 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe First Challenge on Remote Sensing Infrared Image Super-Resolution at NTIRE 2026: Benchmark Results and Method Overview
Apr 23, 2026This paper presents the NTIRE 2026 Remote Sensing Infrared Image Super-Resolution (x4) Challenge, one of the associated challenges of NTIRE 2026. The challenge aims to recover high-resolution (HR) infrared images from low-resolution (LR) inputs generated through bicubic downsampling with a x4 scaling factor. The objective is to develop effective models or solutions that achieve state-of-the-art performance for infrared image SR in remote sensing scenarios. To reflect the characteristics of infrared data and practical application needs, the challenge adopts a single-track setting. A total of 115 participants registered for the competition, with 13 teams submitting valid entries. This report summarizes the challenge design, dataset, evaluation protocol, main results, and the representative methods of each team. The challenge serves as a benchmark to advance research in infrared image super-resolution and promote the development of effective solutions for real-world remote sensing applications.
The Fourth Challenge on Image Super-Resolution ($\times$4) at NTIRE 2026: Benchmark Results and Method Overview
Apr 16, 2026This paper presents the NTIRE 2026 image super-resolution ($\times$4) challenge, one of the associated competitions of the NTIRE 2026 Workshop at CVPR 2026. The challenge aims to reconstruct high-resolution (HR) images from low-resolution (LR) inputs generated through bicubic downsampling with a $\times$4 scaling factor. The objective is to develop effective super-resolution solutions and analyze recent advances in the field. To reflect the evolving objectives of image super-resolution, the challenge includes two tracks: (1) a restoration track, which emphasizes pixel-wise fidelity and ranks submissions based on PSNR; and (2) a perceptual track, which focuses on visual realism and evaluates results using a perceptual score. A total of 194 participants registered for the challenge, with 31 teams submitting valid entries. This report summarizes the challenge design, datasets, evaluation protocol, main results, and methods of participating teams. The challenge provides a unified benchmark and offers insights into current progress and future directions in image super-resolution.
FakeRadar: Probing Forgery Outliers to Detect Unknown Deepfake Videos
Dec 16, 2025In this paper, we propose FakeRadar, a novel deepfake video detection framework designed to address the challenges of cross-domain generalization in real-world scenarios. Existing detection methods typically rely on manipulation-specific cues, performing well on known forgery types but exhibiting severe limitations against emerging manipulation techniques. This poor generalization stems from their inability to adapt effectively to unseen forgery patterns. To overcome this, we leverage large-scale pretrained models (e.g. CLIP) to proactively probe the feature space, explicitly highlighting distributional gaps between real videos, known forgeries, and unseen manipulations. Specifically, FakeRadar introduces Forgery Outlier Probing, which employs dynamic subcluster modeling and cluster-conditional outlier generation to synthesize outlier samples near boundaries of estimated subclusters, simulating novel forgery artifacts beyond known manipulation types. Additionally, we design Outlier-Guided Tri-Training, which optimizes the detector to distinguish real, fake, and outlier samples using proposed outlier-driven contrastive learning and outlier-conditioned cross-entropy losses. Experiments show that FakeRadar outperforms existing methods across various benchmark datasets for deepfake video detection, particularly in cross-domain evaluations, by handling the variety of emerging manipulation techniques.
Bridging Knowledge Gap Between Image Inpainting and Large-Area Visible Watermark Removal
Apr 07, 2025Visible watermark removal which involves watermark cleaning and background content restoration is pivotal to evaluate the resilience of watermarks. Existing deep neural network (DNN)-based models still struggle with large-area watermarks and are overly dependent on the quality of watermark mask prediction. To overcome these challenges, we introduce a novel feature adapting framework that leverages the representation modeling capacity of a pre-trained image inpainting model. Our approach bridges the knowledge gap between image inpainting and watermark removal by fusing information of the residual background content beneath watermarks into the inpainting backbone model. We establish a dual-branch system to capture and embed features from the residual background content, which are merged into intermediate features of the inpainting backbone model via gated feature fusion modules. Moreover, for relieving the dependence on high-quality watermark masks, we introduce a new training paradigm by utilizing coarse watermark masks to guide the inference process. This contributes to a visible image removal model which is insensitive to the quality of watermark mask during testing. Extensive experiments on both a large-scale synthesized dataset and a real-world dataset demonstrate that our approach significantly outperforms existing state-of-the-art methods. The source code is available in the supplementary materials.
Variance-insensitive and Target-preserving Mask Refinement for Interactive Image Segmentation
Dec 22, 2023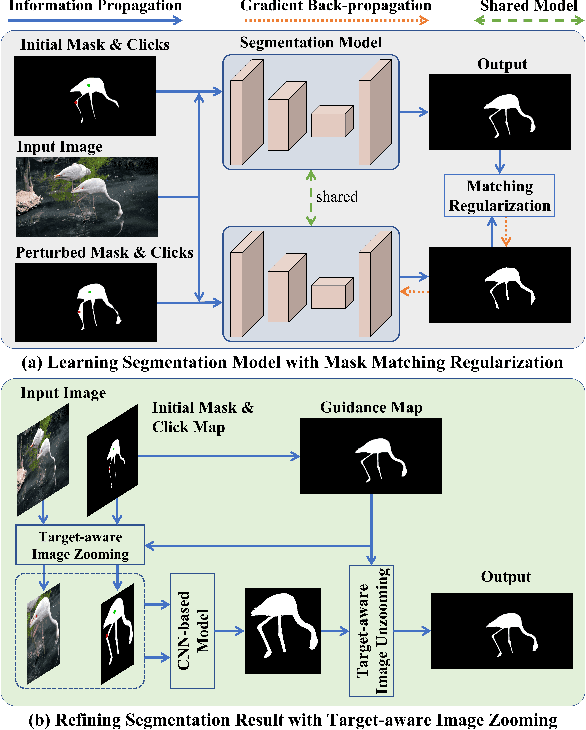
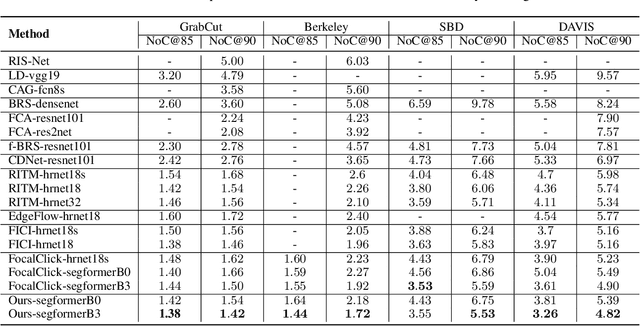

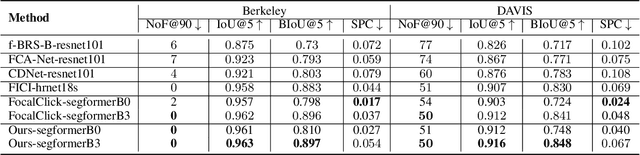
Point-based interactive image segmentation can ease the burden of mask annotation in applications such as semantic segmentation and image editing. However, fully extracting the target mask with limited user inputs remains challenging. We introduce a novel method, Variance-Insensitive and Target-Preserving Mask Refinement to enhance segmentation quality with fewer user inputs. Regarding the last segmentation result as the initial mask, an iterative refinement process is commonly employed to continually enhance the initial mask. Nevertheless, conventional techniques suffer from sensitivity to the variance in the initial mask. To circumvent this problem, our proposed method incorporates a mask matching algorithm for ensuring consistent inferences from different types of initial masks. We also introduce a target-aware zooming algorithm to preserve object information during downsampling, balancing efficiency and accuracy. Experiments on GrabCut, Berkeley, SBD, and DAVIS datasets demonstrate our method's state-of-the-art performance in interactive image segmentation.
Samplable Anonymous Aggregation for Private Federated Data Analysis
Jul 27, 2023We revisit the problem of designing scalable protocols for private statistics and private federated learning when each device holds its private data. Our first contribution is to propose a simple primitive that allows for efficient implementation of several commonly used algorithms, and allows for privacy accounting that is close to that in the central setting without requiring the strong trust assumptions it entails. Second, we propose a system architecture that implements this primitive and perform a security analysis of the proposed system.
Differentially Private Heavy Hitter Detection using Federated Analytics
Jul 21, 2023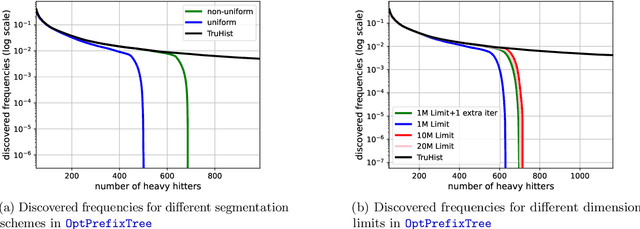
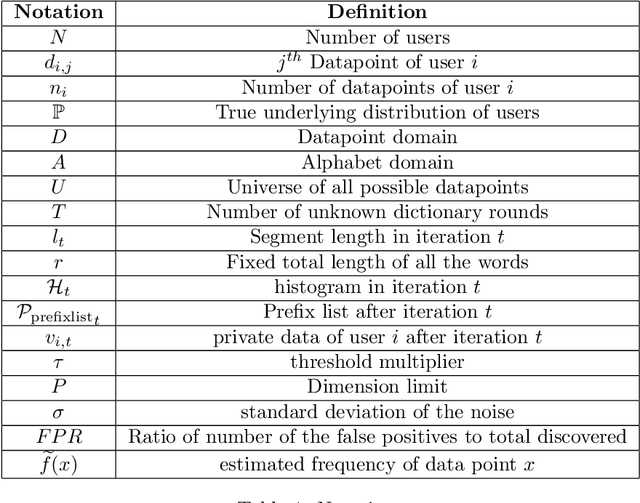
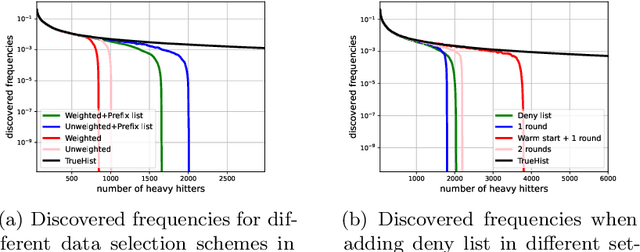

In this work, we study practical heuristics to improve the performance of prefix-tree based algorithms for differentially private heavy hitter detection. Our model assumes each user has multiple data points and the goal is to learn as many of the most frequent data points as possible across all users' data with aggregate and local differential privacy. We propose an adaptive hyperparameter tuning algorithm that improves the performance of the algorithm while satisfying computational, communication and privacy constraints. We explore the impact of different data-selection schemes as well as the impact of introducing deny lists during multiple runs of the algorithm. We test these improvements using extensive experimentation on the Reddit dataset~\cite{caldas2018leaf} on the task of learning the most frequent words.
A Cooperative Positioning Flamework for Robot and Smart Phone Based on Visible Light Communication
Aug 25, 2022A cooperative positioning flamework of human and robots based on visible light communication (VLC) is proposed. Based on the experiment system, we demonstrated it has high accuracy and real-time performance.