 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLarge-scale Training of Foundation Models for Wearable Biosignals
Dec 08, 2023



Tracking biosignals is crucial for monitoring wellness and preempting the development of severe medical conditions. Today, wearable devices can conveniently record various biosignals, creating the opportunity to monitor health status without disruption to one's daily routine. Despite widespread use of wearable devices and existing digital biomarkers, the absence of curated data with annotated medical labels hinders the development of new biomarkers to measure common health conditions. In fact, medical datasets are usually small in comparison to other domains, which is an obstacle for developing neural network models for biosignals. To address this challenge, we have employed self-supervised learning using the unlabeled sensor data collected under informed consent from the large longitudinal Apple Heart and Movement Study (AHMS) to train foundation models for two common biosignals: photoplethysmography (PPG) and electrocardiogram (ECG) recorded on Apple Watch. We curated PPG and ECG datasets from AHMS that include data from ~141K participants spanning ~3 years. Our self-supervised learning framework includes participant level positive pair selection, stochastic augmentation module and a regularized contrastive loss optimized with momentum training, and generalizes well to both PPG and ECG modalities. We show that the pre-trained foundation models readily encode information regarding participants' demographics and health conditions. To the best of our knowledge, this is the first study that builds foundation models using large-scale PPG and ECG data collected via wearable consumer devices $\unicode{x2013}$ prior works have commonly used smaller-size datasets collected in clinical and experimental settings. We believe PPG and ECG foundation models can enhance future wearable devices by reducing the reliance on labeled data and hold the potential to help the users improve their health.
Consistent Transcription and Translation of Speech
Aug 28, 2020
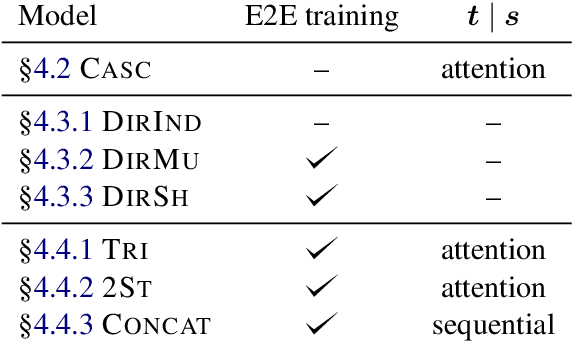

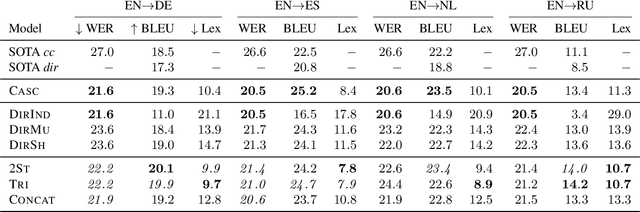
The conventional paradigm in speech translation starts with a speech recognition step to generate transcripts, followed by a translation step with the automatic transcripts as input. To address various shortcomings of this paradigm, recent work explores end-to-end trainable direct models that translate without transcribing. However, transcripts can be an indispensable output in practical applications, which often display transcripts alongside the translations to users. We make this common requirement explicit and explore the task of jointly transcribing and translating speech. While high accuracy of transcript and translation are crucial, even highly accurate systems can suffer from inconsistencies between both outputs that degrade the user experience. We introduce a methodology to evaluate consistency and compare several modeling approaches, including the traditional cascaded approach and end-to-end models. We find that direct models are poorly suited to the joint transcription/translation task, but that end-to-end models that feature a coupled inference procedure are able to achieve strong consistency. We further introduce simple techniques for directly optimizing for consistency, and analyze the resulting trade-offs between consistency, transcription accuracy, and translation accuracy.
Jointly Learning to Align and Translate with Transformer Models
Sep 04, 2019

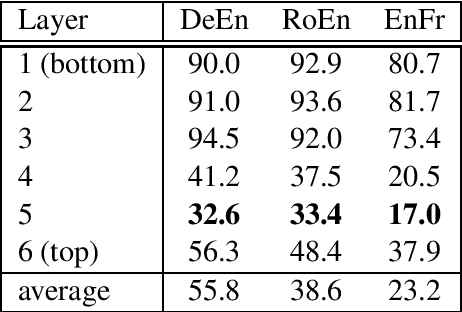
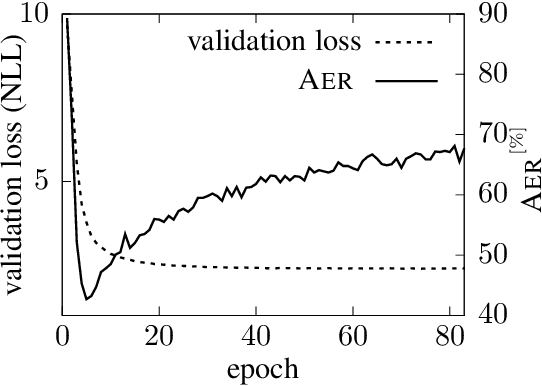
The state of the art in machine translation (MT) is governed by neural approaches, which typically provide superior translation accuracy over statistical approaches. However, on the closely related task of word alignment, traditional statistical word alignment models often remain the go-to solution. In this paper, we present an approach to train a Transformer model to produce both accurate translations and alignments. We extract discrete alignments from the attention probabilities learnt during regular neural machine translation model training and leverage them in a multi-task framework to optimize towards translation and alignment objectives. We demonstrate that our approach produces competitive results compared to GIZA++ trained IBM alignment models without sacrificing translation accuracy and outperforms previous attempts on Transformer model based word alignment. Finally, by incorporating IBM model alignments into our multi-task training, we report significantly better alignment accuracies compared to GIZA++ on three publicly available data sets.