 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBenchmarking LLM Causal Reasoning with Scientifically Validated Relationships
Oct 08, 2025Causal reasoning is fundamental for Large Language Models (LLMs) to understand genuine cause-and-effect relationships beyond pattern matching. Existing benchmarks suffer from critical limitations such as reliance on synthetic data and narrow domain coverage. We introduce a novel benchmark constructed from casually identified relationships extracted from top-tier economics and finance journals, drawing on rigorous methodologies including instrumental variables, difference-in-differences, and regression discontinuity designs. Our benchmark comprises 40,379 evaluation items covering five task types across domains such as health, environment, technology, law, and culture. Experimental results on eight state-of-the-art LLMs reveal substantial limitations, with the best model achieving only 57.6\% accuracy. Moreover, model scale does not consistently translate to superior performance, and even advanced reasoning models struggle with fundamental causal relationship identification. These findings underscore a critical gap between current LLM capabilities and demands of reliable causal reasoning in high-stakes applications.
DEAL: Decoupled Classifier with Adaptive Linear Modulation for Group Robust Early Diagnosis of MCI to AD Conversion
Nov 25, 2024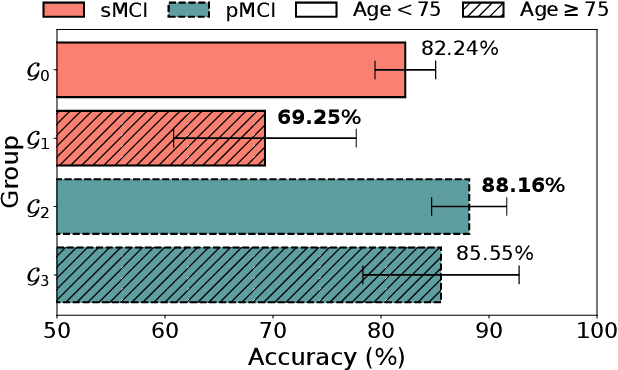


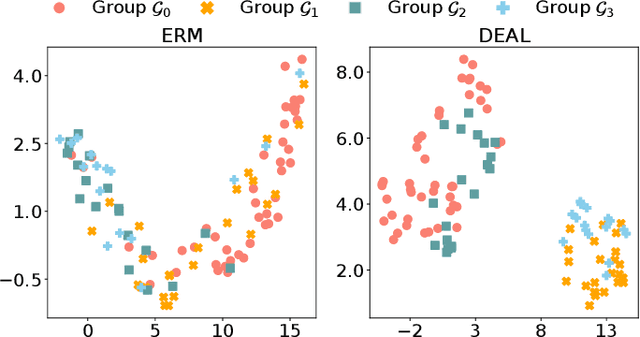
While deep learning-based Alzheimer's disease (AD) diagnosis has recently made significant advancements, particularly in predicting the conversion of mild cognitive impairment (MCI) to AD based on MRI images, there remains a critical gap in research regarding the group robustness of the diagnosis. Although numerous studies pointed out that deep learning-based classifiers may exhibit poor performance in certain groups by relying on unimportant attributes, this issue has been largely overlooked in the early diagnosis of MCI to AD conversion. In this paper, we present the first comprehensive investigation of the group robustness in the early diagnosis of MCI to AD conversion using MRI images, focusing on disparities in accuracy between groups, specifically sMCI and pMCI individuals divided by age. Our experiments reveal that standard classifiers consistently underperform for certain groups across different architectures, highlighting the need for more tailored approaches. To address this, we propose a novel method, dubbed DEAL (DEcoupled classifier with Adaptive Linear modulation), comprising two key components: (1) a linear modulation of features from the penultimate layer, incorporating easily obtainable age and cognitive indicative tabular features, and (2) a decoupled classifier that provides more tailored decision boundaries for each group, further improving performance. Through extensive experiments and evaluations across different architectures, we demonstrate the efficacy of DEAL in improving the group robustness of the MCI to AD conversion prediction.
Spatial-and-Frequency-aware Restoration method for Images based on Diffusion Models
Jan 31, 2024



Diffusion models have recently emerged as a promising framework for Image Restoration (IR), owing to their ability to produce high-quality reconstructions and their compatibility with established methods. Existing methods for solving noisy inverse problems in IR, considers the pixel-wise data-fidelity. In this paper, we propose SaFaRI, a spatial-and-frequency-aware diffusion model for IR with Gaussian noise. Our model encourages images to preserve data-fidelity in both the spatial and frequency domains, resulting in enhanced reconstruction quality. We comprehensively evaluate the performance of our model on a variety of noisy inverse problems, including inpainting, denoising, and super-resolution. Our thorough evaluation demonstrates that SaFaRI achieves state-of-the-art performance on both the ImageNet datasets and FFHQ datasets, outperforming existing zero-shot IR methods in terms of LPIPS and FID metrics.
SwiFT: Swin 4D fMRI Transformer
Jul 12, 2023



The modeling of spatiotemporal brain dynamics from high-dimensional data, such as 4D functional MRI, is a formidable task in neuroscience. To address this challenge, we present SwiFT (Swin 4D fMRI Transformer), a Swin Transformer architecture that can learn brain dynamics directly from 4D functional brain MRI data in a memory and computation-efficient manner. SwiFT achieves this by implementing a 4D window multi-head self-attention mechanism and absolute positional embeddings. We evaluate SwiFT using multiple largest-scale human functional brain imaging datasets in tasks such as predicting sex, age, and cognitive intelligence. Our experimental outcomes reveal that SwiFT consistently outperforms recent state-of-the-art models. To the best of our knowledge, SwiFT is the first Swin Transformer architecture that can process dimensional spatiotemporal brain functional data in an end-to-end fashion. Furthermore, due to the end-to-end learning capability, we also show that contrastive loss-based self-supervised pre-training of SwiFT is also feasible for achieving improved performance on a downstream task. We believe that our work holds substantial potential in facilitating scalable learning of functional brain imaging in neuroscience research by reducing the hurdles associated with applying Transformer models to high-dimensional fMRI.
Continual Learning in the Presence of Spurious Correlation
Mar 21, 2023



Most continual learning (CL) algorithms have focused on tackling the stability-plasticity dilemma, that is, the challenge of preventing the forgetting of previous tasks while learning new ones. However, they have overlooked the impact of the knowledge transfer when the dataset in a certain task is biased - namely, when some unintended spurious correlations of the tasks are learned from the biased dataset. In that case, how would they affect learning future tasks or the knowledge already learned from the past tasks? In this work, we carefully design systematic experiments using one synthetic and two real-world datasets to answer the question from our empirical findings. Specifically, we first show through two-task CL experiments that standard CL methods, which are unaware of dataset bias, can transfer biases from one task to another, both forward and backward, and this transfer is exacerbated depending on whether the CL methods focus on the stability or the plasticity. We then present that the bias transfer also exists and even accumulate in longer sequences of tasks. Finally, we propose a simple, yet strong plug-in method for debiasing-aware continual learning, dubbed as Group-class Balanced Greedy Sampling (BGS). As a result, we show that our BGS can always reduce the bias of a CL model, with a slight loss of CL performance at most.
Fair Feature Distillation for Visual Recognition
Jun 10, 2021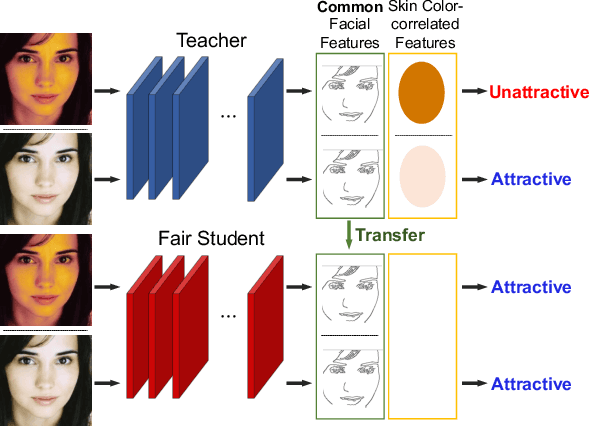
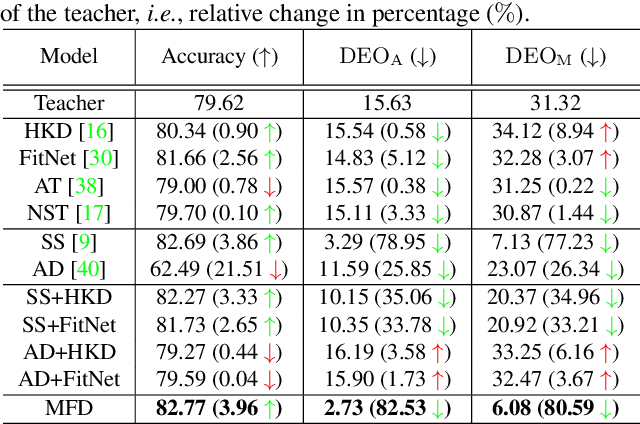
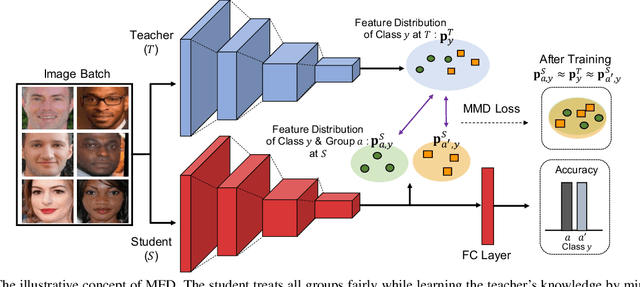
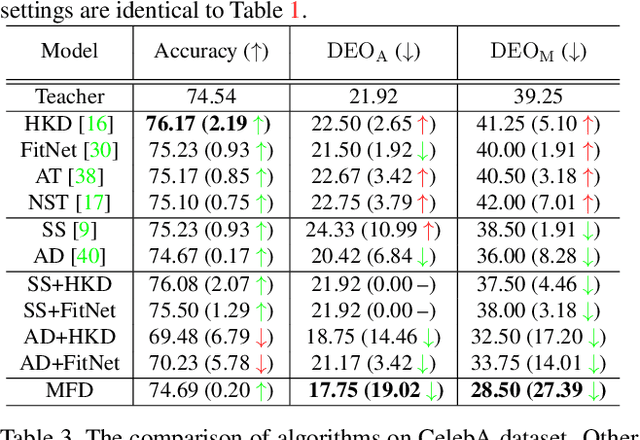
Fairness is becoming an increasingly crucial issue for computer vision, especially in the human-related decision systems. However, achieving algorithmic fairness, which makes a model produce indiscriminative outcomes against protected groups, is still an unresolved problem. In this paper, we devise a systematic approach which reduces algorithmic biases via feature distillation for visual recognition tasks, dubbed as MMD-based Fair Distillation (MFD). While the distillation technique has been widely used in general to improve the prediction accuracy, to the best of our knowledge, there has been no explicit work that also tries to improve fairness via distillation. Furthermore, We give a theoretical justification of our MFD on the effect of knowledge distillation and fairness. Throughout the extensive experiments, we show our MFD significantly mitigates the bias against specific minorities without any loss of the accuracy on both synthetic and real-world face datasets.
Uncertainty-based Continual Learning with Adaptive Regularization
May 28, 2019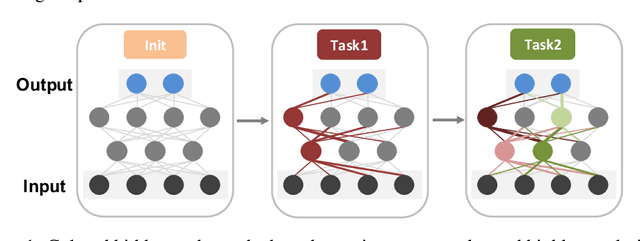

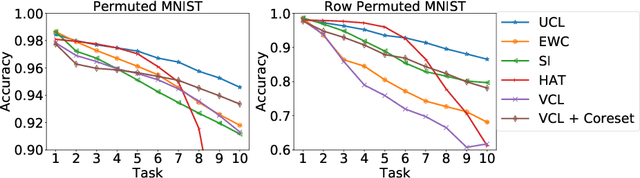

We introduce a new regularization-based continual learning algorithm, dubbed as Uncertainty-regularized Continual Learning (UCL), that stores much smaller number of additional parameters for regularization terms than the recent state-of-the-art methods. Our approach builds upon the Bayesian learning framework, but makes a fresh interpretation of the variational approximation based regularization term and defines a notion of "uncertainty" for each hidden node in the network. The regularization parameter of each weight is then set to be large when the uncertainty of either of the node that the weight connects is small, since the weights connected to an important node should be less updated when a new task comes. Moreover, we add two additional regularization terms; one that promotes freezing the weights that are identified to be important (i.e., certain) for past tasks, and the other that gives flexibility to control the actively learning parameters for a new task by gracefully forgetting what was learned before. In results, we show our UCL outperforms most of recent state-of-the-art baselines on both supervised learning and reinforcement learning benchmarks.