 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Machine Interpreting: Lessons from Human Interpreting Studies
Aug 11, 2025Current speech translation systems, while having achieved impressive accuracies, are rather static in their behavior and do not adapt to real-world situations in ways human interpreters do. In order to improve their practical usefulness and enable interpreting-like experiences, a precise understanding of the nature of human interpreting is crucial. To this end, we discuss human interpreting literature from the perspective of the machine translation field, while considering both operational and qualitative aspects. We identify implications for the development of speech translation systems and argue that there is great potential to adopt many human interpreting principles using recent modeling techniques. We hope that our findings provide inspiration for closing the perceived usability gap, and can motivate progress toward true machine interpreting.
Generating Gender Alternatives in Machine Translation
Jul 29, 2024



Machine translation (MT) systems often translate terms with ambiguous gender (e.g., English term "the nurse") into the gendered form that is most prevalent in the systems' training data (e.g., "enfermera", the Spanish term for a female nurse). This often reflects and perpetuates harmful stereotypes present in society. With MT user interfaces in mind that allow for resolving gender ambiguity in a frictionless manner, we study the problem of generating all grammatically correct gendered translation alternatives. We open source train and test datasets for five language pairs and establish benchmarks for this task. Our key technical contribution is a novel semi-supervised solution for generating alternatives that integrates seamlessly with standard MT models and maintains high performance without requiring additional components or increasing inference overhead.
End-to-End Speech Translation for Code Switched Speech
Apr 11, 2022

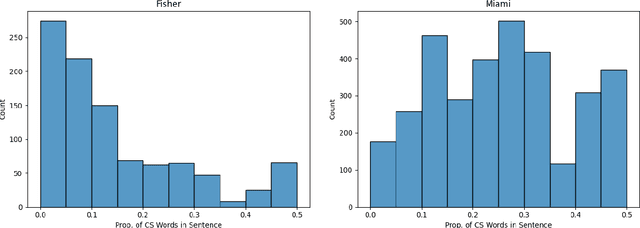
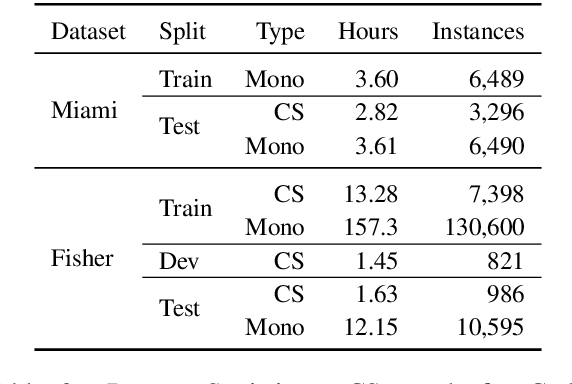
Code switching (CS) refers to the phenomenon of interchangeably using words and phrases from different languages. CS can pose significant accuracy challenges to NLP, due to the often monolingual nature of the underlying systems. In this work, we focus on CS in the context of English/Spanish conversations for the task of speech translation (ST), generating and evaluating both transcript and translation. To evaluate model performance on this task, we create a novel ST corpus derived from existing public data sets. We explore various ST architectures across two dimensions: cascaded (transcribe then translate) vs end-to-end (jointly transcribe and translate) and unidirectional (source -> target) vs bidirectional (source <-> target). We show that our ST architectures, and especially our bidirectional end-to-end architecture, perform well on CS speech, even when no CS training data is used.
Federated Evaluation and Tuning for On-Device Personalization: System Design & Applications
Feb 16, 2021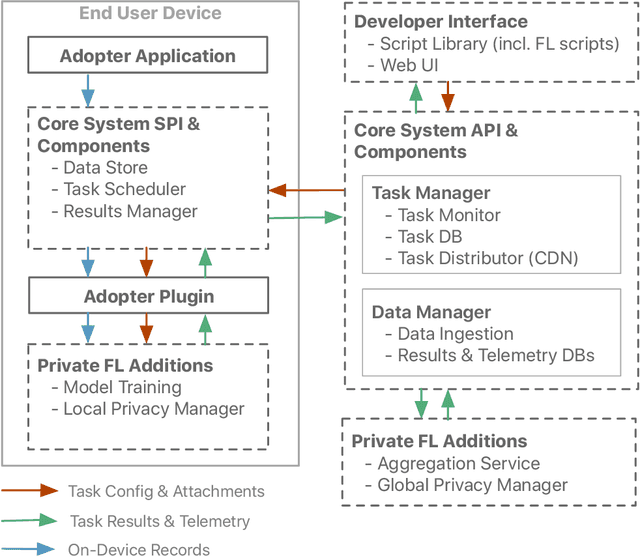
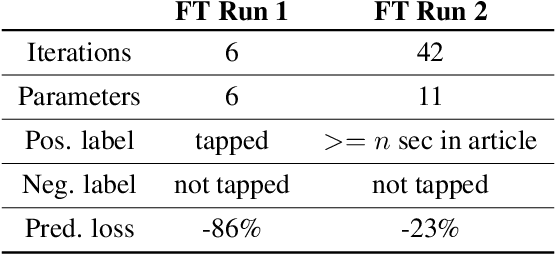

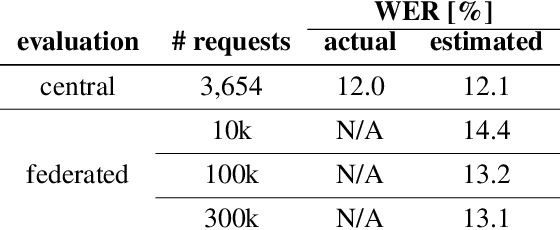
We describe the design of our federated task processing system. Originally, the system was created to support two specific federated tasks: evaluation and tuning of on-device ML systems, primarily for the purpose of personalizing these systems. In recent years, support for an additional federated task has been added: federated learning (FL) of deep neural networks. To our knowledge, only one other system has been described in literature that supports FL at scale. We include comparisons to that system to help discuss design decisions and attached trade-offs. Finally, we describe two specific large scale personalization use cases in detail to showcase the applicability of federated tuning to on-device personalization and to highlight application specific solutions.
Consistent Transcription and Translation of Speech
Aug 28, 2020
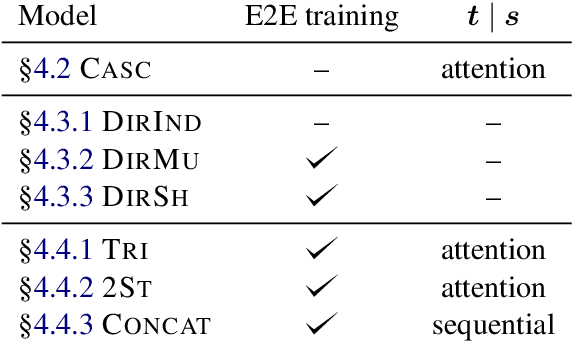

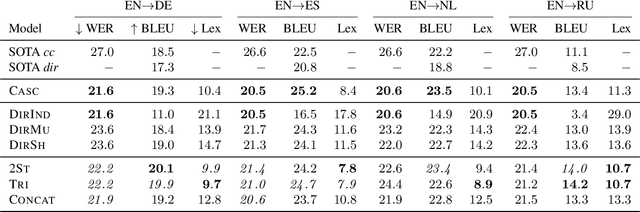
The conventional paradigm in speech translation starts with a speech recognition step to generate transcripts, followed by a translation step with the automatic transcripts as input. To address various shortcomings of this paradigm, recent work explores end-to-end trainable direct models that translate without transcribing. However, transcripts can be an indispensable output in practical applications, which often display transcripts alongside the translations to users. We make this common requirement explicit and explore the task of jointly transcribing and translating speech. While high accuracy of transcript and translation are crucial, even highly accurate systems can suffer from inconsistencies between both outputs that degrade the user experience. We introduce a methodology to evaluate consistency and compare several modeling approaches, including the traditional cascaded approach and end-to-end models. We find that direct models are poorly suited to the joint transcription/translation task, but that end-to-end models that feature a coupled inference procedure are able to achieve strong consistency. We further introduce simple techniques for directly optimizing for consistency, and analyze the resulting trade-offs between consistency, transcription accuracy, and translation accuracy.
Improving on-device speaker verification using federated learning with privacy
Aug 06, 2020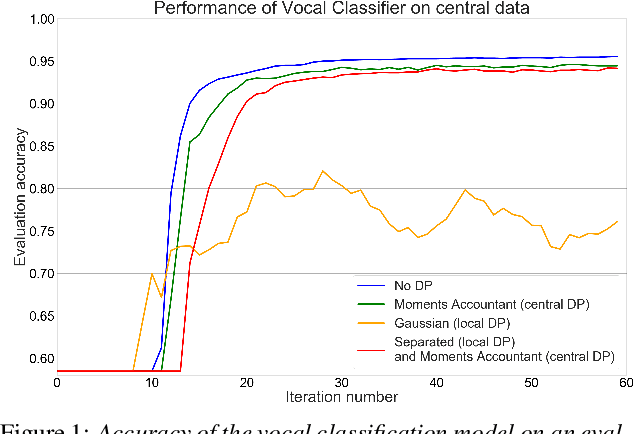

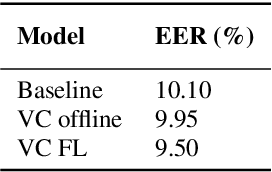
Information on speaker characteristics can be useful as side information in improving speaker recognition accuracy. However, such information is often private. This paper investigates how privacy-preserving learning can improve a speaker verification system, by enabling the use of privacy-sensitive speaker data to train an auxiliary classification model that predicts vocal characteristics of speakers. In particular, this paper explores the utility achieved by approaches which combine different federated learning and differential privacy mechanisms. These approaches make it possible to train a central model while protecting user privacy, with users' data remaining on their devices. Furthermore, they make learning on a large population of speakers possible, ensuring good coverage of speaker characteristics when training a model. The auxiliary model described here uses features extracted from phrases which trigger a speaker verification system. From these features, the model predicts speaker characteristic labels considered useful as side information. The knowledge of the auxiliary model is distilled into a speaker verification system using multi-task learning, with the side information labels predicted by this auxiliary model being the additional task. This approach results in a 6% relative improvement in equal error rate over a baseline system.
Variational Neural Machine Translation with Normalizing Flows
May 28, 2020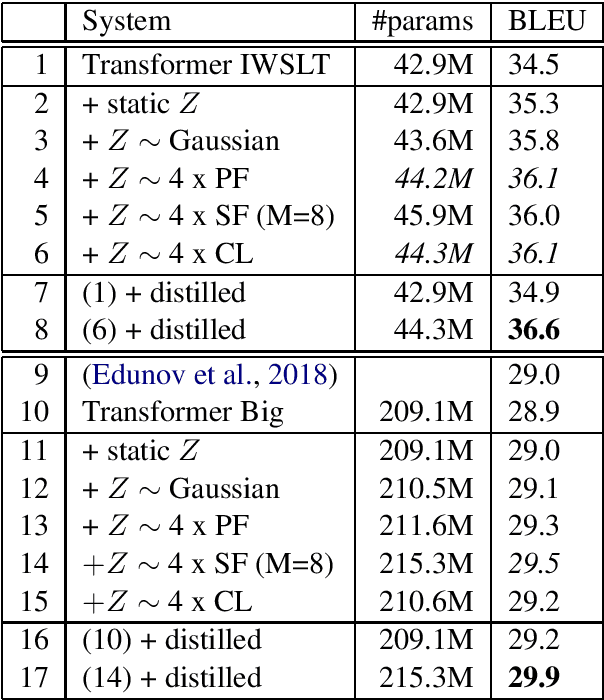

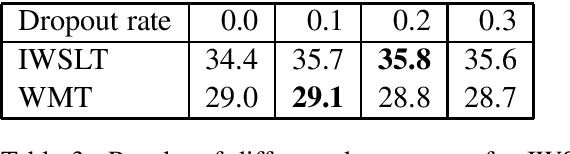

Variational Neural Machine Translation (VNMT) is an attractive framework for modeling the generation of target translations, conditioned not only on the source sentence but also on some latent random variables. The latent variable modeling may introduce useful statistical dependencies that can improve translation accuracy. Unfortunately, learning informative latent variables is non-trivial, as the latent space can be prohibitively large, and the latent codes are prone to be ignored by many translation models at training time. Previous works impose strong assumptions on the distribution of the latent code and limit the choice of the NMT architecture. In this paper, we propose to apply the VNMT framework to the state-of-the-art Transformer and introduce a more flexible approximate posterior based on normalizing flows. We demonstrate the efficacy of our proposal under both in-domain and out-of-domain conditions, significantly outperforming strong baselines.
Speech Translation and the End-to-End Promise: Taking Stock of Where We Are
Apr 14, 2020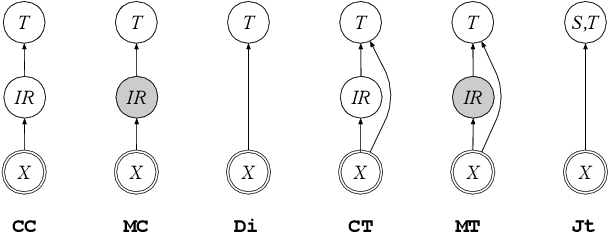


Over its three decade history, speech translation has experienced several shifts in its primary research themes; moving from loosely coupled cascades of speech recognition and machine translation, to exploring questions of tight coupling, and finally to end-to-end models that have recently attracted much attention. This paper provides a brief survey of these developments, along with a discussion of the main challenges of traditional approaches which stem from committing to intermediate representations from the speech recognizer, and from training cascaded models separately towards different objectives. Recent end-to-end modeling techniques promise a principled way of overcoming these issues by allowing joint training of all model components and removing the need for explicit intermediate representations. However, a closer look reveals that many end-to-end models fall short of solving these issues, due to compromises made to address data scarcity. This paper provides a unifying categorization and nomenclature that covers both traditional and recent approaches and that may help researchers by highlighting both trade-offs and open research questions.
Jointly Learning to Align and Translate with Transformer Models
Sep 04, 2019

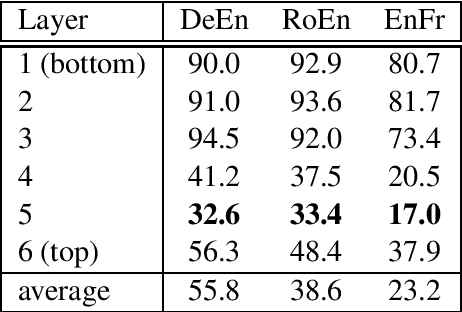
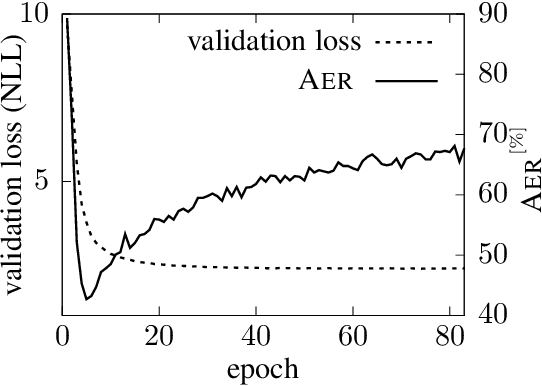
The state of the art in machine translation (MT) is governed by neural approaches, which typically provide superior translation accuracy over statistical approaches. However, on the closely related task of word alignment, traditional statistical word alignment models often remain the go-to solution. In this paper, we present an approach to train a Transformer model to produce both accurate translations and alignments. We extract discrete alignments from the attention probabilities learnt during regular neural machine translation model training and leverage them in a multi-task framework to optimize towards translation and alignment objectives. We demonstrate that our approach produces competitive results compared to GIZA++ trained IBM alignment models without sacrificing translation accuracy and outperforms previous attempts on Transformer model based word alignment. Finally, by incorporating IBM model alignments into our multi-task training, we report significantly better alignment accuracies compared to GIZA++ on three publicly available data sets.