 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeButterflyQuant: Ultra-low-bit LLM Quantization through Learnable Orthogonal Butterfly Transforms
Sep 11, 2025Large language models require massive memory footprints, severely limiting deployment on consumer hardware. Quantization reduces memory through lower numerical precision, but extreme 2-bit quantization suffers from catastrophic performance loss due to outliers in activations. Rotation-based methods such as QuIP and QuaRot apply orthogonal transforms to eliminate outliers before quantization, using computational invariance: $\mathbf{y} = \mathbf{Wx} = (\mathbf{WQ}^T)(\mathbf{Qx})$ for orthogonal $\mathbf{Q}$. However, these methods use fixed transforms--Hadamard matrices achieving optimal worst-case coherence $\mu = 1/\sqrt{n}$--that cannot adapt to specific weight distributions. We identify that different transformer layers exhibit distinct outlier patterns, motivating layer-adaptive rotations rather than one-size-fits-all approaches. We propose ButterflyQuant, which replaces Hadamard rotations with learnable butterfly transforms parameterized by continuous Givens rotation angles. Unlike Hadamard's discrete $\{+1, -1\}$ entries that are non-differentiable and prohibit gradient-based learning, butterfly transforms' continuous parameterization enables smooth optimization while guaranteeing orthogonality by construction. This orthogonal constraint ensures theoretical guarantees in outlier suppression while achieving $O(n \log n)$ computational complexity with only $\frac{n \log n}{2}$ learnable parameters. We further introduce a uniformity regularization on post-transformation activations to promote smoother distributions amenable to quantization. Learning requires only 128 calibration samples and converges in minutes on a single GPU--a negligible one-time cost. On LLaMA-2-7B with 2-bit quantization, ButterflyQuant achieves 15.4 perplexity versus 22.1 for QuaRot.
MARVIS: Modality Adaptive Reasoning over VISualizations
Jul 02, 2025Scientific applications of machine learning often rely on small, specialized models tuned to particular domains. Such models often achieve excellent performance, but lack flexibility. Foundation models offer versatility, but typically underperform specialized approaches, especially on non-traditional modalities and long-tail domains. We propose MARVIS (Modality Adaptive Reasoning over VISualizations), a training-free method that enables even small vision-language models to predict any data modality with high accuracy. MARVIS transforms latent embedding spaces into visual representations and then leverages the spatial and fine-grained reasoning skills of VLMs to successfully interpret and utilize them. MARVIS achieves competitive performance on vision, audio, biological, and tabular domains using a single 3B parameter model, achieving results that beat Gemini by 16\% on average and approach specialized methods, without exposing personally identifiable information (P.I.I.) or requiring any domain-specific training. We open source our code and datasets at https://github.com/penfever/marvis
Can a Single Model Master Both Multi-turn Conversations and Tool Use? CALM: A Unified Conversational Agentic Language Model
Feb 12, 2025



Large Language Models (LLMs) with API-calling capabilities enabled building effective Language Agents (LA), while also revolutionizing the conventional task-oriented dialogue (TOD) paradigm. However, current approaches face a critical dilemma: TOD systems are often trained on a limited set of target APIs, requiring new data to maintain their quality when interfacing with new services, while LAs are not trained to maintain user intent over multi-turn conversations. Because both robust multi-turn management and advanced function calling are crucial for effective conversational agents, we evaluate these skills on three popular benchmarks: MultiWOZ 2.4 (TOD), BFCL V3 (LA), and API-Bank (LA), and our analyses reveal that specialized approaches excel in one domain but underperform in the other. To bridge this chasm, we introduce CALM (Conversational Agentic Language Model), a unified approach that integrates both conversational and agentic capabilities. We created CALM-IT, a carefully constructed multi-task dataset that interleave multi-turn ReAct reasoning with complex API usage. Using CALM-IT, we train three models CALM 8B, CALM 70B, and CALM 405B, which outperform top domain-specific models, including GPT-4o, across all three benchmarks.
Do LLMs "know" internally when they follow instructions?
Oct 22, 2024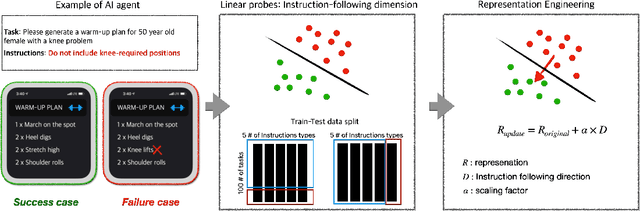


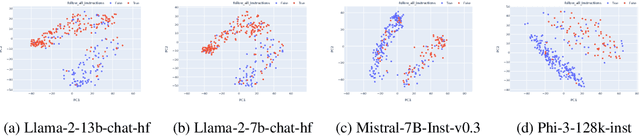
Instruction-following is crucial for building AI agents with large language models (LLMs), as these models must adhere strictly to user-provided constraints and guidelines. However, LLMs often fail to follow even simple and clear instructions. To improve instruction-following behavior and prevent undesirable outputs, a deeper understanding of how LLMs' internal states relate to these outcomes is required. Our analysis of LLM internal states reveal a dimension in the input embedding space linked to successful instruction-following. We demonstrate that modifying representations along this dimension improves instruction-following success rates compared to random changes, without compromising response quality. Further investigation reveals that this dimension is more closely related to the phrasing of prompts rather than the inherent difficulty of the task or instructions. This discovery also suggests explanations for why LLMs sometimes fail to follow clear instructions and why prompt engineering is often effective, even when the content remains largely unchanged. This work provides insight into the internal workings of LLMs' instruction-following, paving the way for reliable LLM agents.
Large-scale Training of Foundation Models for Wearable Biosignals
Dec 08, 2023



Tracking biosignals is crucial for monitoring wellness and preempting the development of severe medical conditions. Today, wearable devices can conveniently record various biosignals, creating the opportunity to monitor health status without disruption to one's daily routine. Despite widespread use of wearable devices and existing digital biomarkers, the absence of curated data with annotated medical labels hinders the development of new biomarkers to measure common health conditions. In fact, medical datasets are usually small in comparison to other domains, which is an obstacle for developing neural network models for biosignals. To address this challenge, we have employed self-supervised learning using the unlabeled sensor data collected under informed consent from the large longitudinal Apple Heart and Movement Study (AHMS) to train foundation models for two common biosignals: photoplethysmography (PPG) and electrocardiogram (ECG) recorded on Apple Watch. We curated PPG and ECG datasets from AHMS that include data from ~141K participants spanning ~3 years. Our self-supervised learning framework includes participant level positive pair selection, stochastic augmentation module and a regularized contrastive loss optimized with momentum training, and generalizes well to both PPG and ECG modalities. We show that the pre-trained foundation models readily encode information regarding participants' demographics and health conditions. To the best of our knowledge, this is the first study that builds foundation models using large-scale PPG and ECG data collected via wearable consumer devices $\unicode{x2013}$ prior works have commonly used smaller-size datasets collected in clinical and experimental settings. We believe PPG and ECG foundation models can enhance future wearable devices by reducing the reliance on labeled data and hold the potential to help the users improve their health.
Contextual Text Style Transfer
Apr 30, 2020

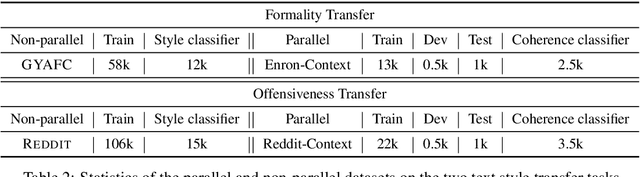

We introduce a new task, Contextual Text Style Transfer - translating a sentence into a desired style with its surrounding context taken into account. This brings two key challenges to existing style transfer approaches: ($i$) how to preserve the semantic meaning of target sentence and its consistency with surrounding context during transfer; ($ii$) how to train a robust model with limited labeled data accompanied with context. To realize high-quality style transfer with natural context preservation, we propose a Context-Aware Style Transfer (CAST) model, which uses two separate encoders for each input sentence and its surrounding context. A classifier is further trained to ensure contextual consistency of the generated sentence. To compensate for the lack of parallel data, additional self-reconstruction and back-translation losses are introduced to leverage non-parallel data in a semi-supervised fashion. Two new benchmarks, Enron-Context and Reddit-Context, are introduced for formality and offensiveness style transfer. Experimental results on these datasets demonstrate the effectiveness of the proposed CAST model over state-of-the-art methods across style accuracy, content preservation and contextual consistency metrics.
INSET: Sentence Infilling with Inter-sentential Generative Pre-training
Nov 10, 2019

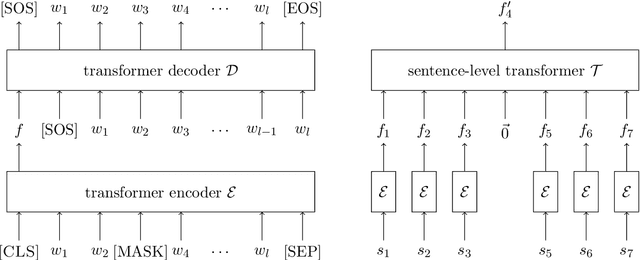
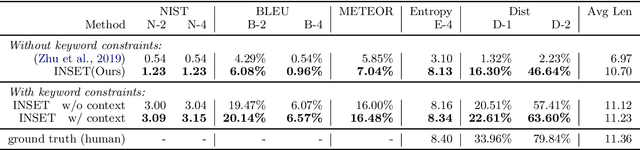
Missing sentence generation (or sentence infilling) fosters a wide range of applications in natural language generation, such as document auto-completion and meeting note expansion. Such a task asks the model to generate intermediate missing sentence that can semantically and syntactically bridge the surrounding context. Solving the sentence infilling task requires techniques in NLP ranging from natural language understanding, discourse-level planning and natural language generation. In this paper, we present a framework to decouple this challenge and address these three aspects respectively, leveraging the power of existing large-scale pre-trained models such as BERT and GPT-2. Our empirical results demonstrate the effectiveness of our proposed model in learning a sentence representation for generation, and further generating a missing sentence that bridges the context.