 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSamplable Anonymous Aggregation for Private Federated Data Analysis
Jul 27, 2023We revisit the problem of designing scalable protocols for private statistics and private federated learning when each device holds its private data. Our first contribution is to propose a simple primitive that allows for efficient implementation of several commonly used algorithms, and allows for privacy accounting that is close to that in the central setting without requiring the strong trust assumptions it entails. Second, we propose a system architecture that implements this primitive and perform a security analysis of the proposed system.
Differentially Private Heavy Hitter Detection using Federated Analytics
Jul 21, 2023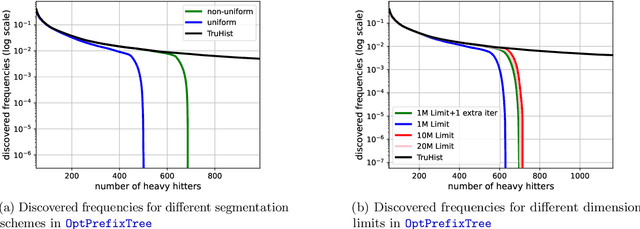
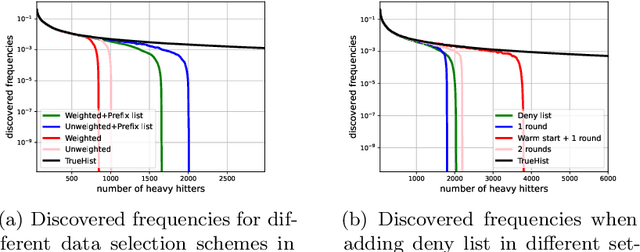

In this work, we study practical heuristics to improve the performance of prefix-tree based algorithms for differentially private heavy hitter detection. Our model assumes each user has multiple data points and the goal is to learn as many of the most frequent data points as possible across all users' data with aggregate and local differential privacy. We propose an adaptive hyperparameter tuning algorithm that improves the performance of the algorithm while satisfying computational, communication and privacy constraints. We explore the impact of different data-selection schemes as well as the impact of introducing deny lists during multiple runs of the algorithm. We test these improvements using extensive experimentation on the Reddit dataset~\cite{caldas2018leaf} on the task of learning the most frequent words.
Private Adaptive Gradient Methods for Convex Optimization
Jun 25, 2021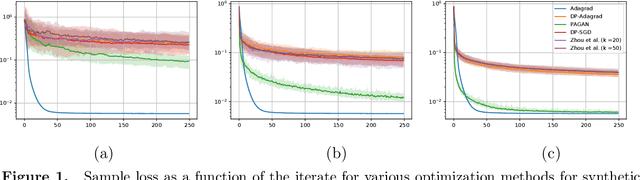

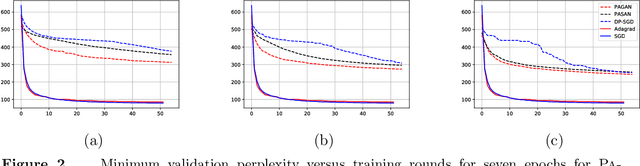
We study adaptive methods for differentially private convex optimization, proposing and analyzing differentially private variants of a Stochastic Gradient Descent (SGD) algorithm with adaptive stepsizes, as well as the AdaGrad algorithm. We provide upper bounds on the regret of both algorithms and show that the bounds are (worst-case) optimal. As a consequence of our development, we show that our private versions of AdaGrad outperform adaptive SGD, which in turn outperforms traditional SGD in scenarios with non-isotropic gradients where (non-private) Adagrad provably outperforms SGD. The major challenge is that the isotropic noise typically added for privacy dominates the signal in gradient geometry for high-dimensional problems; approaches to this that effectively optimize over lower-dimensional subspaces simply ignore the actual problems that varying gradient geometries introduce. In contrast, we study non-isotropic clipping and noise addition, developing a principled theoretical approach; the consequent procedures also enjoy significantly stronger empirical performance than prior approaches.
Federated Evaluation and Tuning for On-Device Personalization: System Design & Applications
Feb 16, 2021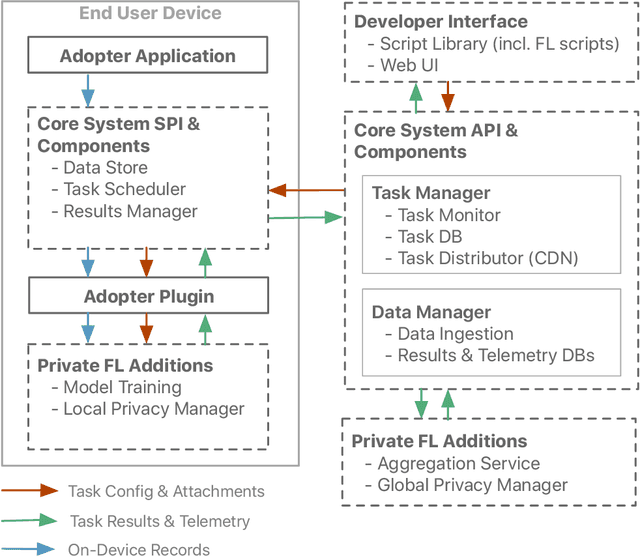
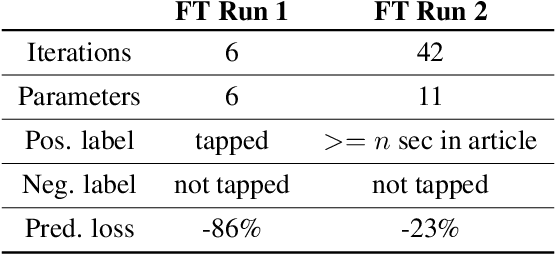

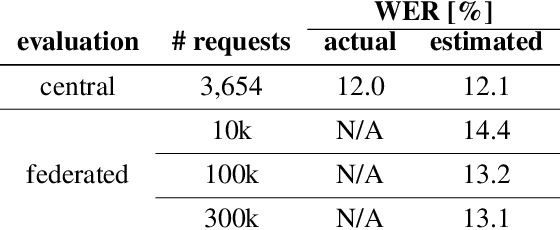
We describe the design of our federated task processing system. Originally, the system was created to support two specific federated tasks: evaluation and tuning of on-device ML systems, primarily for the purpose of personalizing these systems. In recent years, support for an additional federated task has been added: federated learning (FL) of deep neural networks. To our knowledge, only one other system has been described in literature that supports FL at scale. We include comparisons to that system to help discuss design decisions and attached trade-offs. Finally, we describe two specific large scale personalization use cases in detail to showcase the applicability of federated tuning to on-device personalization and to highlight application specific solutions.
Element Level Differential Privacy: The Right Granularity of Privacy
Dec 05, 2019
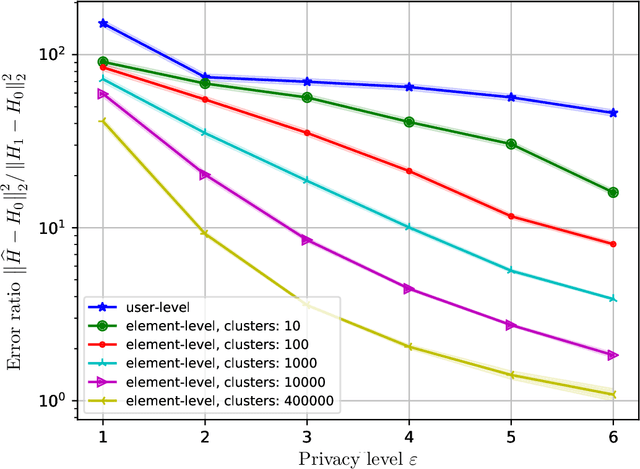
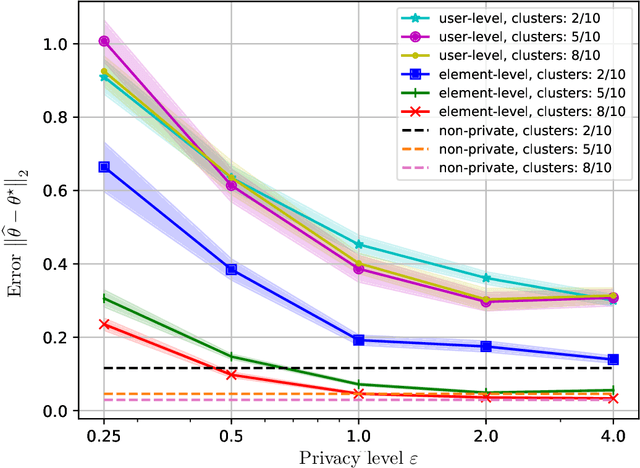
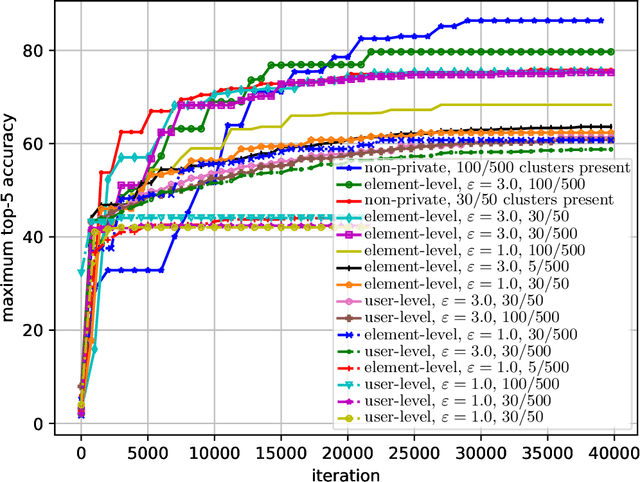
Differential Privacy (DP) provides strong guarantees on the risk of compromising a user's data in statistical learning applications, though these strong protections make learning challenging and may be too stringent for some use cases. To address this, we propose element level differential privacy, which extends differential privacy to provide protection against leaking information about any particular "element" a user has, allowing better utility and more robust results than classical DP. By carefully choosing these "elements," it is possible to provide privacy protections at a desired granularity. We provide definitions, associated privacy guarantees, and analysis to identify the tradeoffs with the new definition; we also develop several private estimation and learning methodologies, providing careful examples for item frequency and M-estimation (empirical risk minimization) with concomitant privacy and utility analysis. We complement our theoretical and methodological advances with several real-world applications, estimating histograms and fitting several large-scale prediction models, including deep networks.