 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEnhanced Diagnostic Performance via Large-Resolution Inference Optimization for Pathology Foundation Models
Jan 17, 2026Despite their prominent performance on tasks such as ROI classification and segmentation, many pathology foundation models remain constrained by a specific input size e.g. 224 x 224, creating substantial inefficiencies when applied to whole-slide images (WSIs), which span thousands of resolutions. A naive strategy is to either enlarge inputs or downsample the WSIs. However, enlarging inputs results in prohibitive GPU memory consumption, while downsampling alters the microns-per-pixel resolution and obscures critical morphological details. To overcome these limitations, we propose an space- and time- efficient inference strategy that sparsifies attention using spatially aware neighboring blocks and filters out non-informative tokens through global attention scores. This design substantially reduces GPU memory and runtime during high-resolution WSI inference while preserving and even improving the downstream performance, enabling inference at higher resolutions under the same GPU budget. The experimental results show that our method can achieves up to an 7.67% improvement in the ROI classification and compatible results in segmentation.
Collaborative Optimization of Multiclass Imbalanced Learning: Density-Aware and Region-Guided Boosting
Dec 27, 2025Numerous studies attempt to mitigate classification bias caused by class imbalance. However, existing studies have yet to explore the collaborative optimization of imbalanced learning and model training. This constraint hinders further performance improvements. To bridge this gap, this study proposes a collaborative optimization Boosting model of multiclass imbalanced learning. This model is simple but effective by integrating the density factor and the confidence factor, this study designs a noise-resistant weight update mechanism and a dynamic sampling strategy. Rather than functioning as independent components, these modules are tightly integrated to orchestrate weight updates, sample region partitioning, and region-guided sampling. Thus, this study achieves the collaborative optimization of imbalanced learning and model training. Extensive experiments on 20 public imbalanced datasets demonstrate that the proposed model significantly outperforms eight state-of-the-art baselines. The code for the proposed model is available at: https://github.com/ChuantaoLi/DARG.
SimuFreeMark: A Noise-Simulation-Free Robust Watermarking Against Image Editing
Nov 14, 2025



The advancement of artificial intelligence generated content (AIGC) has created a pressing need for robust image watermarking that can withstand both conventional signal processing and novel semantic editing attacks. Current deep learning-based methods rely on training with hand-crafted noise simulation layers, which inherently limit their generalization to unforeseen distortions. In this work, we propose $\textbf{SimuFreeMark}$, a noise-$\underline{\text{simu}}$lation-$\underline{\text{free}}$ water$\underline{\text{mark}}$ing framework that circumvents this limitation by exploiting the inherent stability of image low-frequency components. We first systematically establish that low-frequency components exhibit significant robustness against a wide range of attacks. Building on this foundation, SimuFreeMark embeds watermarks directly into the deep feature space of the low-frequency components, leveraging a pre-trained variational autoencoder (VAE) to bind the watermark with structurally stable image representations. This design completely eliminates the need for noise simulation during training. Extensive experiments demonstrate that SimuFreeMark outperforms state-of-the-art methods across a wide range of conventional and semantic attacks, while maintaining superior visual quality.
Emotional Text-To-Speech Based on Mutual-Information-Guided Emotion-Timbre Disentanglement
Oct 02, 2025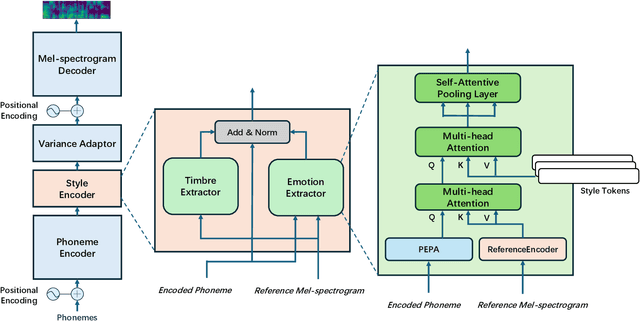
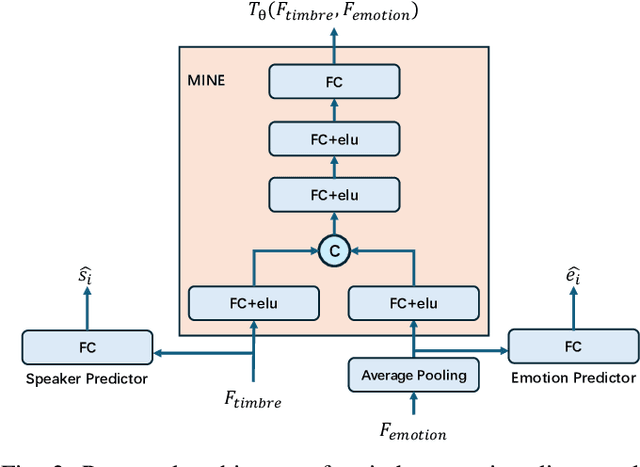
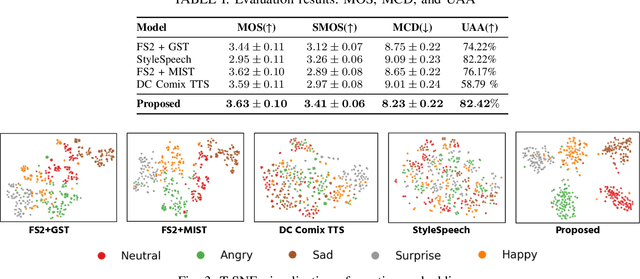
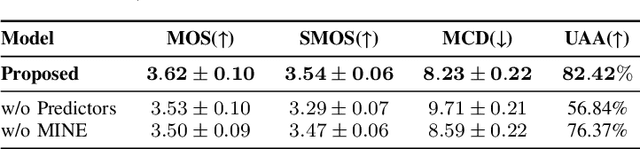
Current emotional Text-To-Speech (TTS) and style transfer methods rely on reference encoders to control global style or emotion vectors, but do not capture nuanced acoustic details of the reference speech. To this end, we propose a novel emotional TTS method that enables fine-grained phoneme-level emotion embedding prediction while disentangling intrinsic attributes of the reference speech. The proposed method employs a style disentanglement method to guide two feature extractors, reducing mutual information between timbre and emotion features, and effectively separating distinct style components from the reference speech. Experimental results demonstrate that our method outperforms baseline TTS systems in generating natural and emotionally rich speech. This work highlights the potential of disentangled and fine-grained representations in advancing the quality and flexibility of emotional TTS systems.
Neural Cone Radiosity for Interactive Global Illumination with Glossy Materials
Sep 09, 2025Modeling of high-frequency outgoing radiance distributions has long been a key challenge in rendering, particularly for glossy material. Such distributions concentrate radiative energy within a narrow lobe and are highly sensitive to changes in view direction. However, existing neural radiosity methods, which primarily rely on positional feature encoding, exhibit notable limitations in capturing these high-frequency, strongly view-dependent radiance distributions. To address this, we propose a highly-efficient approach by reflectance-aware ray cone encoding based on the neural radiosity framework, named neural cone radiosity. The core idea is to employ a pre-filtered multi-resolution hash grid to accurately approximate the glossy BSDF lobe, embedding view-dependent reflectance characteristics directly into the encoding process through continuous spatial aggregation. Our design not only significantly improves the network's ability to model high-frequency reflection distributions but also effectively handles surfaces with a wide range of glossiness levels, from highly glossy to low-gloss finishes. Meanwhile, our method reduces the network's burden in fitting complex radiance distributions, allowing the overall architecture to remain compact and efficient. Comprehensive experimental results demonstrate that our method consistently produces high-quality, noise-free renderings in real time under various glossiness conditions, and delivers superior fidelity and realism compared to baseline approaches.
Rethinking the Potential of Layer Freezing for Efficient DNN Training
Aug 20, 2025With the growing size of deep neural networks and datasets, the computational costs of training have significantly increased. The layer-freezing technique has recently attracted great attention as a promising method to effectively reduce the cost of network training. However, in traditional layer-freezing methods, frozen layers are still required for forward propagation to generate feature maps for unfrozen layers, limiting the reduction of computation costs. To overcome this, prior works proposed a hypothetical solution, which caches feature maps from frozen layers as a new dataset, allowing later layers to train directly on stored feature maps. While this approach appears to be straightforward, it presents several major challenges that are severely overlooked by prior literature, such as how to effectively apply augmentations to feature maps and the substantial storage overhead introduced. If these overlooked challenges are not addressed, the performance of the caching method will be severely impacted and even make it infeasible. This paper is the first to comprehensively explore these challenges and provides a systematic solution. To improve training accuracy, we propose \textit{similarity-aware channel augmentation}, which caches channels with high augmentation sensitivity with a minimum additional storage cost. To mitigate storage overhead, we incorporate lossy data compression into layer freezing and design a \textit{progressive compression} strategy, which increases compression rates as more layers are frozen, effectively reducing storage costs. Finally, our solution achieves significant reductions in training cost while maintaining model accuracy, with a minor time overhead. Additionally, we conduct a comprehensive evaluation of freezing and compression strategies, providing insights into optimizing their application for efficient DNN training.
Geometry-Aware Global Feature Aggregation for Real-Time Indirect Illumination
Aug 12, 2025



Real-time rendering with global illumination is crucial to afford the user realistic experience in virtual environments. We present a learning-based estimator to predict diffuse indirect illumination in screen space, which then is combined with direct illumination to synthesize globally-illuminated high dynamic range (HDR) results. Our approach tackles the challenges of capturing long-range/long-distance indirect illumination when employing neural networks and is generalized to handle complex lighting and scenarios. From the neural network thinking of the solver to the rendering equation, we present a novel network architecture to predict indirect illumination. Our network is equipped with a modified attention mechanism that aggregates global information guided by spacial geometry features, as well as a monochromatic design that encodes each color channel individually. We conducted extensive evaluations, and the experimental results demonstrate our superiority over previous learning-based techniques. Our approach excels at handling complex lighting such as varying-colored lighting and environment lighting. It can successfully capture distant indirect illumination and simulates the interreflections between textured surfaces well (i.e., color bleeding effects); it can also effectively handle new scenes that are not present in the training dataset.
Vertex Features for Neural Global Illumination
Aug 11, 2025Recent research on learnable neural representations has been widely adopted in the field of 3D scene reconstruction and neural rendering applications. However, traditional feature grid representations often suffer from substantial memory footprint, posing a significant bottleneck for modern parallel computing hardware. In this paper, we present neural vertex features, a generalized formulation of learnable representation for neural rendering tasks involving explicit mesh surfaces. Instead of uniformly distributing neural features throughout 3D space, our method stores learnable features directly at mesh vertices, leveraging the underlying geometry as a compact and structured representation for neural processing. This not only optimizes memory efficiency, but also improves feature representation by aligning compactly with the surface using task-specific geometric priors. We validate our neural representation across diverse neural rendering tasks, with a specific emphasis on neural radiosity. Experimental results demonstrate that our method reduces memory consumption to only one-fifth (or even less) of grid-based representations, while maintaining comparable rendering quality and lowering inference overhead.
End-to-end Acoustic-linguistic Emotion and Intent Recognition Enhanced by Semi-supervised Learning
Jul 10, 2025Emotion and intent recognition from speech is essential and has been widely investigated in human-computer interaction. The rapid development of social media platforms, chatbots, and other technologies has led to a large volume of speech data streaming from users. Nevertheless, annotating such data manually is expensive, making it challenging to train machine learning models for recognition purposes. To this end, we propose applying semi-supervised learning to incorporate a large scale of unlabelled data alongside a relatively smaller set of labelled data. We train end-to-end acoustic and linguistic models, each employing multi-task learning for emotion and intent recognition. Two semi-supervised learning approaches, including fix-match learning and full-match learning, are compared. The experimental results demonstrate that the semi-supervised learning approaches improve model performance in speech emotion and intent recognition from both acoustic and text data. The late fusion of the best models outperforms the acoustic and text baselines by joint recognition balance metrics of 12.3% and 10.4%, respectively.
Stroke-based Cyclic Amplifier: Image Super-Resolution at Arbitrary Ultra-Large Scales
Jun 12, 2025



Prior Arbitrary-Scale Image Super-Resolution (ASISR) methods often experience a significant performance decline when the upsampling factor exceeds the range covered by the training data, introducing substantial blurring. To address this issue, we propose a unified model, Stroke-based Cyclic Amplifier (SbCA), for ultra-large upsampling tasks. The key of SbCA is the stroke vector amplifier, which decomposes the image into a series of strokes represented as vector graphics for magnification. Then, the detail completion module also restores missing details, ensuring high-fidelity image reconstruction. Our cyclic strategy achieves ultra-large upsampling by iteratively refining details with this unified SbCA model, trained only once for all, while keeping sub-scales within the training range. Our approach effectively addresses the distribution drift issue and eliminates artifacts, noise and blurring, producing high-quality, high-resolution super-resolved images. Experimental validations on both synthetic and real-world datasets demonstrate that our approach significantly outperforms existing methods in ultra-large upsampling tasks (e.g. $\times100$), delivering visual quality far superior to state-of-the-art techniques.