 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeALADIN:Attribute-Language Distillation Network for Person Re-Identification
Mar 23, 2026Recent vision-language models such as CLIP provide strong cross-modal alignment, but current CLIP-guided ReID pipelines rely on global features and fixed prompts. This limits their ability to capture fine-grained attribute cues and adapt to diverse appearances. We propose ALADIN, an attribute-language distillation network that distills knowledge from a frozen CLIP teacher to a lightweight ReID student. ALADIN introduces fine-grained attribute-local alignment to establish adaptive text-visual correspondence and robust representation learning. A Scene-Aware Prompt Generator produces image-specific soft prompts to facilitate adaptive alignment. Attribute-local distillation enforces consistency between textual attributes and local visual features, significantly enhancing robustness under occlusions. Furthermore, we employ cross-modal contrastive and relation distillation to preserve the inherent structural relationships among attributes. To provide precise supervision, we leverage Multimodal LLMs to generate structured attribute descriptions, which are then converted into localized attention maps via CLIP. At inference, only the student is used. Experiments on Market-1501, DukeMTMC-reID, and MSMT17 show improvements over CNN-, Transformer-, and CLIP-based methods, with better generalization and interpretability.
Joint Automatic Speech Recognition And Structure Learning For Better Speech Understanding
Jan 13, 2025



Spoken language understanding (SLU) is a structure prediction task in the field of speech. Recently, many works on SLU that treat it as a sequence-to-sequence task have achieved great success. However, This method is not suitable for simultaneous speech recognition and understanding. In this paper, we propose a joint speech recognition and structure learning framework (JSRSL), an end-to-end SLU model based on span, which can accurately transcribe speech and extract structured content simultaneously. We conduct experiments on name entity recognition and intent classification using the Chinese dataset AISHELL-NER and the English dataset SLURP. The results show that our proposed method not only outperforms the traditional sequence-to-sequence method in both transcription and extraction capabilities but also achieves state-of-the-art performance on the two datasets.
VHASR: A Multimodal Speech Recognition System With Vision Hotwords
Oct 01, 2024



The image-based multimodal automatic speech recognition (ASR) model enhances speech recognition performance by incorporating audio-related image. However, some works suggest that introducing image information to model does not help improving ASR performance. In this paper, we propose a novel approach effectively utilizing audio-related image information and set up VHASR, a multimodal speech recognition system that uses vision as hotwords to strengthen the model's speech recognition capability. Our system utilizes a dual-stream architecture, which firstly transcribes the text on the two streams separately, and then combines the outputs. We evaluate the proposed model on four datasets: Flickr8k, ADE20k, COCO, and OpenImages. The experimental results show that VHASR can effectively utilize key information in images to enhance the model's speech recognition ability. Its performance not only surpasses unimodal ASR, but also achieves SOTA among existing image-based multimodal ASR.
Hypergraph based Understanding for Document Semantic Entity Recognition
Jul 09, 2024
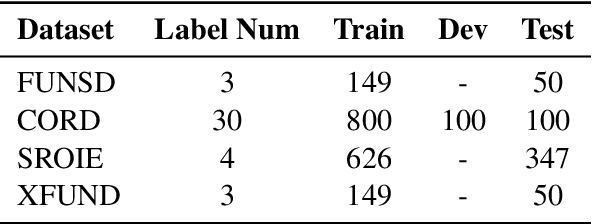
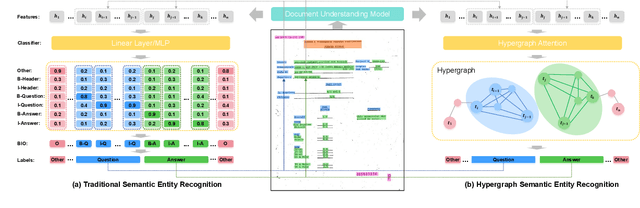
Semantic entity recognition is an important task in the field of visually-rich document understanding. It distinguishes the semantic types of text by analyzing the position relationship between text nodes and the relation between text content. The existing document understanding models mainly focus on entity categories while ignoring the extraction of entity boundaries. We build a novel hypergraph attention document semantic entity recognition framework, HGA, which uses hypergraph attention to focus on entity boundaries and entity categories at the same time. It can conduct a more detailed analysis of the document text representation analyzed by the upstream model and achieves a better performance of semantic information. We apply this method on the basis of GraphLayoutLM to construct a new semantic entity recognition model HGALayoutLM. Our experiment results on FUNSD, CORD, XFUND and SROIE show that our method can effectively improve the performance of semantic entity recognition tasks based on the original model. The results of HGALayoutLM on FUNSD and XFUND reach the new state-of-the-art results.
Error Model of Radio Fingerprint and PDR Fusion Indoor Localization
Jan 05, 2020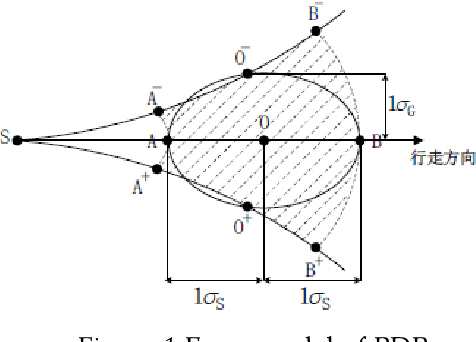
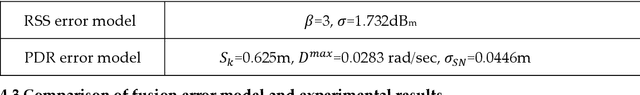
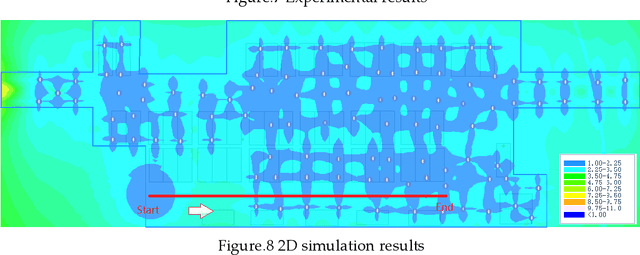
Multi-source fusion positioning is one of the technical frameworks for obtaining sufficient indoor positioning accuracy. In order to evaluate the effect of multi-source fusion positioning, it is necessary to establish a fusion error model. In this paper, we first use the least squares method to fuse the radio fingerprint and the PDR positioning, and then apply the variance propagation laws to calculate the error distribution of indoor multi-source localization methods. Based on the fusion error model, we developed an indoor positioning simulation system. The system can give a better positioning source layout scheme under a given condition, and can evaluate the signal strength distribution and the error distribution.