 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDo LLMs "know" internally when they follow instructions?
Oct 22, 2024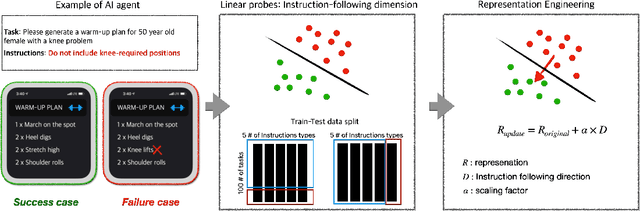


Instruction-following is crucial for building AI agents with large language models (LLMs), as these models must adhere strictly to user-provided constraints and guidelines. However, LLMs often fail to follow even simple and clear instructions. To improve instruction-following behavior and prevent undesirable outputs, a deeper understanding of how LLMs' internal states relate to these outcomes is required. Our analysis of LLM internal states reveal a dimension in the input embedding space linked to successful instruction-following. We demonstrate that modifying representations along this dimension improves instruction-following success rates compared to random changes, without compromising response quality. Further investigation reveals that this dimension is more closely related to the phrasing of prompts rather than the inherent difficulty of the task or instructions. This discovery also suggests explanations for why LLMs sometimes fail to follow clear instructions and why prompt engineering is often effective, even when the content remains largely unchanged. This work provides insight into the internal workings of LLMs' instruction-following, paving the way for reliable LLM agents.
Do LLMs estimate uncertainty well in instruction-following?
Oct 18, 2024
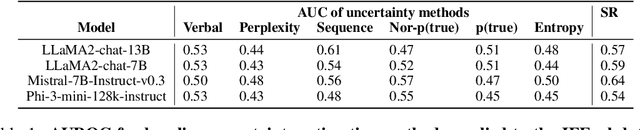
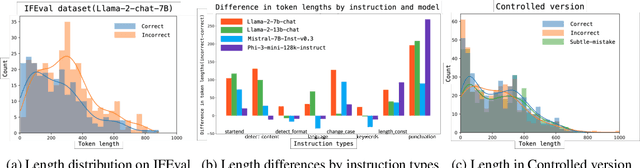

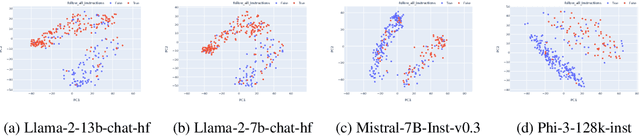
Large language models (LLMs) could be valuable personal AI agents across various domains, provided they can precisely follow user instructions. However, recent studies have shown significant limitations in LLMs' instruction-following capabilities, raising concerns about their reliability in high-stakes applications. Accurately estimating LLMs' uncertainty in adhering to instructions is critical to mitigating deployment risks. We present, to our knowledge, the first systematic evaluation of the uncertainty estimation abilities of LLMs in the context of instruction-following. Our study identifies key challenges with existing instruction-following benchmarks, where multiple factors are entangled with uncertainty stems from instruction-following, complicating the isolation and comparison across methods and models. To address these issues, we introduce a controlled evaluation setup with two benchmark versions of data, enabling a comprehensive comparison of uncertainty estimation methods under various conditions. Our findings show that existing uncertainty methods struggle, particularly when models make subtle errors in instruction following. While internal model states provide some improvement, they remain inadequate in more complex scenarios. The insights from our controlled evaluation setups provide a crucial understanding of LLMs' limitations and potential for uncertainty estimation in instruction-following tasks, paving the way for more trustworthy AI agents.
On Evaluating LLMs' Capabilities as Functional Approximators: A Bayesian Perspective
Oct 06, 2024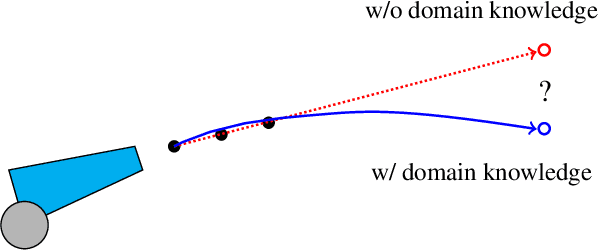


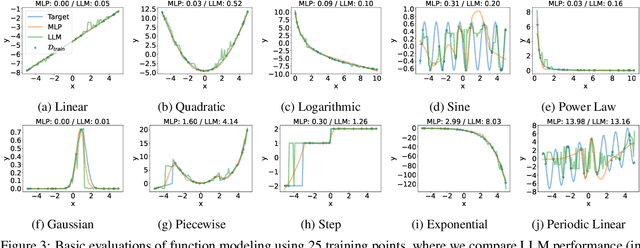
Recent works have successfully applied Large Language Models (LLMs) to function modeling tasks. However, the reasons behind this success remain unclear. In this work, we propose a new evaluation framework to comprehensively assess LLMs' function modeling abilities. By adopting a Bayesian perspective of function modeling, we discover that LLMs are relatively weak in understanding patterns in raw data, but excel at utilizing prior knowledge about the domain to develop a strong understanding of the underlying function. Our findings offer new insights about the strengths and limitations of LLMs in the context of function modeling.
Do Concept Bottleneck Models Obey Locality?
Jan 02, 2024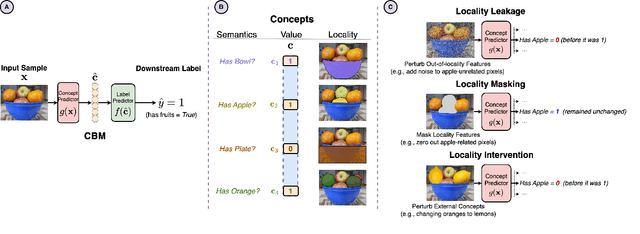
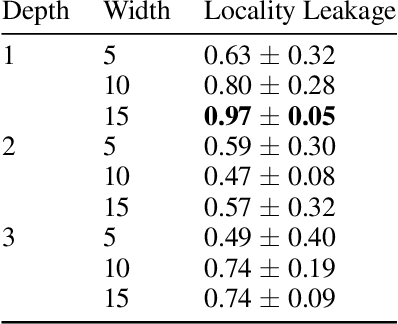
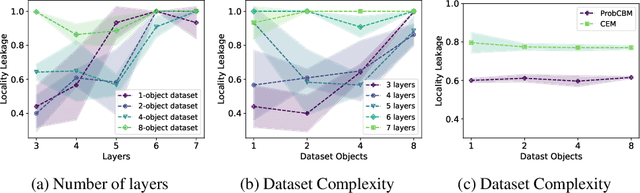
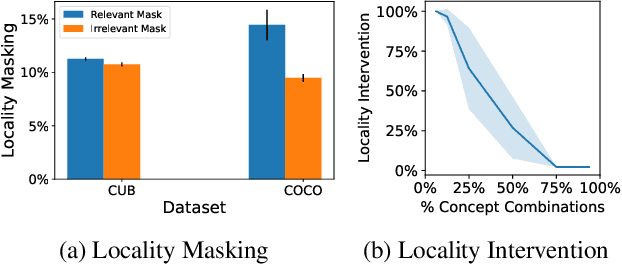
Concept-based learning improves a deep learning model's interpretability by explaining its predictions via human-understandable concepts. Deep learning models trained under this paradigm heavily rely on the assumption that neural networks can learn to predict the presence or absence of a given concept independently of other concepts. Recent work, however, strongly suggests that this assumption may fail to hold in Concept Bottleneck Models (CBMs), a quintessential family of concept-based interpretable architectures. In this paper, we investigate whether CBMs correctly capture the degree of conditional independence across concepts when such concepts are localised both spatially, by having their values entirely defined by a fixed subset of features, and semantically, by having their values correlated with only a fixed subset of predefined concepts. To understand locality, we analyse how changes to features outside of a concept's spatial or semantic locality impact concept predictions. Our results suggest that even in well-defined scenarios where the presence of a concept is localised to a fixed feature subspace, or whose semantics are correlated to a small subset of other concepts, CBMs fail to learn this locality. These results cast doubt upon the quality of concept representations learnt by CBMs and strongly suggest that concept-based explanations may be fragile to changes outside their localities.
Estimation of Concept Explanations Should be Uncertainty Aware
Dec 13, 2023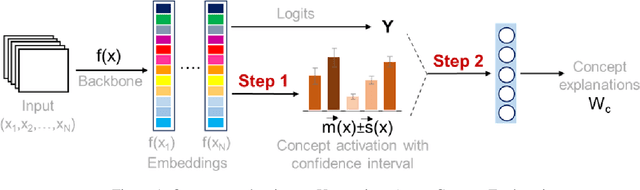
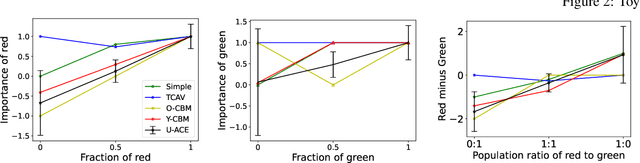
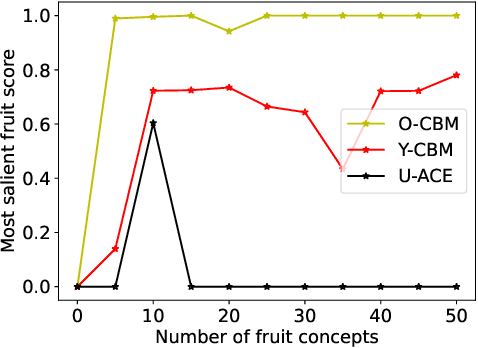

Model explanations are very valuable for interpreting and debugging prediction models. We study a specific kind of global explanations called Concept Explanations, where the goal is to interpret a model using human-understandable concepts. Recent advances in multi-modal learning rekindled interest in concept explanations and led to several label-efficient proposals for estimation. However, existing estimation methods are unstable to the choice of concepts or dataset that is used for computing explanations. We observe that instability in explanations is due to high variance in point estimation of importance scores. We propose an uncertainty aware Bayesian estimation method, which readily improved reliability of the concept explanations. We demonstrate with theoretical analysis and empirical evaluation that explanations computed by our method are more reliable while also being label-efficient and faithful.
Parameter-Efficient Orthogonal Finetuning via Butterfly Factorization
Nov 10, 2023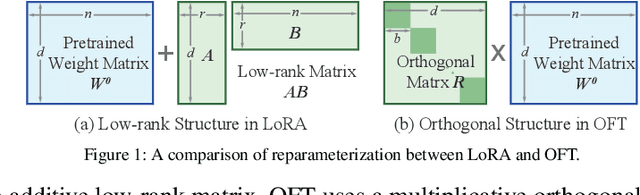
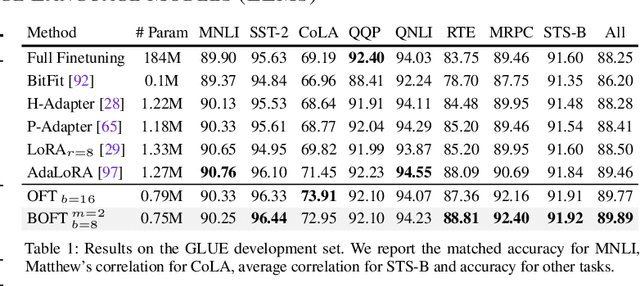
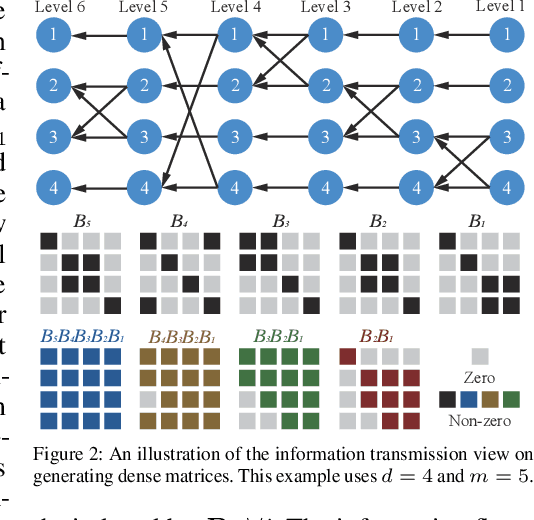
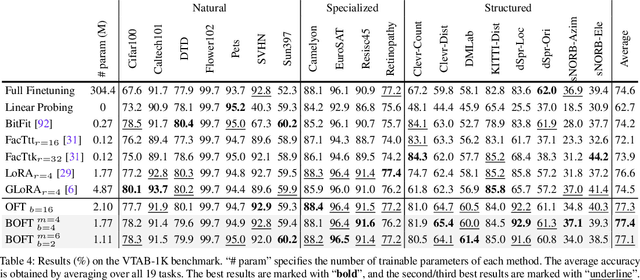
Large foundation models are becoming ubiquitous, but training them from scratch is prohibitively expensive. Thus, efficiently adapting these powerful models to downstream tasks is increasingly important. In this paper, we study a principled finetuning paradigm -- Orthogonal Finetuning (OFT) -- for downstream task adaptation. Despite demonstrating good generalizability, OFT still uses a fairly large number of trainable parameters due to the high dimensionality of orthogonal matrices. To address this, we start by examining OFT from an information transmission perspective, and then identify a few key desiderata that enable better parameter-efficiency. Inspired by how the Cooley-Tukey fast Fourier transform algorithm enables efficient information transmission, we propose an efficient orthogonal parameterization using butterfly structures. We apply this parameterization to OFT, creating a novel parameter-efficient finetuning method, called Orthogonal Butterfly (BOFT). By subsuming OFT as a special case, BOFT introduces a generalized orthogonal finetuning framework. Finally, we conduct an extensive empirical study of adapting large vision transformers, large language models, and text-to-image diffusion models to various downstream tasks in vision and language.
Leveraging Task Structures for Improved Identifiability in Neural Network Representations
Jun 26, 2023This work extends the theory of identifiability in supervised learning by considering the consequences of having access to a distribution of tasks. In such cases, we show that identifiability is achievable even in the case of regression, extending prior work restricted to the single-task classification case. Furthermore, we show that the existence of a task distribution which defines a conditional prior over latent variables reduces the equivalence class for identifiability to permutations and scaling, a much stronger and more useful result. When we further assume a causal structure over these tasks, our approach enables simple maximum marginal likelihood optimization together with downstream applicability to causal representation learning. Empirically, we validate that our model outperforms more general unsupervised models in recovering canonical representations for synthetic and real-world data.
Robust Learning from Explanations
Mar 11, 2023Machine learning from explanations (MLX) is an approach to learning that uses human-provided annotations of relevant features for each input to ensure that model predictions are right for the right reasons. Existing MLX approaches rely heavily on a specific model interpretation approach and require strong parameter regularization to align model and human explanations, leading to sub-optimal performance. We recast MLX as an adversarial robustness problem, where human explanations specify a lower dimensional manifold from which perturbations can be drawn, and show both theoretically and empirically how this approach alleviates the need for strong parameter regularization. We consider various approaches to achieving robustness, leading to improved performance over prior MLX methods. Finally, we combine robustness with an earlier MLX method, yielding state-of-the-art results on both synthetic and real-world benchmarks.
Robust Explanation Constraints for Neural Networks
Dec 16, 2022



Post-hoc explanation methods are used with the intent of providing insights about neural networks and are sometimes said to help engender trust in their outputs. However, popular explanations methods have been found to be fragile to minor perturbations of input features or model parameters. Relying on constraint relaxation techniques from non-convex optimization, we develop a method that upper-bounds the largest change an adversary can make to a gradient-based explanation via bounded manipulation of either the input features or model parameters. By propagating a compact input or parameter set as symbolic intervals through the forwards and backwards computations of the neural network we can formally certify the robustness of gradient-based explanations. Our bounds are differentiable, hence we can incorporate provable explanation robustness into neural network training. Empirically, our method surpasses the robustness provided by previous heuristic approaches. We find that our training method is the only method able to learn neural networks with certificates of explanation robustness across all six datasets tested.
Towards More Robust Interpretation via Local Gradient Alignment
Dec 07, 2022Neural network interpretation methods, particularly feature attribution methods, are known to be fragile with respect to adversarial input perturbations. To address this, several methods for enhancing the local smoothness of the gradient while training have been proposed for attaining \textit{robust} feature attributions. However, the lack of considering the normalization of the attributions, which is essential in their visualizations, has been an obstacle to understanding and improving the robustness of feature attribution methods. In this paper, we provide new insights by taking such normalization into account. First, we show that for every non-negative homogeneous neural network, a naive $\ell_2$-robust criterion for gradients is \textit{not} normalization invariant, which means that two functions with the same normalized gradient can have different values. Second, we formulate a normalization invariant cosine distance-based criterion and derive its upper bound, which gives insight for why simply minimizing the Hessian norm at the input, as has been done in previous work, is not sufficient for attaining robust feature attribution. Finally, we propose to combine both $\ell_2$ and cosine distance-based criteria as regularization terms to leverage the advantages of both in aligning the local gradient. As a result, we experimentally show that models trained with our method produce much more robust interpretations on CIFAR-10 and ImageNet-100 without significantly hurting the accuracy, compared to the recent baselines. To the best of our knowledge, this is the first work to verify the robustness of interpretation on a larger-scale dataset beyond CIFAR-10, thanks to the computational efficiency of our method.