 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSwiFT: Swin 4D fMRI Transformer
Jul 12, 2023



The modeling of spatiotemporal brain dynamics from high-dimensional data, such as 4D functional MRI, is a formidable task in neuroscience. To address this challenge, we present SwiFT (Swin 4D fMRI Transformer), a Swin Transformer architecture that can learn brain dynamics directly from 4D functional brain MRI data in a memory and computation-efficient manner. SwiFT achieves this by implementing a 4D window multi-head self-attention mechanism and absolute positional embeddings. We evaluate SwiFT using multiple largest-scale human functional brain imaging datasets in tasks such as predicting sex, age, and cognitive intelligence. Our experimental outcomes reveal that SwiFT consistently outperforms recent state-of-the-art models. To the best of our knowledge, SwiFT is the first Swin Transformer architecture that can process dimensional spatiotemporal brain functional data in an end-to-end fashion. Furthermore, due to the end-to-end learning capability, we also show that contrastive loss-based self-supervised pre-training of SwiFT is also feasible for achieving improved performance on a downstream task. We believe that our work holds substantial potential in facilitating scalable learning of functional brain imaging in neuroscience research by reducing the hurdles associated with applying Transformer models to high-dimensional fMRI.
Towards More Robust Interpretation via Local Gradient Alignment
Dec 07, 2022Neural network interpretation methods, particularly feature attribution methods, are known to be fragile with respect to adversarial input perturbations. To address this, several methods for enhancing the local smoothness of the gradient while training have been proposed for attaining \textit{robust} feature attributions. However, the lack of considering the normalization of the attributions, which is essential in their visualizations, has been an obstacle to understanding and improving the robustness of feature attribution methods. In this paper, we provide new insights by taking such normalization into account. First, we show that for every non-negative homogeneous neural network, a naive $\ell_2$-robust criterion for gradients is \textit{not} normalization invariant, which means that two functions with the same normalized gradient can have different values. Second, we formulate a normalization invariant cosine distance-based criterion and derive its upper bound, which gives insight for why simply minimizing the Hessian norm at the input, as has been done in previous work, is not sufficient for attaining robust feature attribution. Finally, we propose to combine both $\ell_2$ and cosine distance-based criteria as regularization terms to leverage the advantages of both in aligning the local gradient. As a result, we experimentally show that models trained with our method produce much more robust interpretations on CIFAR-10 and ImageNet-100 without significantly hurting the accuracy, compared to the recent baselines. To the best of our knowledge, this is the first work to verify the robustness of interpretation on a larger-scale dataset beyond CIFAR-10, thanks to the computational efficiency of our method.
DoPAMINE: Double-sided Masked CNN for Pixel Adaptive Multiplicative Noise Despeckling
Feb 07, 2019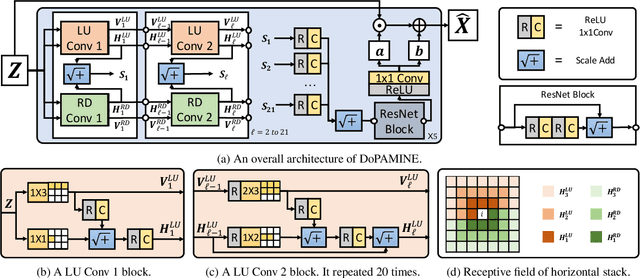
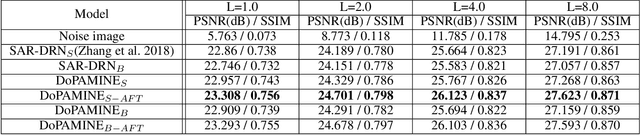

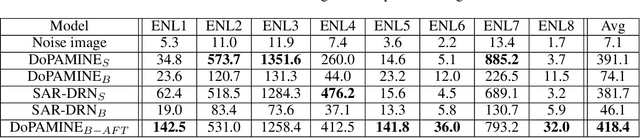
We propose DoPAMINE, a new neural network based multiplicative noise despeckling algorithm. Our algorithm is inspired by Neural AIDE (N-AIDE), which is a recently proposed neural adaptive image denoiser. While the original N-AIDE was designed for the additive noise case, we show that the same framework, i.e., adaptively learning a network for pixel-wise affine denoisers by minimizing an unbiased estimate of MSE, can be applied to the multiplicative noise case as well. Moreover, we derive a double-sided masked CNN architecture which can control the variance of the activation values in each layer and converge fast to high denoising performance during supervised training. In the experimental results, we show our DoPAMINE possesses high adaptivity via fine-tuning the network parameters based on the given noisy image and achieves significantly better despeckling results compared to SAR-DRN, a state-of-the-art CNN-based algorithm.
Fooling Neural Network Interpretations via Adversarial Model Manipulation
Feb 06, 2019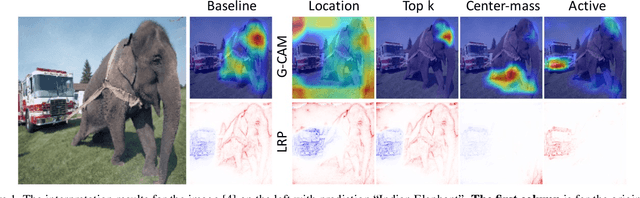
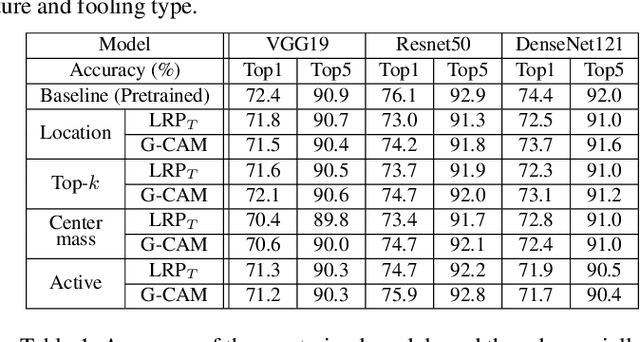
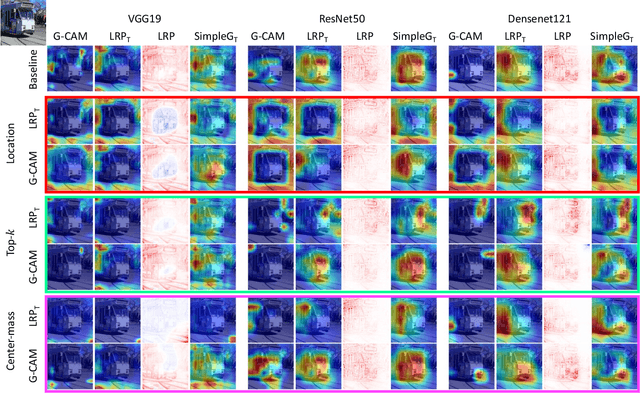

We ask whether the neural network interpretation methods can be fooled via adversarial model manipulation, which is defined as a model fine-tuning step that aims to radically alter the explanations without hurting the accuracy of the original model. By incorporating the interpretation results directly in the regularization term of the objective function for fine-tuning, we show that the state-of-the-art interpreters, e.g., LRP and Grad-CAM, can be easily fooled with our model manipulation. We propose two types of fooling, passive and active, and demonstrate such foolings generalize well to the entire validation set as well as transfer to other interpretation methods. Our results are validated by both visually showing the fooled explanations and reporting quantitative metrics that measure the deviations from the original explanations. We claim that the stability of neural network interpretation method with respect to our adversarial model manipulation is an important criterion to check for developing robust and reliable neural network interpretation method.
Subtask Gated Networks for Non-Intrusive Load Monitoring
Nov 16, 2018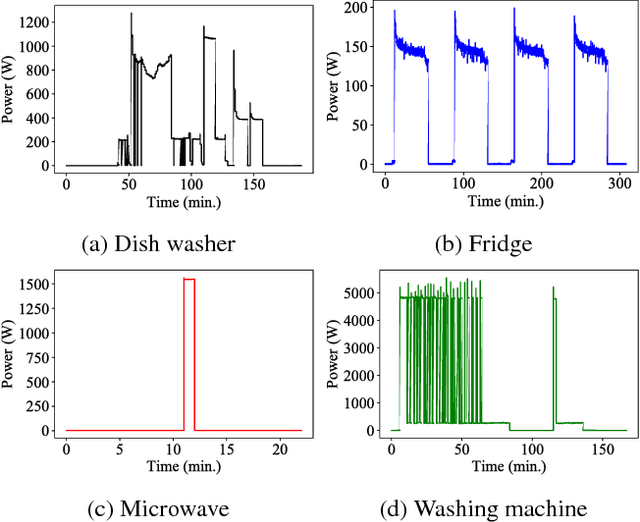
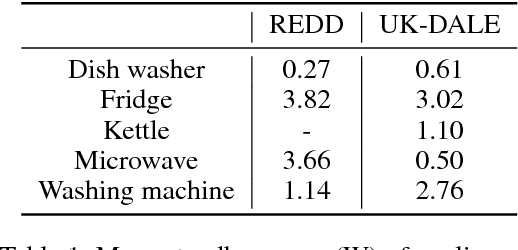
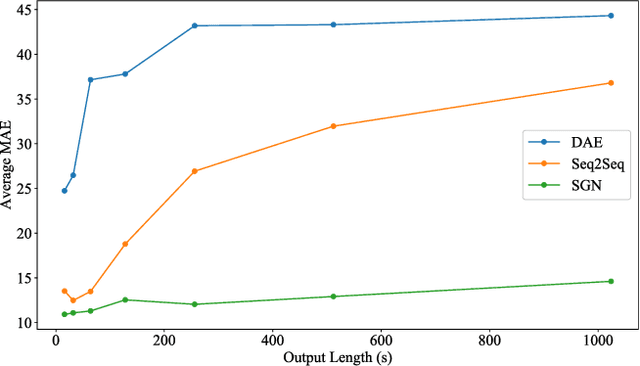

Non-intrusive load monitoring (NILM), also known as energy disaggregation, is a blind source separation problem where a household's aggregate electricity consumption is broken down into electricity usages of individual appliances. In this way, the cost and trouble of installing many measurement devices over numerous household appliances can be avoided, and only one device needs to be installed. The problem has been well-known since Hart's seminal paper in 1992, and recently significant performance improvements have been achieved by adopting deep networks. In this work, we focus on the idea that appliances have on/off states, and develop a deep network for further performance improvements. Specifically, we propose a subtask gated network that combines the main regression network with an on/off classification subtask network. Unlike typical multitask learning algorithms where multiple tasks simply share the network parameters to take advantage of the relevance among tasks, the subtask gated network multiply the main network's regression output with the subtask's classification probability. When standby-power is additionally learned, the proposed solution surpasses the state-of-the-art performance for most of the benchmark cases. The subtask gated network can be very effective for any problem that inherently has on/off states.