 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAction-Sufficient Goal Representations
Jan 30, 2026Hierarchical policies in offline goal-conditioned reinforcement learning (GCRL) addresses long-horizon tasks by decomposing control into high-level subgoal planning and low-level action execution. A critical design choice in such architectures is the goal representation-the compressed encoding of goals that serves as the interface between these levels. Existing approaches commonly derive goal representations while learning value functions, implicitly assuming that preserving information sufficient for value estimation is adequate for optimal control. We show that this assumption can fail, even when the value estimation is exact, as such representations may collapse goal states that need to be differentiated for action learning. To address this, we introduce an information-theoretic framework that defines action sufficiency, a condition on goal representations necessary for optimal action selection. We prove that value sufficiency does not imply action sufficiency and empirically verify that the latter is more strongly associated with control success in a discrete environment. We further demonstrate that standard log-loss training of low-level policies naturally induces action-sufficient representations. Our experimental results a popular benchmark demonstrate that our actor-derived representations consistently outperform representations learned via value estimation.
Option-aware Temporally Abstracted Value for Offline Goal-Conditioned Reinforcement Learning
May 19, 2025Offline goal-conditioned reinforcement learning (GCRL) offers a practical learning paradigm where goal-reaching policies are trained from abundant unlabeled (reward-free) datasets without additional environment interaction. However, offline GCRL still struggles with long-horizon tasks, even with recent advances that employ hierarchical policy structures, such as HIQL. By identifying the root cause of this challenge, we observe the following insights: First, performance bottlenecks mainly stem from the high-level policy's inability to generate appropriate subgoals. Second, when learning the high-level policy in the long-horizon regime, the sign of the advantage signal frequently becomes incorrect. Thus, we argue that improving the value function to produce a clear advantage signal for learning the high-level policy is essential. In this paper, we propose a simple yet effective solution: Option-aware Temporally Abstracted value learning, dubbed OTA, which incorporates temporal abstraction into the temporal-difference learning process. By modifying the value update to be option-aware, the proposed learning scheme contracts the effective horizon length, enabling better advantage estimates even in long-horizon regimes. We experimentally show that the high-level policy extracted using the OTA value function achieves strong performance on complex tasks from OGBench, a recently proposed offline GCRL benchmark, including maze navigation and visual robotic manipulation environments.
Listwise Reward Estimation for Offline Preference-based Reinforcement Learning
Aug 08, 2024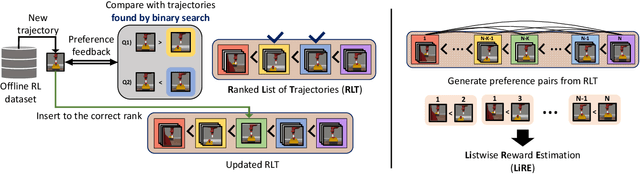

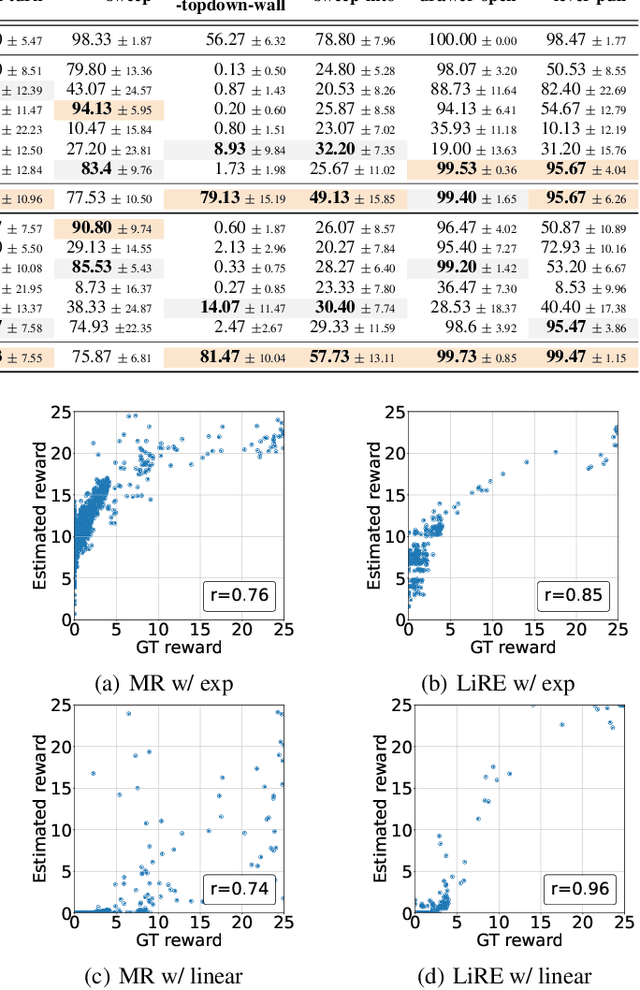
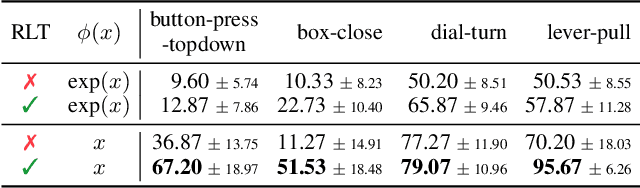
In Reinforcement Learning (RL), designing precise reward functions remains to be a challenge, particularly when aligning with human intent. Preference-based RL (PbRL) was introduced to address this problem by learning reward models from human feedback. However, existing PbRL methods have limitations as they often overlook the second-order preference that indicates the relative strength of preference. In this paper, we propose Listwise Reward Estimation (LiRE), a novel approach for offline PbRL that leverages second-order preference information by constructing a Ranked List of Trajectories (RLT), which can be efficiently built by using the same ternary feedback type as traditional methods. To validate the effectiveness of LiRE, we propose a new offline PbRL dataset that objectively reflects the effect of the estimated rewards. Our extensive experiments on the dataset demonstrate the superiority of LiRE, i.e., outperforming state-of-the-art baselines even with modest feedback budgets and enjoying robustness with respect to the number of feedbacks and feedback noise. Our code is available at https://github.com/chwoong/LiRE
Reset & Distill: A Recipe for Overcoming Negative Transfer in Continual Reinforcement Learning
Mar 08, 2024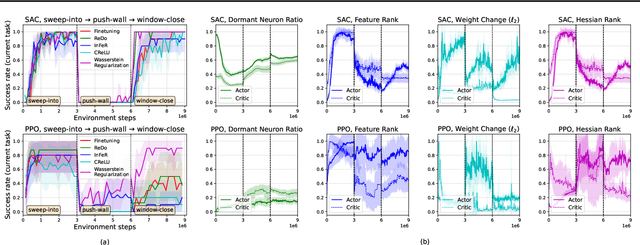
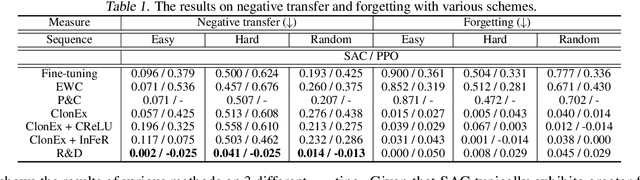
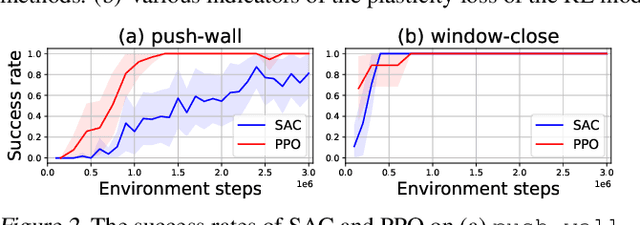
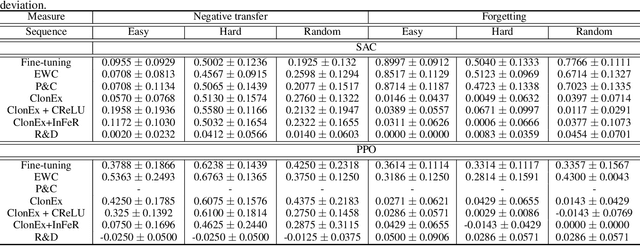
We argue that one of the main obstacles for developing effective Continual Reinforcement Learning (CRL) algorithms is the negative transfer issue occurring when the new task to learn arrives. Through comprehensive experimental validation, we demonstrate that such issue frequently exists in CRL and cannot be effectively addressed by several recent work on mitigating plasticity loss of RL agents. To that end, we develop Reset & Distill (R&D), a simple yet highly effective method, to overcome the negative transfer problem in CRL. R&D combines a strategy of resetting the agent's online actor and critic networks to learn a new task and an offline learning step for distilling the knowledge from the online actor and previous expert's action probabilities. We carried out extensive experiments on long sequence of Meta-World tasks and show that our method consistently outperforms recent baselines, achieving significantly higher success rates across a range of tasks. Our findings highlight the importance of considering negative transfer in CRL and emphasize the need for robust strategies like R&D to mitigate its detrimental effects.
Descent Steps of a Relation-Aware Energy Produce Heterogeneous Graph Neural Networks
Jun 24, 2022

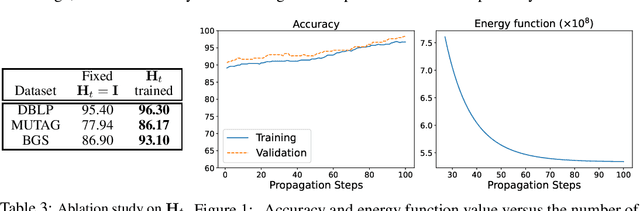
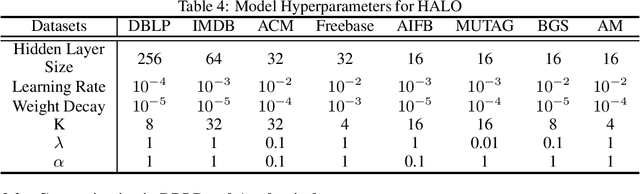
Heterogeneous graph neural networks (GNNs) achieve strong performance on node classification tasks in a semi-supervised learning setting. However, as in the simpler homogeneous GNN case, message-passing-based heterogeneous GNNs may struggle to balance between resisting the oversmoothing occuring in deep models and capturing long-range dependencies graph structured data. Moreover, the complexity of this trade-off is compounded in the heterogeneous graph case due to the disparate heterophily relationships between nodes of different types. To address these issues, we proposed a novel heterogeneous GNN architecture in which layers are derived from optimization steps that descend a novel relation-aware energy function. The corresponding minimizer is fully differentiable with respect to the energy function parameters, such that bilevel optimization can be applied to effectively learn a functional form whose minimum provides optimal node representations for subsequent classification tasks. In particular, this methodology allows us to model diverse heterophily relationships between different node types while avoiding oversmoothing effects. Experimental results on 8 heterogeneous graph benchmarks demonstrates that our proposed method can achieve competitive node classification accuracy.
A Simple Class Decision Balancing for Incremental Learning
Mar 31, 2020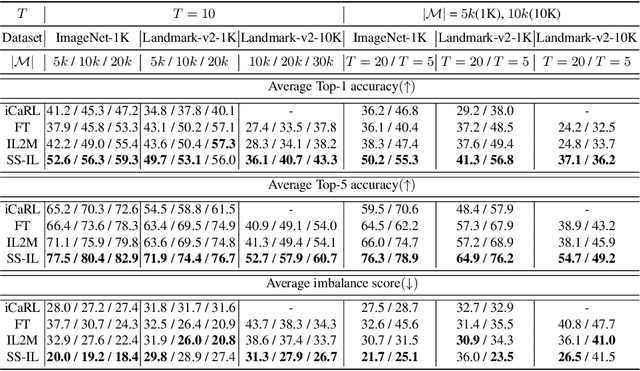
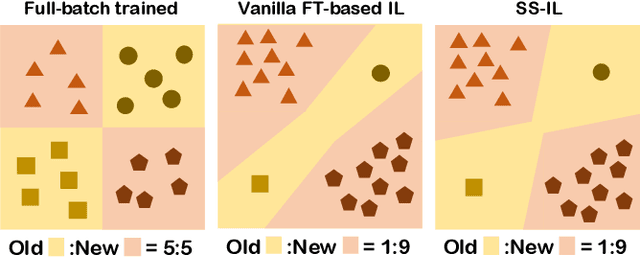
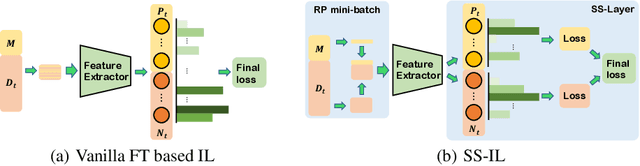
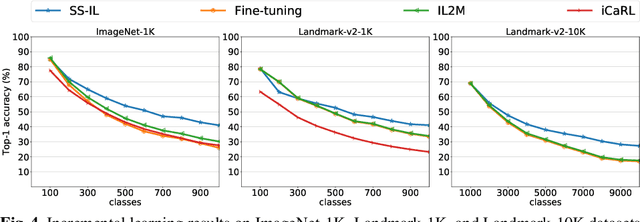
Class incremental learning (CIL) problem, in which a learning agent continuously learns new classes from incrementally arriving training data batches, has gained much attention recently in AI and computer vision community due to both fundamental and practical perspectives of the problem. For mitigating the main difficulty of deep neural network(DNN)-based CIL, the catastrophic forgetting, recent work showed that a simple fine-tuning (FT) based schemes can outperform the earlier attempts of using knowledge distillation, particularly when a small-sized exemplar-memory for storing samples from the previously learned classes is allowed. The core limitation of the vanilla FT, however, is the severe classification score bias between the new and previously learned classes, and several state-of-the-art methods proposed to rectify the bias via additional post-processing of the scores. In this paper, we propose two simple modifications for the vanilla FT, separated softmax (SS) layer and ratio-preserving (RP) mini-batches for SGD updates. Our scheme, dubbed as SS-IL, is shown to give much more balanced class decisions, have much less biased scores, and outperform strong state-of-the-art baselines on several large-scale benchmark datasets, without any sophisticated post-processing of the scores. We also give several novel analyses our and baseline methods, confirming the effectiveness of our approach in CIL.
Adaptive Group Sparse Regularization for Continual Learning
Mar 30, 2020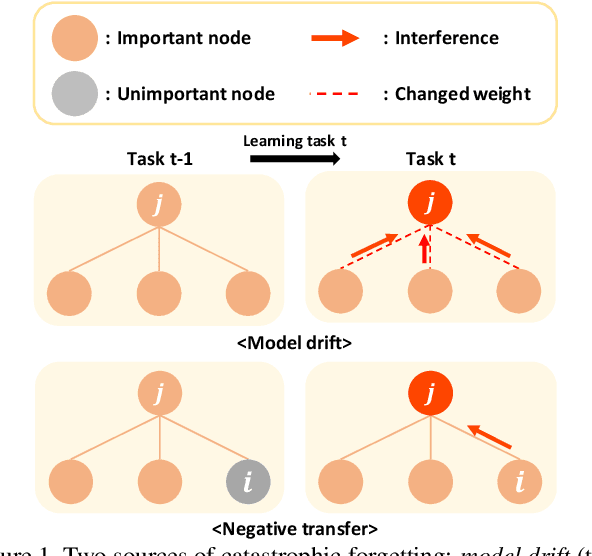
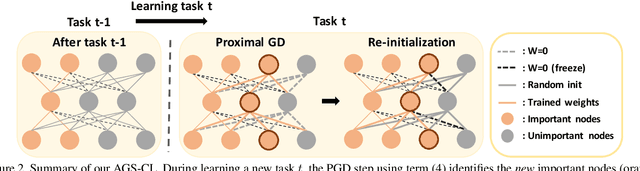
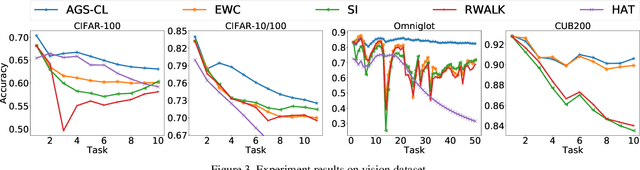
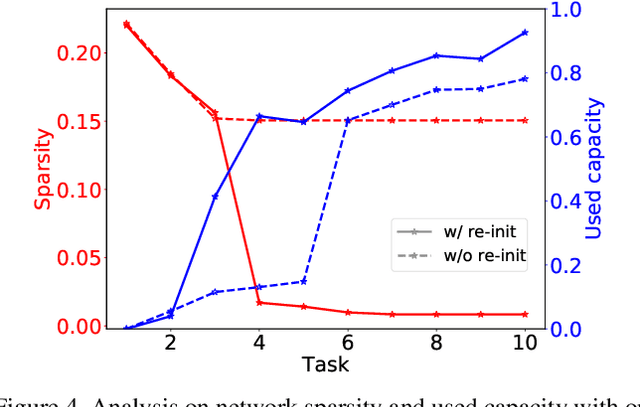
We propose a novel regularization-based continual learning method, dubbed as Adaptive Group Sparsity based Continual Learning (AGS-CL), using two group sparsity-based penalties. Our method selectively employs the two penalties when learning each node based its the importance, which is adaptively updated after learning each new task. By utilizing the proximal gradient descent method for learning, the exact sparsity and freezing of the model is guaranteed, and thus, the learner can explicitly control the model capacity as the learning continues. Furthermore, as a critical detail, we re-initialize the weights associated with unimportant nodes after learning each task in order to prevent the negative transfer that causes the catastrophic forgetting and facilitate efficient learning of new tasks. Throughout the extensive experimental results, we show that our AGS-CL uses much less additional memory space for storing the regularization parameters, and it significantly outperforms several state-of-the-art baselines on representative continual learning benchmarks for both supervised and reinforcement learning tasks.
Uncertainty-based Continual Learning with Adaptive Regularization
May 28, 2019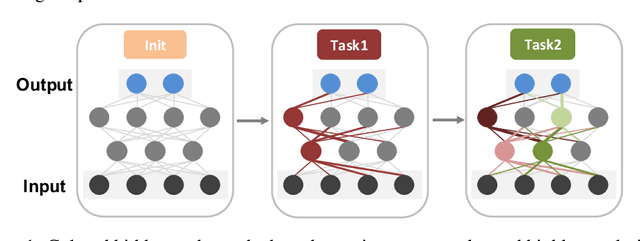

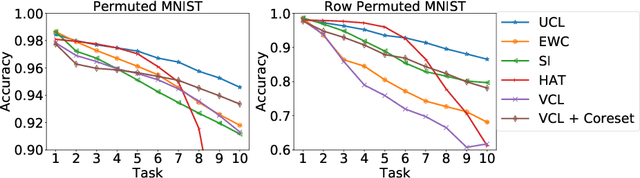

We introduce a new regularization-based continual learning algorithm, dubbed as Uncertainty-regularized Continual Learning (UCL), that stores much smaller number of additional parameters for regularization terms than the recent state-of-the-art methods. Our approach builds upon the Bayesian learning framework, but makes a fresh interpretation of the variational approximation based regularization term and defines a notion of "uncertainty" for each hidden node in the network. The regularization parameter of each weight is then set to be large when the uncertainty of either of the node that the weight connects is small, since the weights connected to an important node should be less updated when a new task comes. Moreover, we add two additional regularization terms; one that promotes freezing the weights that are identified to be important (i.e., certain) for past tasks, and the other that gives flexibility to control the actively learning parameters for a new task by gracefully forgetting what was learned before. In results, we show our UCL outperforms most of recent state-of-the-art baselines on both supervised learning and reinforcement learning benchmarks.
Iterative Channel Estimation for Discrete Denoising under Channel Uncertainty
Feb 24, 2019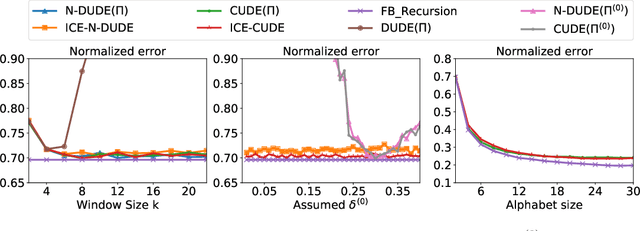
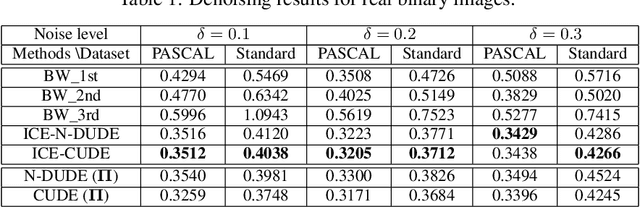
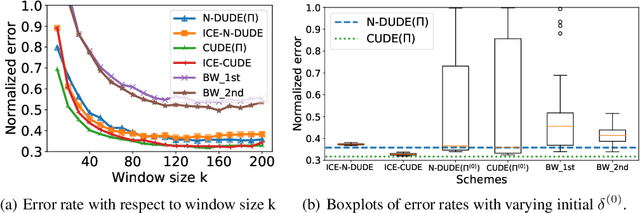
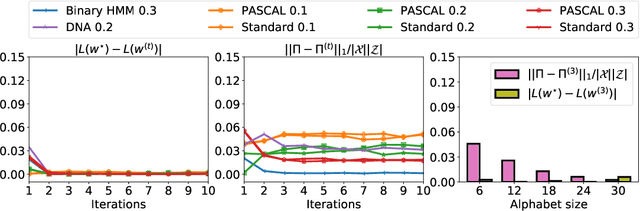
We propose a novel iterative channel estimation (ICE) algorithm that essentially removes the critical known noisy channel assumption for universal discrete denoising problem. Our algorithm is based on Neural DUDE (N-DUDE), a recently proposed neural network-based discrete denoiser, and it estimates the channel transition matrix as well as the neural network parameters in an alternating manner until convergence. While we do not make any probabilistic assumption on the underlying clean data, our ICE resembles Expectation-Maximization (EM) with variational approximation, and it takes advantage of the property of N-DUDE being locally robust around the true channel. With extensive experiments on several radically different types of data, we show that the ICE equipped N-DUDE (dubbed as ICE-N-DUDE) can perform \emph{universally} well regardless of the uncertainties in both the channel and the clean source. Moreover, we show ICE-N-DUDE becomes extremely robust to its hyperparameters and significantly outperforms the strong baseline that can deal with the channel uncertainties for denoising, the widely used Baum-Welch (BW) algorithm for hidden Markov models (HMM).