. Our experimental results demonstrate that IAM can accelerate prefill by 15% and reduce KV cache usage by 22.1% without appreciably sacrificing performance. Experiments on different series of models show the generalizability of IAM. Importantly, it is also orthogonal to many existing KV cache optimization methods, making it a versatile addition to the current toolkit for enhancing LLM efficiency.
DAC: A Dynamic Attention-aware Approach for Task-Agnostic Prompt Compression
Jul 16, 2025Task-agnostic prompt compression leverages the redundancy in natural language to reduce computational overhead and enhance information density within prompts, especially in long-context scenarios. Existing methods predominantly rely on information entropy as the metric to compress lexical units, aiming to achieve minimal information loss. However, these approaches overlook two critical aspects: (i) the importance of attention-critical tokens at the algorithmic level, and (ii) shifts in information entropy during the compression process. Motivated by these challenges, we propose a dynamic attention-aware approach for task-agnostic prompt compression (DAC). This approach effectively integrates entropy and attention information, dynamically sensing entropy shifts during compression to achieve fine-grained prompt compression. Extensive experiments across various domains, including LongBench, GSM8K, and BBH, show that DAC consistently yields robust and substantial improvements across a diverse range of tasks and LLMs, offering compelling evidence of its efficacy.
SpindleKV: A Novel KV Cache Reduction Method Balancing Both Shallow and Deep Layers
Jul 09, 2025Large Language Models (LLMs) have achieved impressive accomplishments in recent years. However, the increasing memory consumption of KV cache has possessed a significant challenge to the inference system. Eviction methods have revealed the inherent redundancy within the KV cache, demonstrating its potential for reduction, particularly in deeper layers. However, KV cache reduction for shallower layers has been found to be insufficient. Based on our observation that, the KV cache exhibits a high degree of similarity. Based on this observation, we proposed a novel KV cache reduction method, SpindleKV, which balances both shallow and deep layers. For deep layers, we employ an attention weight based eviction method, while for shallow layers, we apply a codebook based replacement approach which is learnt by similarity and merging policy. Moreover, SpindleKV addressed the Grouped-Query Attention (GQA) dilemma faced by other attention based eviction methods. Experiments on two common benchmarks with three different LLMs shown that SpindleKV obtained better KV cache reduction effect compared to baseline methods, while preserving similar or even better model performance.
AMIA: Automatic Masking and Joint Intention Analysis Makes LVLMs Robust Jailbreak Defenders
May 30, 2025We introduce AMIA, a lightweight, inference-only defense for Large Vision-Language Models (LVLMs) that (1) Automatically Masks a small set of text-irrelevant image patches to disrupt adversarial perturbations, and (2) conducts joint Intention Analysis to uncover and mitigate hidden harmful intents before response generation. Without any retraining, AMIA improves defense success rates across diverse LVLMs and jailbreak benchmarks from an average of 52.4% to 81.7%, preserves general utility with only a 2% average accuracy drop, and incurs only modest inference overhead. Ablation confirms both masking and intention analysis are essential for a robust safety-utility trade-off.
Segment First or Comprehend First? Explore the Limit of Unsupervised Word Segmentation with Large Language Models
May 26, 2025Word segmentation stands as a cornerstone of Natural Language Processing (NLP). Based on the concept of "comprehend first, segment later", we propose a new framework to explore the limit of unsupervised word segmentation with Large Language Models (LLMs) and evaluate the semantic understanding capabilities of LLMs based on word segmentation. We employ current mainstream LLMs to perform word segmentation across multiple languages to assess LLMs' "comprehension". Our findings reveal that LLMs are capable of following simple prompts to segment raw text into words. There is a trend suggesting that models with more parameters tend to perform better on multiple languages. Additionally, we introduce a novel unsupervised method, termed LLACA ($\textbf{L}$arge $\textbf{L}$anguage Model-Inspired $\textbf{A}$ho-$\textbf{C}$orasick $\textbf{A}$utomaton). Leveraging the advanced pattern recognition capabilities of Aho-Corasick automata, LLACA innovatively combines these with the deep insights of well-pretrained LLMs. This approach not only enables the construction of a dynamic $n$-gram model that adjusts based on contextual information but also integrates the nuanced understanding of LLMs, offering significant improvements over traditional methods. Our source code is available at https://github.com/hkr04/LLACA